
Ingestion d'un fichier non structuré et d'un contenu de site Web
Vous pouvez personnaliser le service Ingest pour lui permettre de balayer les données de site Web et d'ingérer le contenu sélectionné dans Elasticsearch. Cette fonction peut être ajoutée dans le conteneur NiFi HCL Commerce Search version 9.1.
About this task
Il se peut que vous deviez explorer et ingérer des données de contenu non structurée provenant d'Internet. Le contenu non structuré du site inclut les documents qui ne respectent pas un modèle de données spécifique, tels que les pièces jointes de produits contenues dans différents formats. Par exemple, le contenu tel que les manuels d'utilisation et les informations de garantie sont considérés comme du contenu non structuré. Ses éléments, sa construction et son organisation sont généralement inconnus et peuvent varier selon son type de fichier. Le contenu non structuré peut inclure des fichiers HTML, .docx, PDF et .txt. Vous pouvez ingérer ces données en créant un groupe de processus NiFi et en associant sa sortie à un index de produit existant, ou en créant un index personnalisé et en ingérant les données dans un nouveau schéma.
Procedure
-
Activez la pièce jointe de fichier dans le conteneur Elasticsearch (docker.elastic.co/elasticsearch/elasticsearch:7.x.0).
Note: Vous pouvez ajouter la commande de pièce jointe dans le fichier Dockerfile. Si c'est le cas, vous devez générer une nouvelle image Elasticearch à partir de l'image de base.
-
Créez un répertoire dans le conteneur NiFi (commerce/search-nifi-app:9.1.x.0). Ce répertoire sera utilisé pour enregistrer le contenu exploré pour l'ingestion dans ES.
Pour créer le répertoire, vous pouvez émettre les commandes suivantes.
docker exec -it -u 0 commerce_nifi_1 bash mkdir /opt/NiFi/extDocs/ chown nifi:nifi /opt/NiFi/extDocs chmod 755 /opt/NiFi/extDocs -
Importez les connecteurs suivants dans votre registre d'exécution (commerce/search-registry-app:9.1.x.0).
docker cp custom-crawl-StaticContentIndexSchemaUpdate.json commerce_registry_1:/opt/nifi-registry/flows/ docker cp custom-crawl-StaticContentIndexSchemaUpdateConnector-attachment.json commerce_registry_1:/opt/nifi-registry/flows/ docker cp custom-crawl-StaticContentIndexDatabaseConnectorPipe-Attachment.json commerce_registry_1:/opt/nifi-registry/flows/Ouvrez le conteneur de registre NiFi et exécutez la commande suivante.docker exec -it -u 0 commerce_registry_1 bashExécutez les commandes suivantes à partir du terminal de registre./opt/nifi-registry/scripts/import_flow.sh custom-crawl-StaticContentIndexSchemaUpdate /opt/nifi-registry/flows/custom-crawl-StaticContentIndexSchemaUpdate.json /opt/nifi-registry/scripts/import_flow.sh custom-crawl-StaticContentIndexSchemaUpdateConnector-attachment /opt/nifi-registry/flows/custom-crawl-StaticContentIndexSchemaUpdateConnector-attachment.json /opt/nifi-registry/scripts/import_flow.sh custom-crawl-StaticContentIndexDatabaseConnectorPipe-Attachment /opt/nifi-registry/flows/custom-crawl-StaticContentIndexDatabaseConnectorPipe-Attachment.json -
Créez un connecteur à l'aide de l'interface Ingest Swagger. Instruction POST aux URL suivantes avec des données JSON dans le corps.
http://localhost:30800/connectors { "name": "auth.staticcontent", "description": "This is the connector for the staticcontent processing", "pipes": [ { "name": "custom-crawl-StaticContentIndexSchemaUpdate" }, { "name": "custom-crawl-StaticContentIndexSchemaUpdateConnector-attachment" }, { "name": "custom-crawl-StaticContentIndexDatabaseConnectorPipe-Attachment", "properties": [ { "name": "Database Driver Location(s)", "value": "${AUTH_JDBC_DRIVER_LOCATION}", "scope": { "name": "Database Connection Pool", "type": "CONTROLLER_SERVICE" } }, { "name": "Database Connection URL", "value": "${AUTH_JDBC_URL}", "scope": { "name": "Database Connection Pool", "type": "CONTROLLER_SERVICE" } }, { "name": "Database User", "value": "${AUTH_JDBC_USER_NAME}", "scope": { "name": "Database Connection Pool", "type": "CONTROLLER_SERVICE" } }, { "name": "Password", "value": "${AUTH_JDBC_USER_PASSWORD}", "scope": { "name": "Database Connection Pool", "type": "CONTROLLER_SERVICE" } } ] }, { "name": "Terminal" } ] } -
Après l'exécution du connecteur, les quatre canaux de groupe de processus suivants seront disponibles dans NiFi. Ajoutez le groupe de processus dans le tableau de bord NiFi et connectez les ports d'entrée/de sortie comme illustré dans l'image suivante.
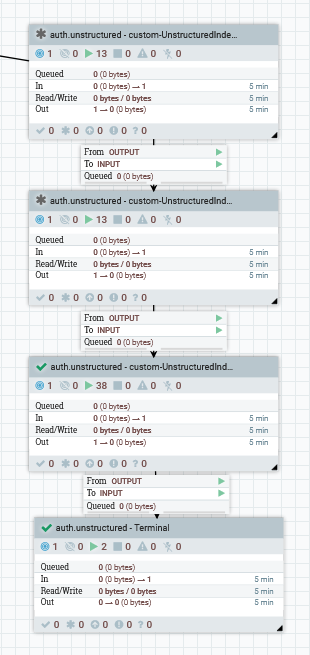
Configurez les quatre groupes de processus comme suit.
- custom-UnstructuredIndexSchemaUpdate
- Ce groupe de processus sera utilisé pour définir un nouveau schéma. Il sera ignoré si le schéma est déjà disponible dans Elasticsearch. Vous pouvez utiliser un schéma existant et simplement mettre à jour le nom de l'index dans le fichier de propriétés suivant pour que le processeur définisse un nom de schéma non structuré.
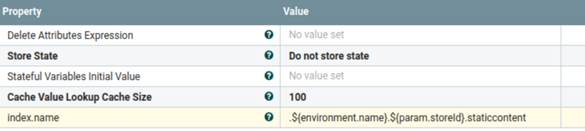
- custom-UnstructuredIndexSchemaUpdateConnector-attachment
- Ce groupe de processus sera utilisé pour activer le paramètre de pièce jointe dans Elasticsearch. Il sera ignoré si le paramètre de pièce jointe est déjà disponible.
Le paramètre suivant a été utilisé par défaut.
Le paramètre param.attach est disponible dans le processeur
Set staticcontent attachment.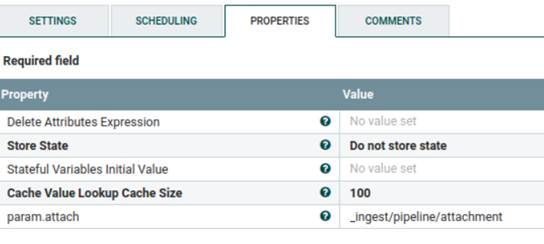
Le fichier JSON suivant est disponible dans le processeur "Remplir le schéma d'index StaticContent".
Ici, nous pouvons ajouter/mettre à jour le mot clé, ce mot clé sera utilisé pour ingérer/rechercher des données non structurées/de contenu statique.{ "description" : "Extract attachment information", "processors" : [ { "attachment" : { "field" : "data", "indexed_chars_field" : "max_size", "properties": [ "content", "title", "keywords", "content_type", "content_length" ] } } ] } - custom-UnstructuredIndexDatabaseConnectorPipe-Attachment
- Ce groupe de processus est utilisé pour extraire l'emplacement du fichier à partir d'une base de données. Il lit le contenu du fichier à partir d'un répertoire mentionné dans la base de données, le code en base64 et ingère le contenu du fichier dans Elasticsearch.
Ce groupe de processus dispose de plusieurs processeurs pour ingérer les fichiers dans Elasticsearch.
Le processeur
Set Attributedéfinit le paramètre qui sera utilisé pour le traitement du fichier. Vous pouvez le mettre à jour selon vos besoins.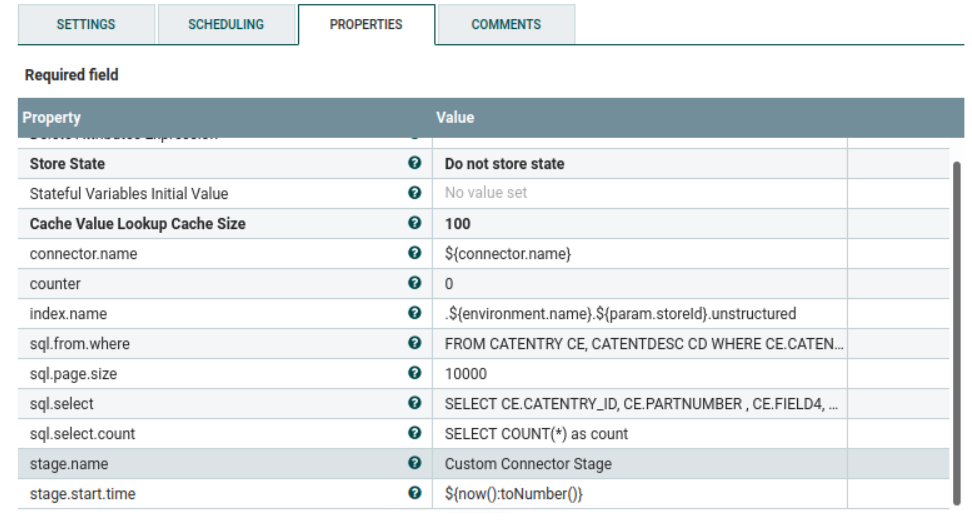
- Terminal
- Ce groupe de processus termine le flux de processus et est requis pour finaliser la sortie du processus précédent.
-
Exécutez les requêtes suivantes pour définir l'emplacement du fichier dans
Catentry.field4. Vous pouvez modifier les requêtes et ajouter plusieurs transactions si nécessaire pour définir l'emplacement du fichier pour les entrées de catalogue.UPDATE catentry SET FIELD4 = '/opt/nifi/extDocs/SampleDocs-travel-laptop.docx' WHERE PARTNUMBER = 'CLA022_2203' UPDATE catentry SET FIELD4 = '/opt/nifi/extDocs/SampleDocs-office-laptop.ppt' WHERE PARTNUMBER = 'CLA022_2205'Note: Si vous souhaitez définir l'emplacement du fichier dans un autre tableau, modifiez les propriétés suivantes dans le processeurSet Attributesous custom-UnstructuredIndexDatabaseConnectorPipe-Attachment. Vous pouvez mettre à jour les requêtes selon vos besoins.SELECT COUNT(*) as count FROM CATENTRY CE, CATENTDESC CD WHERE CE.CATENTRY_ID = CD.CATENTRY_ID AND CD.LANGUAGE_ID =-1 AND CE.MARKFORDELETE =0 AND CE.BUYABLE =1 AND CD.PUBLISHED =1 AND ce.FIELD4 IS not NULL AND CE.CATENTRY_ID IN (SELECT C.CATENTRY_ID FROM CATGPENREL R, CATENTRY C WHERE R.CATALOG_ID IN (SELECT CATALOG_ID FROM STORECAT WHERE STOREENT_ID IN (SELECT RELATEDSTORE_ID FROM STOREREL WHERE STATE = 1 AND STRELTYP_ID = -4 AND STORE_ID = ${param.storeId})) AND R.CATENTRY_ID = C.CATENTRY_ID AND C.MARKFORDELETE = 0 AND C.CATENTTYPE_ID <> 'ItemBean') SELECT CE.CATENTRY_ID, CE.PARTNUMBER , CE.FIELD4, CD.NAME, CD.SHORTDESCRIPTION , CD.PUBLISHED FROM CATENTRY CE, CATENTDESC CD WHERE CE.CATENTRY_ID = CD.CATENTRY_ID AND CD.LANGUAGE_ID =-1 AND CE.MARKFORDELETE =0 AND CE.BUYABLE =1 AND CD.PUBLISHED =1 AND ce.FIELD4 IS not NULL AND CE.CATENTRY_ID IN (SELECT C.CATENTRY_ID FROM CATGPENREL R, CATENTRY C WHERE R.CATALOG_ID IN (SELECT CATALOG_ID FROM STORECAT WHERE STOREENT_ID IN (SELECT RELATEDSTORE_ID FROM STOREREL WHERE STATE = 1 AND STRELTYP_ID = -4 AND STORE_ID = ${param.storeId})) AND R.CATENTRY_ID = C.CATENTRY_ID AND C.MARKFORDELETE = 0 AND C.CATENTTYPE_ID <> 'ItemBean')Note: Si vous souhaitez mettre à jour le nom du schéma dans lequel la pièce jointe du fichier sera ingérée, modifiez les propriétés suivantes dans le processeurSet Attributesous custom-UnstructuredIndexDatabaseConnectorPipe-Attachment.
-
Connectez le groupe de processus auth.unstructured - custom-UnstructuredIndexSchemaUpdate au groupe de processus
Routing ServiceavecINPUT auth.unstructured.Note: Ce processus doit déjà être connecté au service de routage si le processus de connecteur est suivi. Vérifiez que la route auth.unstructured est disponible. -
Accédez au groupe de processus .
Sélectionnez le processeur
Execute SQL, cliquez avec le bouton droit de la souris et sélectionnez Afficher la configuration, puis sélectionnez le bouton fléché à droite de la propriété Service de regroupement de connexion de base de données.Vérifiez que le service de pool
Database Connectionest activé. -
Démarrez les quatre groupes de processus, puis accédez à l'intérieur de chaque groupe de processus. Cliquez avec le bouton droit de la souris sur le flux NiFi, puis sélectionnez Activer la transmission.
Note: Il est possible que les transmissions soient déjà activées.
-
Après avoir démarré les groupes de processus, adressez l'instruction POST à l'URL suivante.
Pour vérifier le statut, émettez une commande GET sur les URL suivantes :https://localhost:5443/wcs/resources/admin/index/dataImport/build?connectorId=auth.unstructured&storeId=1https://localhost:5443/wcs/resources/admin/index/dataImport/status?jobStatusId=1036
Results
What to do next
localhost:30200/.auth.1.unstructured/_search{ "query": { "bool": {
"must": [
{
"query_string": {
"query": "lightweight"
}
}
]
} } }{ "query": { "bool": {
"must": [
{
"query_string": {
"query": "CLA022_2205"
}
}
]
} } }{ "query": { "bool": {
"must": [
{
"query_string": {
"query": "docx"
}
}
]
} } }