
Détails du traitement NLP dans les réponses d'API
Détails du traitement NLP
Les détails de l'analyse du traitement du langage naturel (NLP) de la requête de recherche en cours sont disponibles dans la section sur les métadonnées de la réponse de l'API de recherche. Ces métadonnées sont générées après que toute logique de suppression de terme de recherche applicable a été appliquée à la requête. En plus de ces détails dans les métadonnées, la requête Elasticsearch finale est fournie. Ces détails sont renvoyés lorsque vous utilisez le paramètre de requête esQueryWithGrouping. Ce paramètre renvoie la requête de regroupement si le regroupement est activé. esQueryWithoutGrouping renvoie la requête sans regroupement si le regroupement est désactivé.
- Quel était le terme de recherche
- Détails de la correction orthographique
- Termes exclus
- Elargissement aux synonymes ou remplacements effectués pour n'importe quel mot clé
- Filtres de prix
- Partie de l'étiquetage vocal/Reconnaissance d'entité de nom
- Filtre de couleur
L'exemple suivant suppose que vous avez des synonymes et une configuration de remplacement comme suit.
{ "chair => sofa": "", "sofa, couch": "" } Supposons qu'une recherche soit effectuée à l'aide de la chaîne chèse de style rouge de moins de 500 $, où le mot clé chair est mal orthographié, avec cheir. La liste nlpParsing inclut deux objets JSON, qui montrent que lors de la première itération, la requête a renvoyé zéro résultat. Dans l'itération suivante, le service Query applique la logique de suppression de termes de recherche en fonction de la priorité de suppression définie dans le profil NLP. Le second objet JSON de la liste d'analyse syntaxique contient le résultat de l'analyse syntaxique avec cette logique appliquée. Si cela échoue, le processus se poursuit jusqu'à ce qu'un résultat soit renvoyé ou qu'il n'y ait pas de résultat. Dans ce cas, cheir correspond à chair. La liste nlpParsing est remplie à chaque itération. Lors de l'analyse syntaxique NLP, chaque jeton reçoit une classification de mappe. Lorsque l'association de termes de recherche (STA) est appliquée, chair est remplacé par sofa, puis sofa est développé avec sofa OR couch, under $50 est analysé en tant que filtre de prix et [LTE:50] est considéré comme inférieur ou égal à 50 $.
Le contenu complet de nlpParsing est affiché dans la capture d'écran ci-dessous.
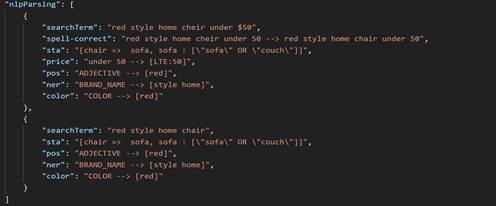
chair sera classé comme CATEGORIE.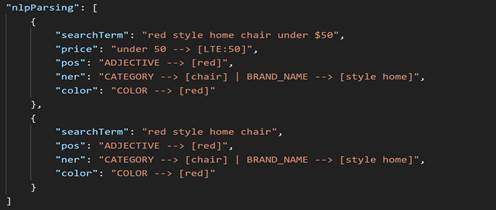
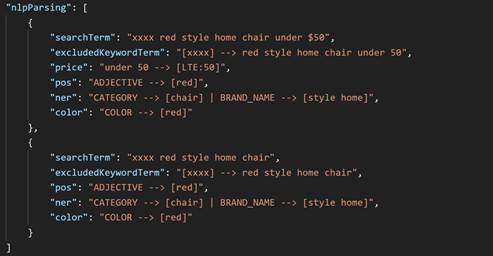
xxxx. Ce paramètre est transmis en tant que terme exclu.
Dans toutes les images de capture d'écran ci-dessus, le texte rouge est mappé sur la section ADJECTIF (pos), ainsi que sur COULEUR. Dans ce cas, la couleur est d'abord analysée comme adjectif. Dans l'étape ultérieure du traitement NLP, tous les adjectifs de la liste d'adjectifs sont examinés et les noms de couleur sont extraits et envoyés au filtre de couleur.
Si vous souhaitez que la requête Elasticsearch générée dans la réponse, à des fins d'identification et de résolution des problèmes, transmettez le paramètre esQueryWithGrouping= ou trueesQueryWithoutGrouping= dans la requête d'API de recherche de terme. La requête est renvoyée dans la section de métadonnées de la réponse d'API. Cette requête est générée en fonction de la dernière itération du cycle d'analyse de NLP.true

Améliorer les termes de recherche dans Basic NLP
Lors de l'amélioration des termes de recherche de types NOUN, CATEGORY et BRAND_NAME, des informations sur l'amélioration peuvent être incluses dans la réponse de recherche au sein du nœud metaData.nlpParsing. Ce facteur d'amélioration est personnalisable.
pos et ner sont ajoutées aux deux termes de recherche avec un facteur d'amélioration de 100,0. Les informations ne font qu'ajouter à la réponse de recherche et le processus global d'amélioration reste inchangé. Avant d'être amélioré, il est défini comme :{ "metaData": { "price": "1", "nlpParsing": [ { "searchTerm": "Stonehenge gifts" } ] } ... }{ "metaData": { "price": "1", "nlpParsing": [ { "searchTerm": "Stonehenge gifts", "pos": "NOUN --> [bath~bathing] (boosted by 100.0)", "ner": "BRAND_NAME --> [stonehenge] (boosted by 100.0)" } ] } ... }