Journalisation et identification et résolution des incidents des services Ingest et Query
Les approches et les systèmes d'identification et de résolution des incidents de vos services Ingest et Query sont abordés.
Identification et résolution des incidents Ingest
Lorsque vous vérifiez le service Ingest, la première chose à faire est de vérifier le pipeline de données, afin de vous assurer que vos données sont effectivement intégrées dans Elasticsearch. Vérifiez les connecteurs dans les conteneurs de profils. Chaque étape de démarrage (ainsi que d'arrêt) du service est enregistrée automatiquement dans ces fichiers. Les fichiers journaux de service Ingest se trouvent dans profile/logs/container/ingest.
Lorsque vous exécutez les pipelines NiFi, chaque pipeline enregistre runId pendant l'exécution. Plutôt que d'avoir à effectuer une recherche dans ces journaux, vous pouvez utiliser l'API REST du service Ingest pour interroger le service afin d'obtenir des codes de retour et d'autres informations d'exécution. Pour obtenir runId (ainsi que d'autres informations d'exécution), il convient d'utiliser la commande /connectors/{connectorId}/runs. Le pipeline runId peut être utilisé comme entrée pour d'autres requêtes, si le pipeline particulier a échoué par exemple.
- Descripteurs : GET /connectors. Ces informations, issues de ZooKeeper, vous montreront l'état de configuration de tous les connecteurs.
- Récapitulatif : GET /connectors{id}/runs
- Débit de suivi : GET connectors{id}runs/{id} avec suivi, journal, récapitulatif
Identification et résolution des incidents du service Query
<DefaultThreshold>TRACE</DefaultThreshold>(Le paramètre par défaut est ERROR.) Lorsque vous redémarrez l'application, la journalisation est activée et le journal Query est écrit sur /app/ESQueryService/logs.
 logback.xml inclut un élément de configuration :
logback.xml inclut un élément de configuration : <configuration scan="true" scanPeriod="30 seconds">{}{} permettant de modifier dynamiquement les paramètres de trace. Toute modification apportée au fichier sera lue toutes les 30 secondes, évitant ainsi de redémarrer l'application.
Le journal contient une grande quantité d'informations. Les entrées pertinentes à Query commencent après la chaîne de texte "Rechercher dans le cache de requête pour l'interrogation de requête". Cette chaîne précède chaque requête envoyée à Elasticsearch et représente le point où la requête interagit avec le moteur Elasticsearch. Tout ce qui précède cette chaîne est un prétraitement des informations ; ce qui suit la ligne est un post-traitement des données.
Traçage au niveau de la requête pour le service Query
- Modifier dynamiquement les niveaux de journal sans avoir à redémarrer le conteneur de service Query en ajoutant un en-tête
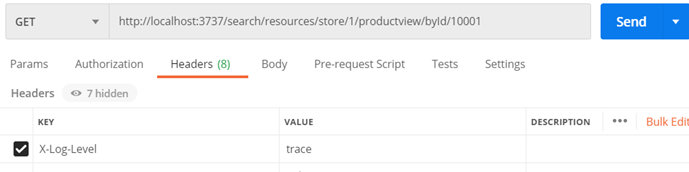
X-Log-Level. - Tracer uniquement pour la demande unique en ajoutant un en-tête
X-Log-Level.
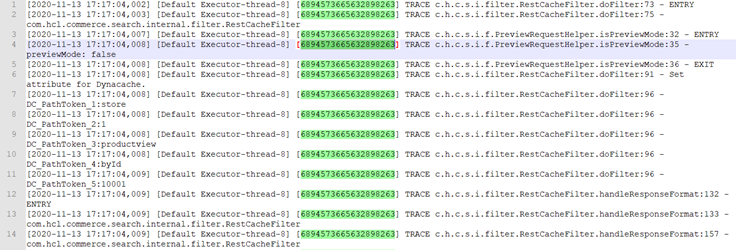
Dans un système de journalisation centralisé, les journaux de plusieurs conteneurs sont vidés dans un index Elasticsearch. Etant donné que l'index a les journaux de tous les conteneurs qui se mélangent les uns aux autres, il doit y avoir un moyen de tirer les enregistrements de journal pertinents de l'index. Le paramètre traceId a été introduit pour résoudre ce problème. Il accompagne chaque enregistrement de journal et vous permet d'obtenir les enregistrements de journal pertinents pour la requête spécifique.
Par défaut, les journaux du service Query sont générés au niveau du journal ERROR. Vous pouvez désormais passer à n'importe quel niveau de journalisation pour une demande particulière en ajoutant l'en-tête X-Log-Level = <log-level>.
<log-level> possibles sont TRACE, DEBUG, INFO, WARN, ERROR.
Utilisez l’interface Swagger de l'API REST Query pour accéder au point de terminaison du service de requête suivant. Ce nœud final active le traçage au niveau de l'API pour le service Query.
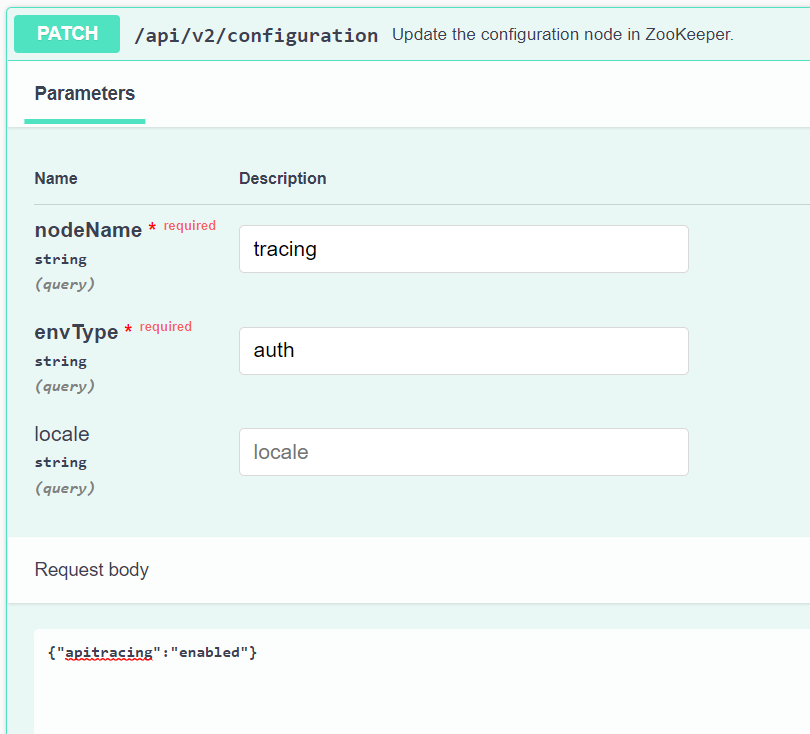 Assurez-vous d'inclure le paramètre envType obligatoire et
Assurez-vous d'inclure le paramètre envType obligatoire et {"apitracing":"enabled"} dans le corps du message.
Vous pouvez également utiliser la commande Curl suivante pour activer le traçage au niveau de l'API pour le service Query :
"https://<query_host>:<query_port>/search/resources/api/v2/configuration?nodeName=tracing&envType=auth" -H "accept: application/json" -H "Content-Type: application/json" -d "{\"apitracing\":\"enabled\"}"Instructions de journal dans trace.log ayant le traceId unique par rapport à la requête spécifique.
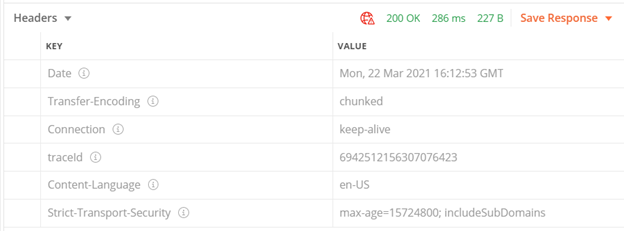
La réponse a un en-tête traceId qui transporte le traceId vers l'appelant.
Activation de la trace sur le serveur d'ingestion
./opt/WebSphere/Liberty/usr/servers/default/apps/search-ingest.ear/search-ingest.war/WEB-INF/classes/log4j2-spring.xml<Loggers> ............ ............ <Logger name="com.hcl" level="ALL"/> <Root level="trace"> <AppenderRef ref="Console"></AppenderRef> <AppenderRef ref="RollingFileAppender"></AppenderRef> </Root> </Loggers>Après avoir effectué cette modification, vous devrez redémarrer le serveur d'ingestion.