Personnalisation de la solution de recherche basée sur Elasticsearch
Les rubriques de cette section décrivent les tâches réalisées par un développeur d'applications pour personnaliser la solution de recherche basée sur Elasticsearch. Vous pouvez étendre le service Ingest et le service Query pour répondre à vos besoins métier.
La solution Elasticsearch Search est un composant d'un environnement de données unifié. Cet environnement est conçu comme un système générique de gestion des données. L'environnement comprend plusieurs composants principaux, notamment la passerelle, les services de données et le système de gestion de la configuration ZooKeeper.
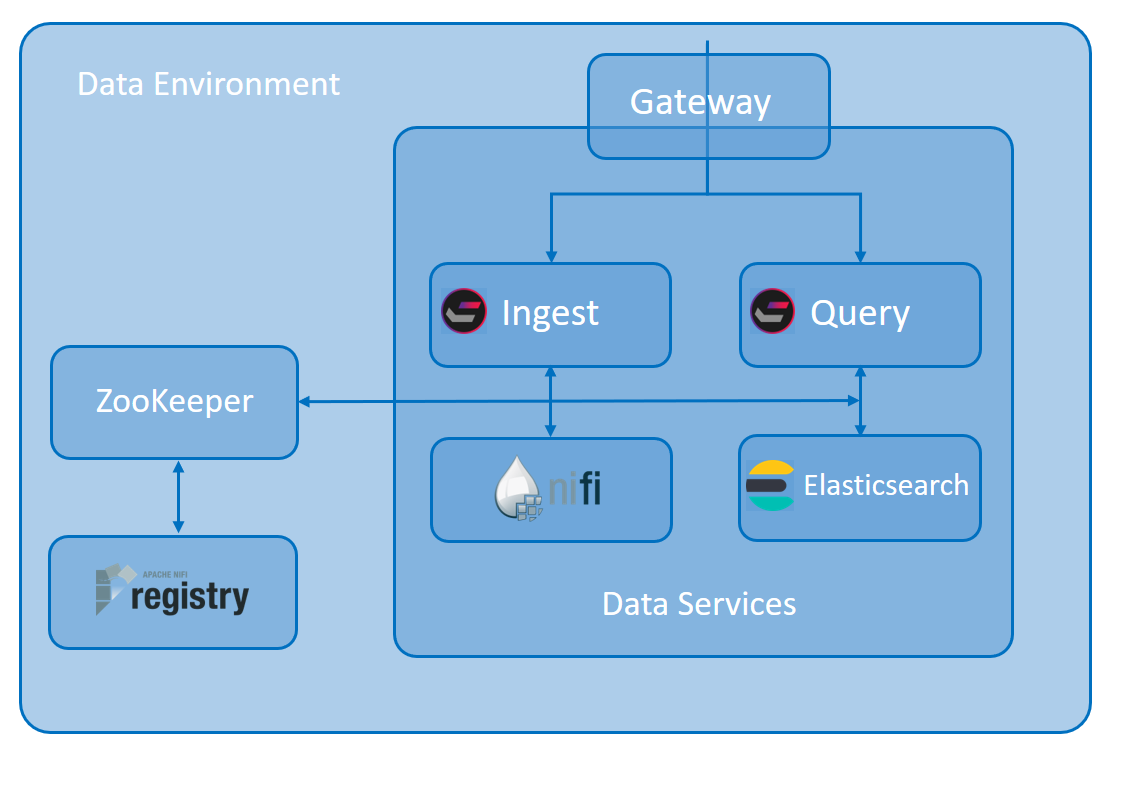
La passerelle Redis et ZooKeeper/Registry prennent en charge les services de données. Il s'agit des services de données qui contrôlent le comportement de recherche, de sorte que vous personnalisez la recherche en étendant le sous-système de chargement de données Ingest ou le sous-système de requête basé sur Elasticsearch. Il existe quatre façons principales de le faire, comme indiqué ci-dessous. En outre, vous pouvez développer des stratégies de migration et de distribution continue basées sur des modèles et des exemples fournis par HCL.
Ajout de nouveaux connecteurs Ingest
Vous pouvez ajouter un nouveau connecteur au service Ingest. Cela vous permet d'ajouter un nouveau pipeline NiFi et une nouvelle configuration pour importer et indexer de nouveaux types de données. Le nouveau connecteur est stocké dans ZooKeeper et le registre.
Des connecteurs peuvent être créés à l'aide de votre éditeur de texte préféré. Vous pouvez généralement modifier un modèle JSON existant et transmettre l'objet JSON modifié dans l'API/le connecteur de service Ingest pour créer le connecteur.
Ajout de nouveaux processeurs Ingest
Vous pouvez modifier le flux Ingest, c'est-à-dire le comportement du pipeline qui appartient à un connecteur.
Le processeur est créé en ajoutant une nouvelle logique écrite dans Java ou tout autre langage de programmation. La nouvelle logique est rendue disponible en tant que processeur déployable dans l'interface utilisateur NiFi, puis incluse dans le pipeline.
Modification ou ajout de flux de données Ingest
Vous pouvez interrompre le flux d'un pipeline existant (par défaut) ou créer votre propre pipeline à partir du sous-système NiFi.
Ajout de nouvelles API REST au service Query
Le service Query gère les fonctions liées à la recherche telles que le traitement du langage naturel (NLP) et la pertinence du texte. Vous pouvez utiliser les API Query pour ajouter vos propres services ou étendre ceux existants.
Migration et déploiement de vos extensions
Des informations de migration sont fournies pour vous aider à apporter les personnalisations apportées à la solution de recherche Solr dans le système Elasticsearch. Les services de données prennent entièrement en charge les pratiques CI/CD et HCL fournit une stratégie recommandée pour le développement de votre propre pipeline CI/CD propre à Elasticsearch.
Pour obtenir des instructions de migration, voir Migration des personnalisations Elasticsearch. Pour obtenir un guide d'implémentation d'un pipeline CI/CD Elasticsearch, voir Stratégie CI/CD pour déployer des personnalisations.