
Profils Ingest
Vous pouvez utiliser des profils Ingest pour définir des extensions Java pour l'extraction des données de base de données SQL et pour définir la logique de transformation des données. Les profils Ingest sont liés aux canaux de connecteur et s'exécutent dans le cadre du processus de canal.
- 1. Extraction des données
- Vous pouvez affecter des SQL par défaut à un attribut de fichier de flux
ingest.database.sqlafin que les fournisseurs facultatifs en aval SQL implémentés dans Java puissent y apporter des modifications supplémentaires. - 2. Transformation de données
- Vous pouvez utiliser une liste de préprocesseurs Java facultatifs pour modifier l'ensemble de résultats de base de données avant de l'envoyer à la logique de transformation par défaut. Vous pouvez également fournir une autre liste de post-processeurs Java facultatifs. Ceux-ci peuvent effectuer une personnalisation supplémentaire par rapport au document Elasticsearch généré par la logique par défaut, avant de l'envoyer à Elasticsearch pour indexation.
Vous développez et générez ces extensions Java personnalisées de la même manière qu'un processeur NiFi standard, à l'intérieur du kit d'outils NiFi dans Eclipse. Pour activer vos fichiers binaires, vous les conditionnez et les déployez dans le dossier /lib à l'intérieur du conteneur NiFi.
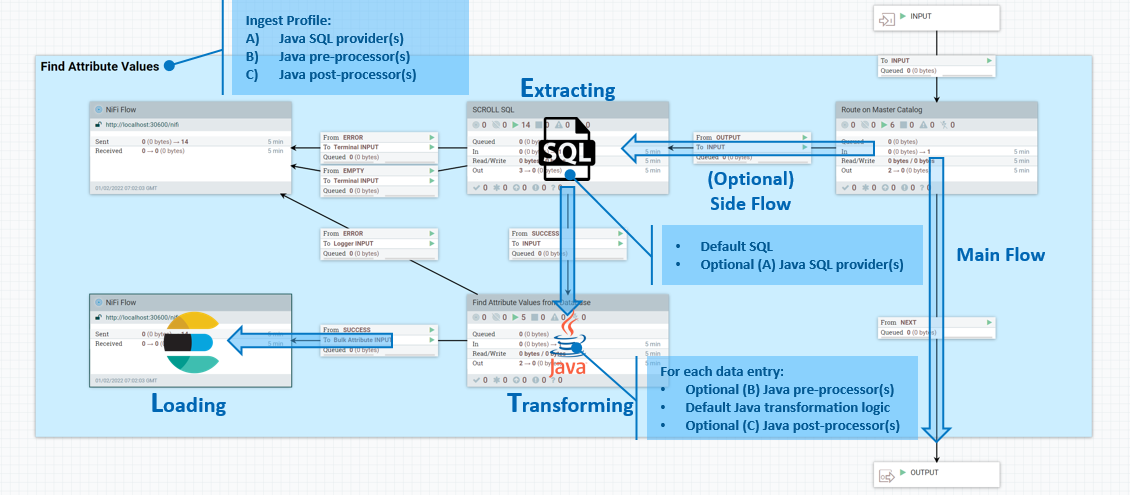
Gestion des profils Ingest
profileType=Ingest, qui a été ajouté à l'API de profils existante dans l'application de service Query. Vous pouvez trouver le nœud final sur http://query_host:query_port/search/resources/api/v2/documents/profiles?profileType=Ingest Notez que /profiles contient un répertoire, custom, avec trois autres sous-répertoires : ingest, nlp et search. Vous pouvez placer des profils personnalisés dans le sous-répertoire approprié. Cela permet à vos images Data Query personnalisées d'inclure leurs propres configurations personnalisées. Celles-ci peuvent ensuite être générées à l'aide de votre propre pipeline CI /CD. De cette façon, vos images peuvent être réutilisées dans plusieurs environnements, sans que vous ne deviez utiliser des configurations provenant de ZooKeeper spécifique à l'environnement.
Notez que /profiles contient un répertoire, custom, avec trois autres sous-répertoires : ingest, nlp et search. Vous pouvez placer des profils personnalisés dans le sous-répertoire approprié. Cela permet à vos images Data Query personnalisées d'inclure leurs propres configurations personnalisées. Celles-ci peuvent ensuite être générées à l'aide de votre propre pipeline CI /CD. De cette façon, vos images peuvent être réutilisées dans plusieurs environnements, sans que vous ne deviez utiliser des configurations provenant de ZooKeeper spécifique à l'environnement.
Pour plus d'informations, sur l'API Query, voir Spécifications API du service Query.