Service Ingest
Le service Ingest est chargé d'intégrer des données dans HCL Commerce Search. Ces données, qui peuvent prendre la forme de nombreux formats différents, sont transmises à Apache NiFi, qui les prépare à être utilisées par Elasticsearch. Pour administrer le service Ingest, vous définissez une spécification de données pour écrire des descripteurs NiFi. Chaque descripteur définit le comportement d'un connecteur particulier. Les connecteurs, reliés entre eux, gèrent le pipeline de données et génèrent votre index.
Pipelines
Un canal est un groupe de processus NiFi qui contient un port d'entrée NiFi, un flux composé d'une série de processeurs NiFi et un port de sortie. Les ports d'entrée et de sortie ne peuvent que recevoir et envoyer, mais les processeurs NiFi dont ils dépendent peuvent également lire et écrire dans l'index de recherche, ou dans d'autres dépôts de données persistantes. Le groupe de processus est stocké dans un registre NiFi, qui est géré par version.
Un pipeline NiFi est constitué de l'ensemble total de canaux NiFi responsables de l'intégration d'un type particulier de données. Chaque canal de connecteur par défaut utilise un modèle de passe-partout qui contient le modèle d'ingestion de données ETL suivant (Extraction, Transformation et Chargement) :
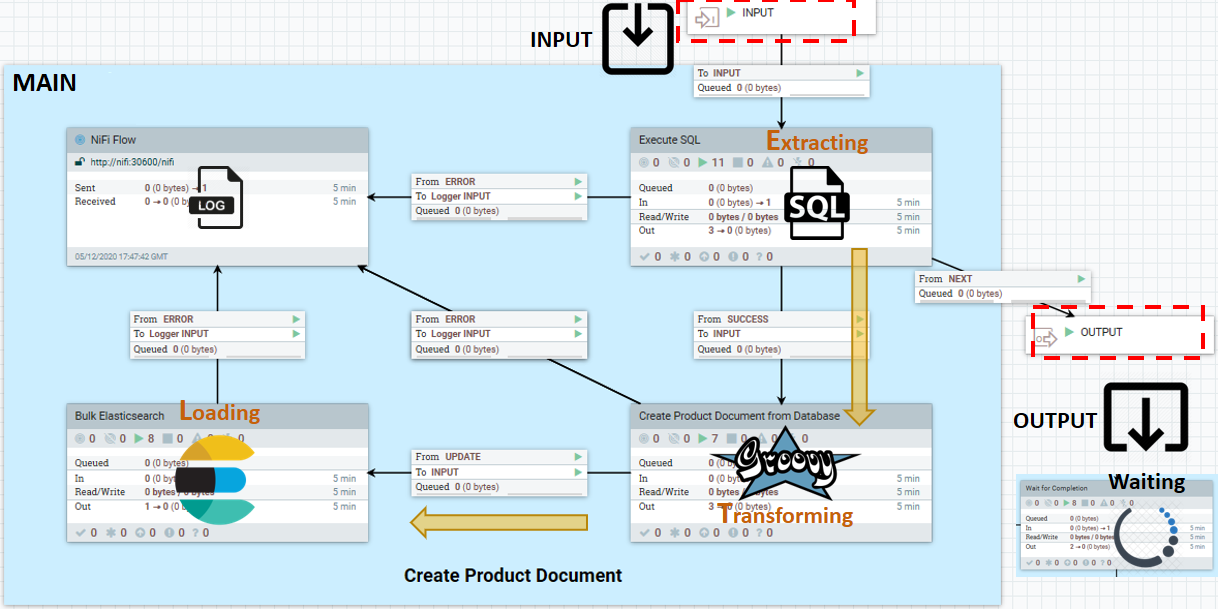
- INPUT
- Le port qui écoute les signaux des succès précédents du processeur. Envoyez uniquement des signaux de déclenchement à travers ce port et le port de sortie. Les données métier doivent être lues, traitées et écrites dans des référentiels de données externes depuis l'intérieur du canal. Cette stratégie empêche les dépendances entre les canaux.
- MAIN
- Logique de traitement ETL. Cet exemple montre une extraction et une transformation SQL à l'aide d'un script Groovy. Le principal composant peut toutefois prendre n'importe quelle forme, y compris les suivantes :
- Lire depuis un magasin de données externe
- Traiter chaque saisie de données lue dans
- Envoyer un ou plusieurs documents de données traités à Elasticsearch
- Attendre que l'ensemble des données sources soit épuisé
- OUTPUT
- Port de sortie utilisé pour envoyer un déclencheur signalant le succès aux canaux en aval.
WaitLink connecte un canal à un autre canal ou pipeline. Il suspend le flux de données jusqu'à l'achèvement (réussite, réussite partielle ou échec) de l'étape en cours.
Ne modifiez pas ces groupes de processus NiFi par défaut ou le code source inclus pour référence.
Un service de journalisation est fourni avec le service Ingest. Vous pouvez l'utiliser pour suivre les messages et les statuts des canaux individuels au fur et à mesure que les données transitent par le système.
Connecteurs
Un connecteur est un pipeline de flux de données ou un ensemble de pipelines (groupes de processus NiFi et leurs connexions) qui effectue des tâches d'ingestion et de transformation de données pour préparer les données pour l'index de recherche. Les connecteurs fournissent le contexte de cycle de vie des données et métier aux pipelines des groupes de processus connectés dans NiFi. Certains exemples de contexte de connecteur incluent le cycle de vie des données (produit, catégorie, etc.), indiquent si le flux de données est destiné à l'environnement de production ou de création, ou s'il est utilisé dans une réindexation en temps quasi réel ou complète.
Il existe des connecteurs "maîtres" qui peuvent créer un index (s'agissant de auth.reindex et live.reindex). Les connecteurs doivent être définis en tant que descripteur de connecteur, créés à l'aide de l'API de service Ingest et stockés dans ZooKeeper.
 Note: A partir de la version 9.1.10 sous, le service Ingest synchronise automatiquement NiFi avec vos descripteurs de connecteur personnalisés stockés dans Zookeeper. Les descripteurs de connecteur par défaut des éditions antérieures, précédemment stockées dans Zookeeper, ne sont plus nécessaires, à l'exception de ceux qui sont personnalisés. Vous conservez votre propre copie à l'intérieur de Zookeeper. Pour plus d'informations, voir Edition des modifications apportées au service Ingest.
Note: A partir de la version 9.1.10 sous, le service Ingest synchronise automatiquement NiFi avec vos descripteurs de connecteur personnalisés stockés dans Zookeeper. Les descripteurs de connecteur par défaut des éditions antérieures, précédemment stockées dans Zookeeper, ne sont plus nécessaires, à l'exception de ceux qui sont personnalisés. Vous conservez votre propre copie à l'intérieur de Zookeeper. Pour plus d'informations, voir Edition des modifications apportées au service Ingest.http://ElasticSearchhostname:30600/nifi/Pour plus d'informations sur l'utilisation de NiFi, consultez le Guide de l'utilisateur Apache NiFi.
Processeurs
Les processeurs NiFi sont les éléments structurels de base des pipelines de flux de données. Les processeurs effectuent des tâches spécifiques dans le pipeline, telles que l'écoute des données entrantes ; l'acquisition de données à partir de sources externes ; la publication de données vers des sources externe et le routage, la transformation ou l'extraction d'informations à partir de FlowFiles. Les processeurs sont regroupés en groupes de processus et connectés pour former des pipelines de flux de données. Les pipelines de flux de données sont à leur tour regroupés et mis en contexte par des connecteurs. Un processeur NiFi spécial, tel qu'un "processeur de liens", peut fournir un contrôle de flux dans un pipeline. Par exemple, un processeur de liaison fréquemment utilisé est un "WaitLink", qui met en pause le flux de données jusqu'à ce que l'étape en cours soit terminée, avec le statut success, partially successful ou failed, avant d'autoriser la transmission des données au groupe de processus suivant dans le pipeline de flux de données.
Groupe de processus
Un groupe de processus NiFi est un réseau de processeurs NiFi où chaque processeur est uniquement responsable du traitement d'une tâche simple. Ces processeurs sont connectés ensemble pour gérer une opération plus compliquée. Les groupes de processus sont ensuite connectés et peuvent être imbriqués dans NiFi pour former des pipelines de flux de données. Comme pour les processeurs, les données entrent dans un groupe de processus avec un état et en sortent avec un autre état. Les processeurs et les groupes de processus eux-mêmes sont sans état. Les groupes de processus NiFi et leurs connexions (représentés dans JSON en tant que "flux" stockés et organisés dans des "compartiments") sont versionnés et conservés dans le registre NiFi.
Spécifications de
Chaque spécification Apache NiFi définit le type de données et la structure d'un document d'entrée. Si vous souhaitez générer un pipeline NiFi, vous commencez généralement par la spécification. NiFi prend en charge des centaines de spécifications différentes. Si une spécification existe déjà, vous pouvez être en mesure de l'utiliser sans modification. Si vous souhaitez personnaliser votre pipeline, NiFi fournit une boîte à outils puissante, y compris une API qui vous permet de définir vos propres spécifications.