Tableaux de base de données personnalisés pour Ingest
Vous pouvez intégrer des données de catalogue à partir de votre base de données en ajoutant un tableau de base de données personnalisé pour CATENTRY et CATGROUP. Vous pouvez également contrôler la façon dont les données de base de données sont sérialisées dans Elasticsearch pour apporter des jeux de données de grande taille.
Procedure
-
Définissez les variables NiFi suivantes sur les canaux
ReindexLink,NRTLinketDataloadLink.- Utilisez custom.table.catentry pour fournir un tableau CATENTRY personnalisé afin d'affiner la portée de base des SQL d'entrée de catalogue.
- Utilisez custom.where.catentry pour fournir une clause Where personnalisée du tableau CATENTRY personnalisé.
- Utilisez custom.table.catgroup pour fournir un tableau CATGROUP personnalisé afin d'affiner la portée de base des SQL de groupe de catalogues.
- Utilisez custom.where.catgroup pour fournir une clause Where personnalisée du tableau CATGROUP personnalisé ci-dessus.Note: une fois qu'un tableau personnalisé est défini, un ensemble équivalent de variables de fichier de flux TI_DELTA sera généré. Le nom de variable similaire commence par X_CUSTOM au lieu de TI_DELTA.
Utilisez ces variables "tableau personnalisé" et "condition personnalisée" pour générer une condition INNER JOIN pour tous les SQL dans les pipelines par défaut.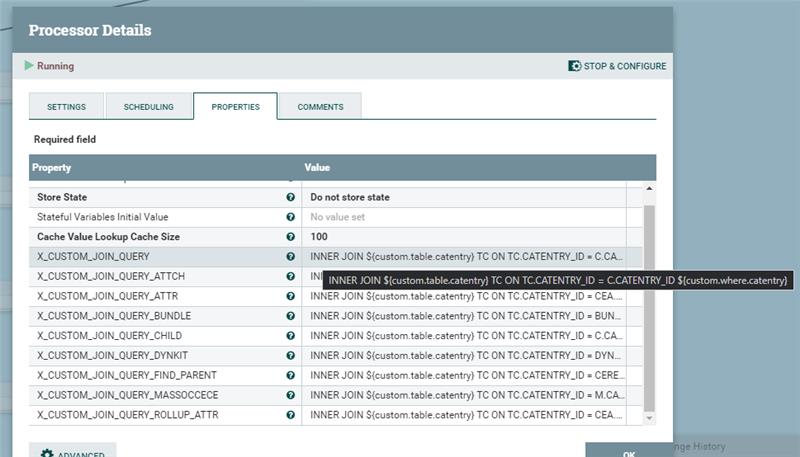 Utilisez la variable X_CUSTOM_JOIN_QUERY dans le SQL déclaré dans chacun des canaux du connecteur. Par exemple,
Utilisez la variable X_CUSTOM_JOIN_QUERY dans le SQL déclaré dans chacun des canaux du connecteur. Par exemple,
-
Facultatif : Si vous souhaitez autoriser le remplacement du nom du schéma de base de données, suivez les étapes précédentes pour mettre à jour les variables NiFi dans
ReindexLink,NRTLinketDataloadLink. Toutefois, utilisez flow.database.schema pour définir le nom du schéma de base de données personnalisé à utiliser pour l'indexation.