Extension du service Ingest
Le service HCL Commerce Search version 9.1 comprend Ingest and Elasticsearch, qui constituent ensemble un moteur de recherche et d'analyse distribué et évolutif. Vous pouvez enchaîner les agrégations basées sur des règles du service ingest pour améliorer la pertinence des SKU héro ou de certaines facettes, et utiliser des métriques sophistiquées pour analyser vos performances de recherche.
HCL Commerce Search fournit des recherches et des analyses en temps réel. En tant que magasin de documents distribués qui utilise des données structurées et non structurées, il peut être utilisé à de nombreuses fins en plus des recherches sur le site. Dans HCL Commerce, le client principal pour Ingest est le système de recherche hautes performances d'Elasticsearch. Ingest lui-même utilise une technologie configurable appelée NiFi, et ses canaux de connecteur personnalisés.
Indexation du flux de données
Le pipeline d'indexation se compose d'un flux principal, dans lequel les données que le service Ingest sait extraire se déplacent de façon linéaire de l'entrée vers la sortie, et d'un flux secondaire ETL, qui comporte plusieurs étapes dont vous pouvez personnaliser le comportement. Le diagramme suivant montre le modèle de conception du système.
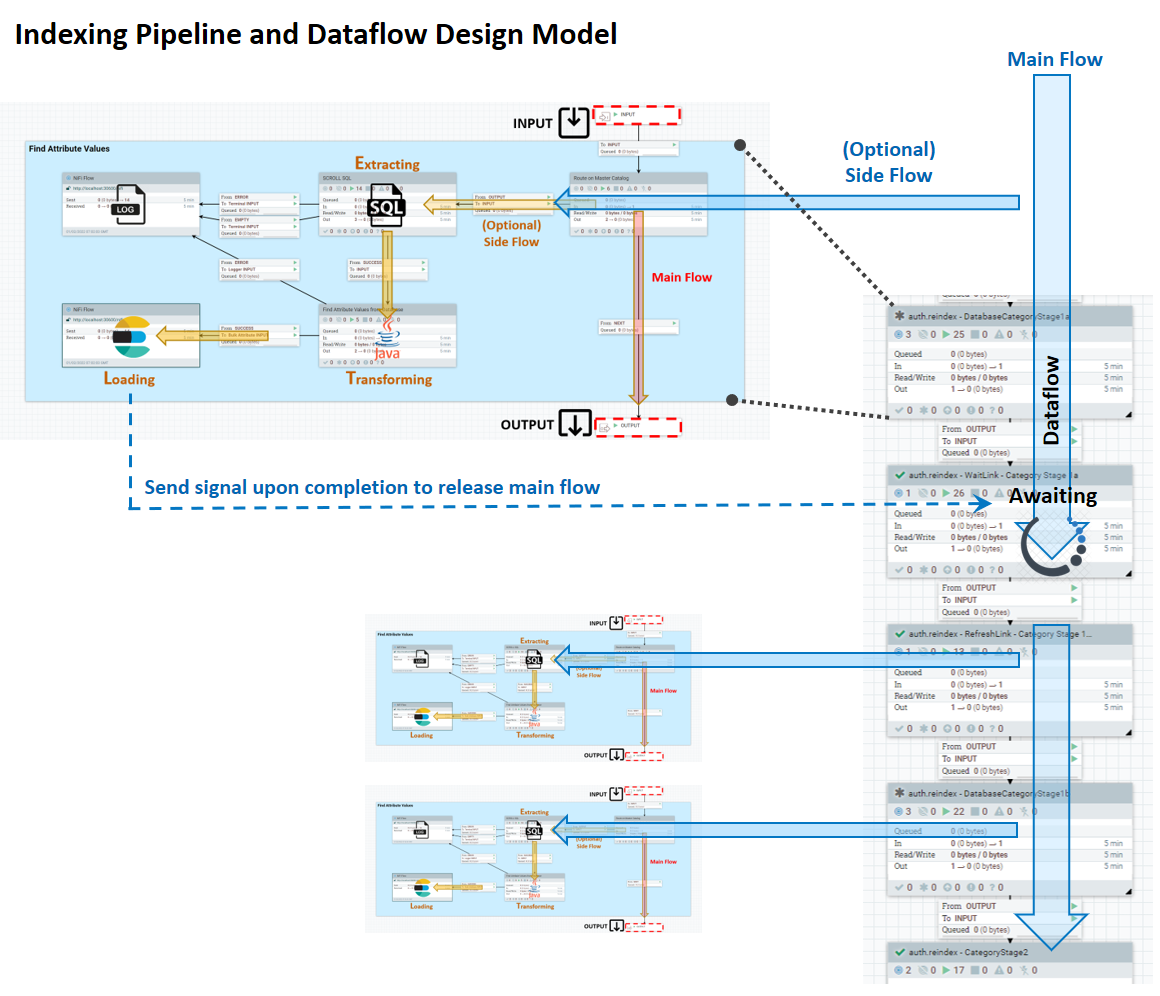
- ENTREE : port d'entrée provenant d'un flux de réussite précédent
- MAIN : Logique de traitement ETL, par exemple :
- Lire depuis un magasin de données externe
- Traiter chaque saisie de données lue dans
- Envoyer un ou plusieurs documents de données (prêts pour l'indexation) traités à Elasticsearch
- OUTPUT – port de sortie vers le canal suivant.
Un lien connecte un canal à un autre canal ou pipeline. Un lien fréquemment utilisé est un WaitLink. Ce lien suspend le flux de données jusqu'à l'achèvement (réussite, réussite partielle ou échec) de l'étape en cours.
Un service de journalisation est fourni avec Ingest pour le suivi des messages et des statuts d'un canal individuel lorsque les données circulent à travers le système.
Déploiement de personnalisations NiFi
Vous pouvez étendre le flux de données par défaut en créant un connecteur ou en modifiant un connecteur par défaut existant pour inclure des canaux personnalisés. Ces derniers peuvent ensuite être stockés et versionnés dans un registre NiFi personnalisé distinct.
Vous créez des canaux de connecteur personnalisés (également appelés groupes de processus NiFi) dans votre environnement de développement. Ces canaux peuvent être testés dans un NiFi local ou un environnement de développement et de test Commerce intégré. Une fois que vos canaux personnalisés sont prêts, ils peuvent être promus vers des environnements plus élevés pour d'autres tests et déploiements. Pour savoir comment réaliser vos propres connecteurs, voir Création d'un connecteur de service NiFi.
Utilisez un système de contrôle de version source distinct comme référentiel principal pour la maintenance de vos propres canaux personnalisés. Le Registre NiFi est uniquement utilisé pour coordonner la sortie des versions dans le pipeline en service et ne peut pas être utilisé comme stockage permanent de canaux de connecteur personnalisés.
Clusters Elasticsearch dans HCL Commerce
- nœud maître
- Le nœud maître est choisi automatiquement par le cluster et contrôle son comportement. Si un nœud maître tombe en panne, le cluster en élira un autre à sa place. Les nœuds maître sont obligatoires dans les clusters Elasticsearch.
- Nœuds de données
- Ces nœuds contiennent des données métier et utilisent Apache Lucene pour effectuer des opérations de création, de lecture, de mise à jour et de suppression au niveau des données. Les nœuds de données reconnaissent deux types de données, chaudes et tièdes. Les données chaudes ou fréquemment utilisées sont mises en cache, de préférence dans un environnement SSD.
- Nœud de coordination
- La coordination des nœuds transfère les résultats de recherche entre les nœuds de données.
- Nœuds Ingest
- HCL Commerce Search with Elasticsearch utilise les nœuds Apache NIFI comme pipeline d'admission. Ce pipeline transforme et enrichit les documents entrants avant qu'ils ne soient indexés. Il dispose d'une file d'attente permanente pour une livraison garantie.
Index et fragments
L'index Elasticsearch est un espace de noms logique mappé aux instances du moteur de recherche Apache Lucene qui s'exécute à l'intérieur des nœuds de données. L'index Elasticsearch est similaire en fonction à la table d'une base de données relationnelle. Pour obtenir une description complète des zones d'index Elasticsearch, voir Types de zones d'index Elasticsearch.
Les moteurs Lucene sont connus sous le nom de fragments. La mise en œuvre HCL Commerce d'Elasticsearch utilise deux types de fragments : un fragment primaire qui peut effectuer à la fois des opérations de lecture et d'écriture, et des fragments de réplique optimisés uniquement pour les opérations de lecture.