Utilisation du service HCL Commerce Search
Avec la version 9.1, HCL Commerce présente un nouveau service pour la saisie et l'organisation de vos données. Cette nouvelle version de HCL Commerce Search est un système générique de gestion des données qui peut être utilisé par d'autres sous-systèmes de Commerce, y compris, mais sans s'y limiter, le moteur Elasticsearch. Outre le service Ingest qui intègre des données, le nouveau service Query permet le traitement du langage naturel, la reconnaissance des couleurs et bien plus encore. Pour les clients qui ont besoin d'une rétrocompatibilité, la solution de recherche précédente basée sur Apache Solr est toujours disponible.
Le service HCL Commerce Search introduit dans la version 9.1 offre une mise à l'échelle améliorée, une administration plus simple et une sécurité renforcée. Cette architecture inclut Elasticsearch comme microservice de recherche préféré de la version 9.1. HCL Commerce Le système de recherche de la version 9.1 est rétrocompatible avec celui présent dans la version 9.0. L'API de recherche reste la même, que vous utilisiez Solr ou Elasticsearch. De ce fait, la plupart des implémentations seront en mesure de passer à Elasticsearch sans qu'il n'y ait d'impact sur la vitrine. Si vous avez déjà personnalisé la configuration ou les modèles d'indexation, ou l'exécution de la recherche, il se peut que vous deviez migrer vos personnalisations.
- Traitement du langage naturel (NLP) avec Stanford CoreNLP. Le système NLP améliore la pertinence de la recherche, avec des modèles fournis pour l'anglais, l'espagnol, le français, l'allemand, l'arabe et le chinois.
- La plupart des modèles de langage CoreNLP sont capables d'effectuer la segmentation, l'application de la grammaire, le balisage des catégories grammaticales, la reconnaissance des noms et des entités, du fractionnement des phrases et de l'analyse des sentiments. Ils peuvent effectuer une analyse grammaticale avec la circonscription, l'analyse de dépendance et la coréférence.
- Un processeur NLP supplémentaire a été ajouté pour fournir des fonctionnalités de mise en correspondance supplémentaires, telles que la recherche de couleurs ou de mesures similaires, et la conversion automatique de mesure.
- Entièrement intégré à Elasticsearch comme technologie de recherche de base par défaut.
- Prise en charge multilingue améliorée avec plus de 30 analyseurs linguistiques intégrés pour l'analyse de texte tels que la segmentation, les radicaux, les mots neutres.
- Les fragments d'index permettent d'ajouter dynamiquement plus de nœuds et de rééquilibrer automatiquement les données dans le cluster sans aucun temps d'arrêt.
- Echange à chaud d'index nouvellement générés à l'aide d'alias d'index. La réindexation a un impact minimal sur votre cluster d'index actif.
- Instantanés incrémentiels rapides, qui vous permettent de sauvegarder à intervalles fréquents.
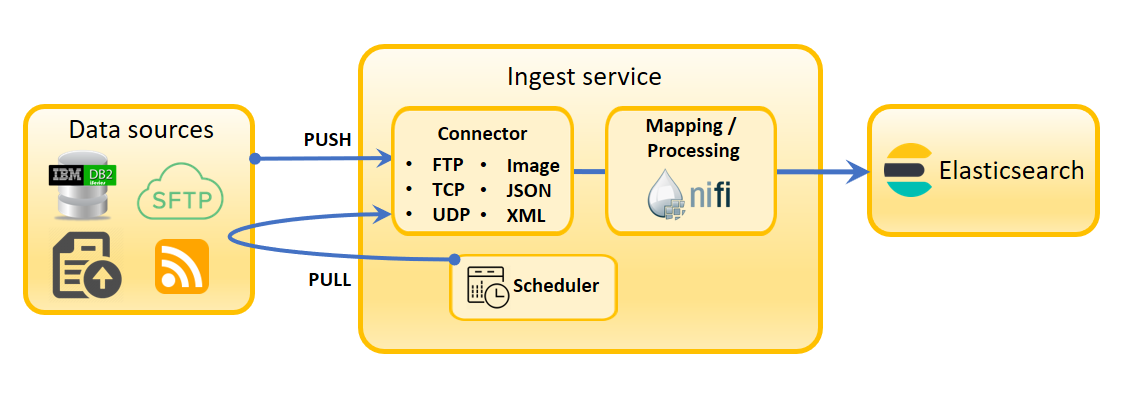
- Ingestion de données via l'indexation des pipelines dans Apache NiFi.
- LeLe service HCL Commerce Search prend entièrement en charge le marketing à plusieurs niveaux et propose des mises à jour en temps quasi réel.
- Interface de déploiement compatible avec Kubernetes.
- Mise à niveau de service transparente et contrôle des versions. La mise à niveau transparente du conteneur de services permet de fournir en continu de nouvelles fonctions et de nouveaux correctifs de bogues via des modules de mise à jour récurrents.
La pile de conteneurs Docker qui exécute les microservices est hébergée sur UBI8 et utilise le framework Spring Boot.
Le diagramme suivant montre l'architecture de HCL Commerce Search. Les microservices de la boîte principale se trouvaient à l'intérieur du conteneur de recherche monolithique de la version 9.0. Ces services sont désormais répartis dans leurs propres conteneurs et communiquent via l'environnement de données.
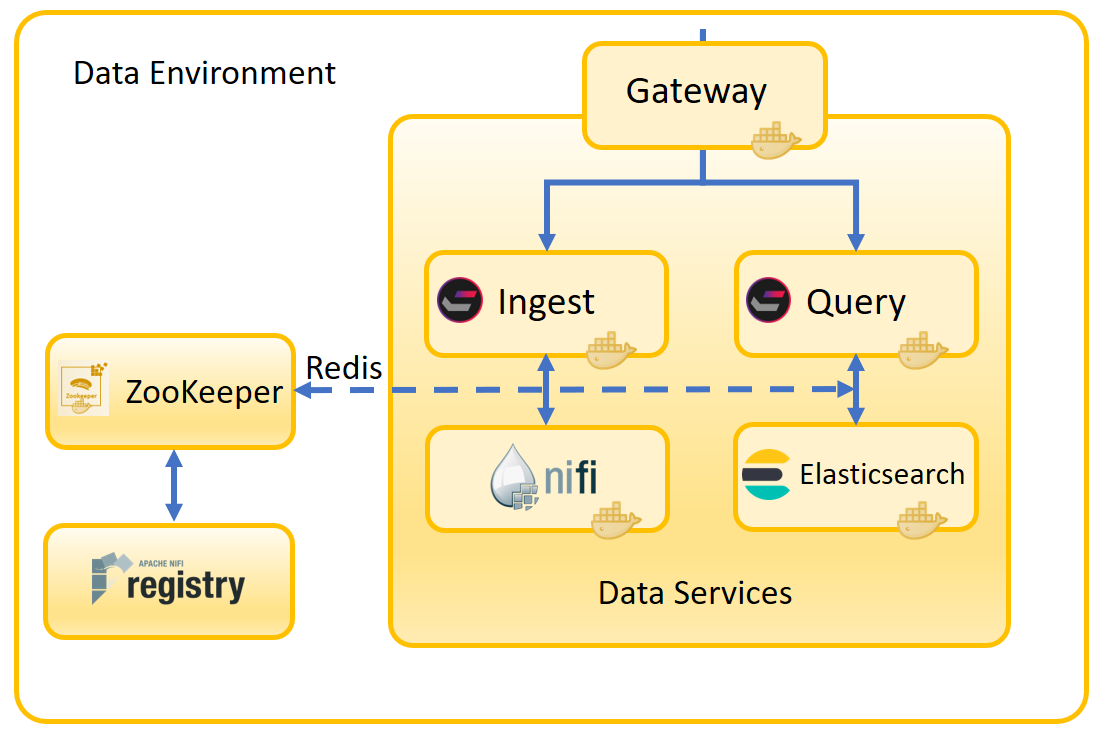
Les composants de HCL Commerce Search sont les suivants :
- Le service Ingest
- Ce microservice gère les opérations d'écriture. Il effectue les opérations essentielles d'extraction, de transformation et de chargement (ETL) sur les données métier qui les mettent à disposition de l'index de recherche. La logique métier derrière le cycle de vie de l'indexation, qui résidait auparavant dans le serveur de transactions, est maintenant gérée ici.
-
- Le service de requête
- Le service Query génère les expressions de recherche, puis transmet l'expression à Elasticsearch. Il prend également les résultats de la requête et les convertit en un format qui peut être utilisé par la vitrine. La vitrine n'a pas besoin de savoir que la réponse a été générée par Elasticsearch plutôt que par Solr.
- Apache NiFi
- NiFi est le pipeline d'indexation utilisé par le service Ingest. Il utilise des connecteurs pour apporter des données brutes et les convertir en une forme qui peut être utilisée par Elasticsearch. Vous pouvez utiliser les connecteurs NiFi par défaut pour des types de données connus ou définir les vôtres afin que NiFi puisse intégrer des types de données personnalisés. NiFi fonctionne dans son propre conteneur et est entièrement extensible.
- Elasticsearch
- Le service Query et le profil de recherche déterminent la meilleure façon de gérer la requête de recherche. Elasticsearch utilise son moteur haute performance pour exécuter la recherche, puis la réponse est filtrée à travers le profil de recherche avant d'être transmise à la vitrine. L'utilisation du profil de recherche pour filtrer la réponse signifie que la vitrine n'a pas besoin de savoir que l'interface est celle d'Elasticsearch et non pas celle de Solr.
- Redis
- Redis est utilisé comme bus de messages pour distribuer les événements de modification, ainsi que les événements d'invalidation du cache. Pour plus d'informations, voir le site du projet Redis.
- ZooKeeper
- ZooKeeper est utilisé pour stocker vos configurations par défaut et personnalisées, les descripteurs de connecteur, ainsi que les propriétés et extensions personnalisées. Cela commence avec votre profil de recherche et votre profil Ingest déjà présents.
Vous pouvez utiliser les chartes Helm préconfigurés fournis avec la version 9.1 pour déployer une pile de recherche complète et préconfigurée. En modifiant vos propres chartes Helm, vous pouvez utiliser Kubernetes pour déployer un système adapté à vos propres besoins métier.