
créant un processeur NiFi personnalisé.
Procédez comme suit pour créer votre processeur NiFi personnalisé.
Procedure
-
Créez les classes de processeur et les cas de test personnalisés.
- Les classes pour les processeurs sont créées dans le répertoire /src/main/java/ ;
- Les cas de test de processeur correspondants sont créés dans le répertoire /src/test/java/.
-
Créez la logique personnalisée pour votre processeur NiFi. Les étapes suivantes illustrent comment la logique que vous créez dans Java affecte le processeur NiFi ou s'affiche dans l'interface utilisateur NiFi.
Reportez-vous au Guide du développeur NiFi pour obtenir plus de détails sur la création d'un processeur NiFi personnalisé et pour une explication approfondie des API utilisées pour développer des extensions.
-
Déclarez les zones de propriété à l'aide de
org.apache.nifi.components. Le type de données PropertyDescriptor apparaît dans l'onglet PROPRIETES du processeur personnalisé.Par exemple :
public static final PropertyDescriptor SCROLL_DURATION = new PropertyDescriptor.Builder().name("Scroll Duration") .description("The scroll duration is how long each search context is kept in memory") .required(true).addValidator(StandardValidators.NON_EMPTY_VALIDATOR) .expressionLanguageSupported(true).build();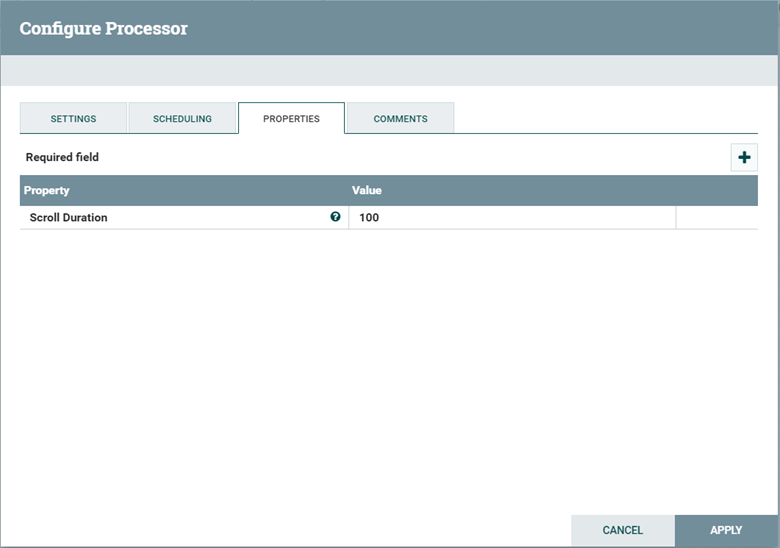
-
Déclarez les zones de relation à l'aide de
org.apache.nifi.processor. Le type de données de relation apparaît dans l'onglet PARAMETRES du processeur personnalisé.Par exemple :
public static final Relationship RELATIONSHIP_SUCCESS = new Relationship.Builder().name("success") .description("The flow file with the specified content was successfully transferred").build(); public static final Relationship RELATIONSHIP_FAILURE = new Relationship.Builder().name("failure") .description("The flow file with the specified content has encountered an error during the transfer").build(); public static final Relationship RELATIONSHIP_NEXT = new Relationship.Builder().name("next") .description("The flow file with the specified content for the next iteration").build();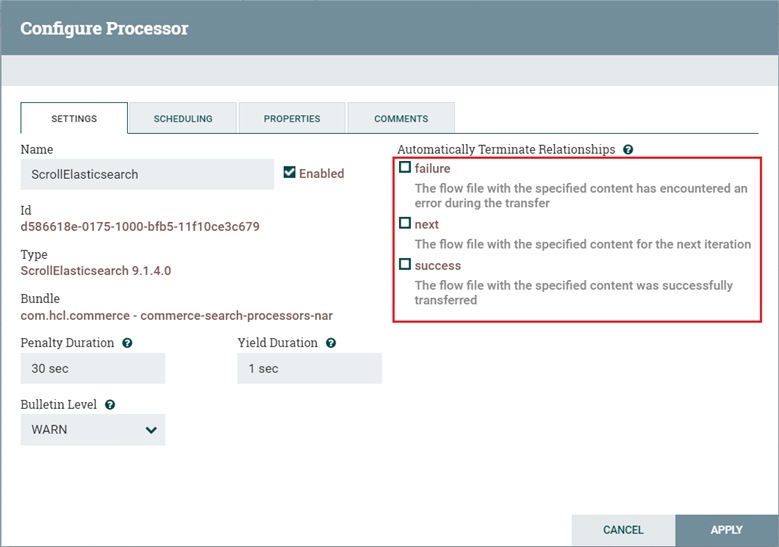
-
Déclarez les zones de propriété à l'aide de
-
Dans org.apache.nifi.processor.Processor, créez une entrée contenant le nom de classe qualifié complet de votre processeur personnalisé récemment créé. Si vous avez créé un service de contrôleur personnalisé, créez une entrée dans org.apache.nifi.controller.ControllerService.
Par exemple, dans l'explorateur de projets, développez et cliquez sur
org.apache.nifi.processor.Processor. Entrez votre nom de classe dans le volet de saisie de texte sur le côté droit de la fenêtre.