Réglage des performances du service Ingest
Vous pouvez régler les performances de recherche au moment de l'ingestion des données en réglant vos paramètres NiFi, ou au moment de l'exécution en modifiant les options de mémoire pour Elasticsearch.
Réglage d'Apache NiFi
Pour maximiser les performances, NiFi divise les données entrantes à l'aide d'une approche de mise en cluster sans maître. Les données sont divisées en morceaux et chaque nœud du cluster effectue la même opération sur le morceau qu'il reçoit. ZooKeeper élit un nœud en tant que coordinateur de cluster, et tous les autres nœuds lui envoient des données de pulsation. Le coordinateur est responsable de la déconnexion des nœuds qui ne se présentent pas à temps, ou de la connexion de nouveaux nœuds qui prouvent qu'ils ont la même configuration que les autres nœuds du cluster.
| Paramètre | Description | Par défaut | Range/options |
|---|---|---|---|
| Mémoire (paramètre de fichier Bootstrap.conf) | |||
| mémoire de la machine virtuelle Java | Mémoire de segment de mémoire minimale et maximale. Remarque : un très grand segment de mémoire peut ralentir la récupération de place. | 512mb | Définissez ce paramètre sur 4 à 8 Go, par exemple :
|
| Outil de récupération de place : XX:+UseG1GC | Java 8 rencontre des problèmes lors de l'utilisation de l'implémentation writeAheadProvenance recommandée introduite dans Apache NIFi 1.2.0 (HDF 3.0.0). |
||
| Java 8 ou ultérieur (paramètres de fichier nifi.properties) | |||
| XX:ReservedCodeCacheSize | NiFi stocke ses données sur disque tout en les traitant. Dans des conditions de débit élevé, les paramètres CodeCache par défaut peuvent s'avérer inadéquats. | Varie selon la version Java ; peut être aussi bas que 32 Mo | 256 Mo |
| XX:CodeCacheMinimumFreeSpace | Supprimez la mise en commentaire dans nifi.properties à utiliser. | 10 Mo | |
| XX:+UseCodeCacheFlushing | Définit le seuil de vidage du cache. | ||
| Stockage de systèmes de fichiers pour les référentiels internes NiFi | |||
| Fichier de flux | |||
| Base de données | |||
| Contenu | |||
| Provenance | |||
| Réglage (par nœud NiFi) | |||
| Forums | Nombre d'unités d'exécution pour les unités d'exécution commandées par minuterie. N'utilisez pas d'unités d'exécution axées sur les événements. | 2 à 4 fois le nombre de noyaux sur l'hôte | |
Réglage de Elasticsearch
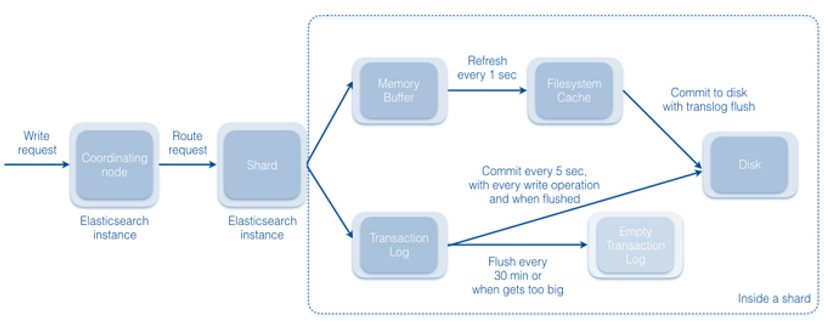
Elasticsearch utilise la même approche de mise en cluster sans maître que NiFi. Le nœud de coordination reçoit des demandes d'écriture et attribue des demandes de routage à d'autres instances de cluster (fragments). Par défaut, chaque fragment actualise son cache de système de fichiers une fois par seconde et valide toutes les cinq secondes. Le fragment conserve un journal des transactions et vide le journal toutes les trente minutes.
Dans la phase de requête du processus de recherche, le nœud de coordination prend les recherches entrantes et les envoie à tous les fragments. Chaque fragment effectue sa propre recherche, localement. Le fragment priorise les résultats et renvoie des informations sur les cinquante premiers documents au nœud de coordination. Dans la phase de récupération, le nœud de coordination détermine les dix premiers documents de la liste de chaque fragment et demande à chaque fragment de lui envoyer ces documents.
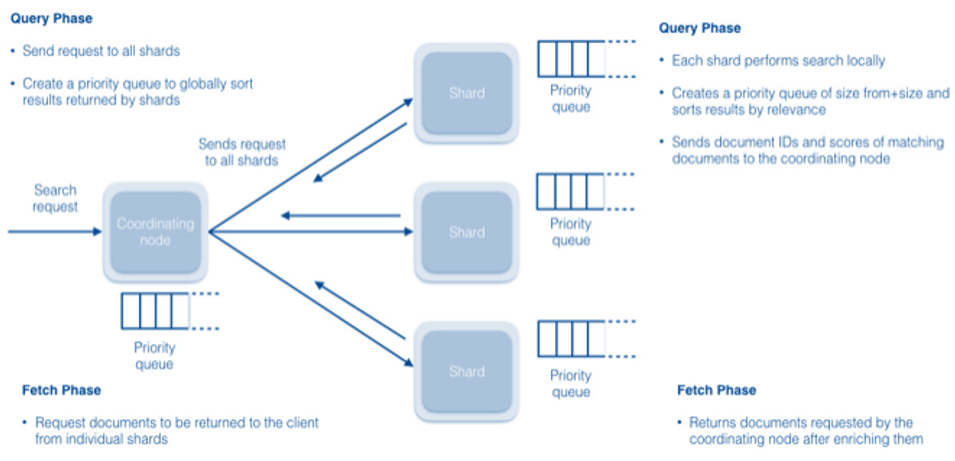
La phase de requête prend généralement beaucoup plus de temps que la phase de récupération car, pendant la requête, les fragments doivent faire correspondre la recherche à une liste potentiellement longue de documents, et déterminer un score pour chacun d'eux. En revanche, la récupération peut s'exécuter rapidement, car le serveur de coordination demande un sous-ensemble des documents à l'aide d'adresses directes.
Le principal moyen d'améliorer les performances de la recherche élastique est d'augmenter l'intervalle d'actualisation. Lorsque vous faites cela, Elasticsearch crée un nouveau segment Lucene et le fusionne plus tard, ce qui augmente le nombre total de segments. En outre, évitez d'échanger si possible. Définissez bootstrap.memory_lock=true pour faciliter cela.
Ajustez les paramètres spécifiques suivants pour optimiser l'environnement de travail Elasticsearch.
| Paramètre | Description | Par défaut | Range/options |
|---|---|---|---|
| Mémoire | |||
| Segment de mémoire JVM | Mémoire de segment de mémoire minimale et maximale. |
|
|
| Outil de récupération de place | XX:+UseG1GC | Utilisez l'outil principal de récupération de place Java 8 pour les segments de mémoire dont la taille est inférieure à 4 Go. | |
| Taille de la mémoire tampon d'index | 10 % de la taille du segment de mémoire. | ||
| Cache du système de fichiers |
|
50 % de la taille de la mémoire Elasticsearch | |
| Cache LRU | |||
| Cache de requête de nœud | A définir avec le paramètre indexs.queries.cache.size | 10 % de la taille du segment de mémoire | |
| Cache de requête Shar | Utilisé pour l'agrégation | ||
| Cache de données de zone | A définir avec le paramètre indexs.fielddata.cache.size | Limité à 30 % de la taille du segment de mémoire | |
| Paramètres généraux | |||
| Pool d'unités d'exécution | generic, index, get, bulk |
||