Personnalisation de profils ingest
Vous pouvez utiliser des profils Ingest personnalisés pour remplacer la définition de schéma d'index. Vous pouvez également les utiliser pour personnaliser le flux secondaire Extraction, Transformation et Chargement (ETL) du processus Ingest et pour les services en masse. Des méthodes Java existent pour faciliter la personnalisation de chaque étape.
{ "profileName": "DatabasePriceStage1a", "provider": [ "com.mycompany.data.ingest.product.providers.ChangeSQL" ], "preprocessor": [], "postprocessor": [] } Vous développez et générez les extensions Java personnalisées utilisées par le profil dans le kit d'outils NiFi contenu dans Eclipse. Pour activer vos représentations binaires, empaquetez-les et déployez-les vers le dossier /lib présent dans le conteneur NiFi.
Personnalisation des définitions de schéma d'index
Vous pouvez personnaliser la définition du schéma d'index lors de l'étape de préparation de l'index. Vous définissez le fournisseur de schéma à l'aide d'un profil Ingest et vous le configurez au niveau du canal du schéma de connecteur.
IndexSchemaProvider. La méthode est définie comme suit.public interface IndexSchemaProvider { public String invoke(final ProcessContext context, final ProcessSession session, final String schema) throws ProcessException; }- contexte
- Permet d'accéder à des méthodes pratiques permettant d'obtenir des valeurs de propriété, qui retardent la planification du processeur, d'accéder aux services du contrôleur, etc.
- session
- Permet d'accéder à un {@link ProcessSession}, qui peut être utilisé pour accéder à FlowFiles, etc.
- schéma
- Contient le paramètre de schéma d'index Elasticsearch et la définition de mappage.
- renvoyer
- La définition de schéma modifiée.
- renvoie
- Renvoie une instruction ProcessExeption si le traitement ne s'est pas terminé normalement.
public class MyProductSchemaProvider implements IndexSchemaProvider { @override public String invoke(final ProcessContext context, final ProcessSession session, final String schema) throws ProcessException { String mySchema = schema; // TODO: logic for customizing schema definition goes here return mySchema; } }{ "profileName": "MyProductSchema", "provider": [ "com.mycompany.data.index.product.providers.MyProductSchemaProvider" ] }Personnalisation de logique ETL par défaut
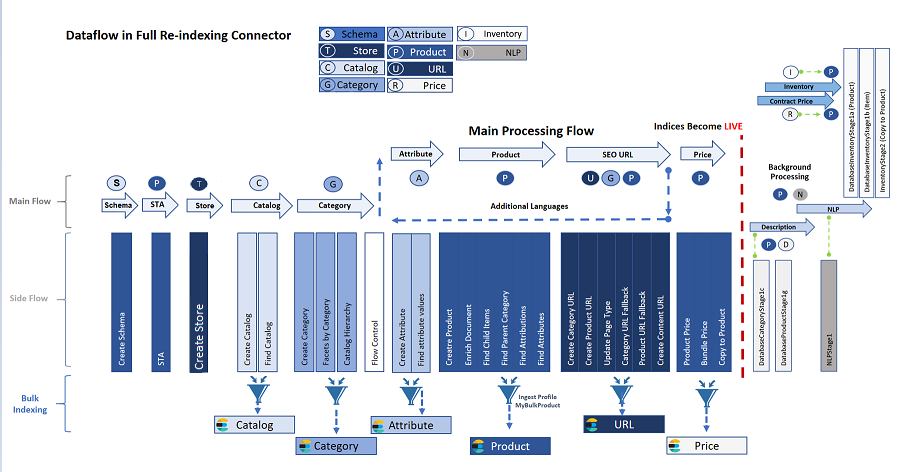
Le service Ingest effectue les opérations essentielles d'extraction, de transformation et de chargement (ETL) sur les données métier qui les mettent à disposition de l'index de recherche. Chaque canal d'un connecteur est chargé d'effectuer une ou plusieurs opérations ETL et vous pouvez ajouter et personnaliser vos propres canaux.
Le pipeline d'indexation se compose d'un flux principal, dans lequel les données que le service Ingest sait extraire se déplacent de façon linéaire de l'entrée vers la sortie, et d'un flux secondaire ETL, qui comporte plusieurs étapes dont vous pouvez personnaliser le comportement. Le diagramme suivant montre le modèle de conception du système.
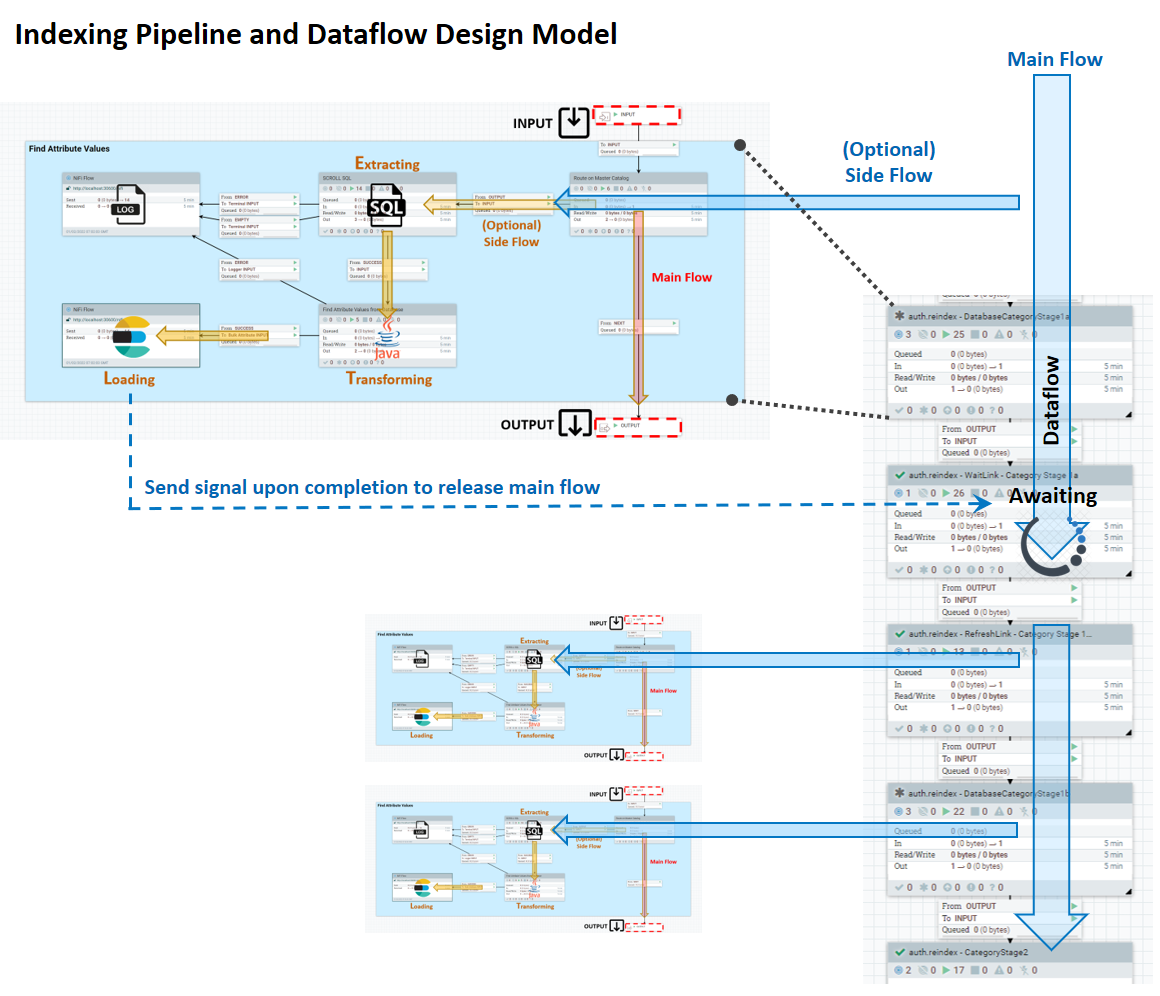
Les processus ETL ont lieu dans le flux secondaire d'entrée de données. Dans le flux secondaire, l'extraction est gérée par requêtes SQL, la transformation est effectuée à l'aide d'expressions Java et le chargement est effectué par Elasticsearch. Un profil Ingest vous permet de définir des fournisseurs SQL Java supplémentaires pour la phase d'extraction, ainsi que des préprocesseurs et post-processeurs, également dans Java.
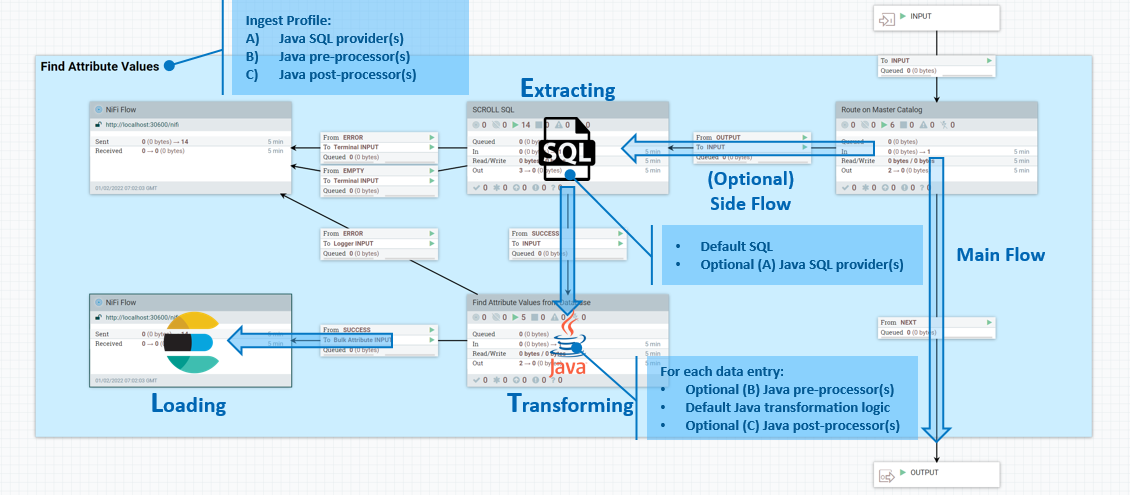
Phase d'extraction
IngestExpressionProvider comme exit personnalisé pour personnaliser ETL. L'interface est définie comme suit.public interface IngestExpressionProvider { public String invoke(final ProcessContext context, final ProcessSession session, final String expression) throws ProcessException;- contexte
- Permet d'accéder à des méthodes pratiques permettant d'obtenir des valeurs de propriété, qui retardent la planification du processeur et donnent l'accès aux services du contrôleur, etc.
- session
- Permet d'accéder à un
{@link ProcessSession}, qui peut être utilisé pour accéder à FlowFiles et à d'autres processus. - expression
- Contient l'expression SQL de base de données à exécuter.
- renvoyer
- Expression SQL modifiée.
- renvoie
ProcessExceptionsi le traitement ne s'est pas terminé normalement.
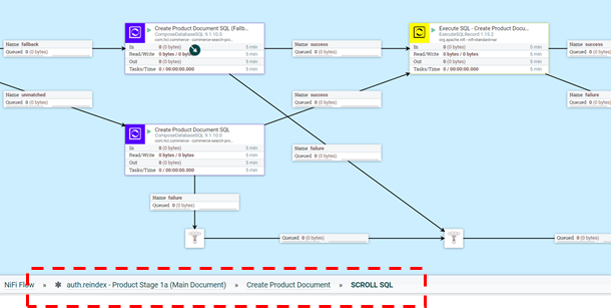
Pour personnaliser la phase d'extraction du processus ETL, vous pouvez intervenir dans la logique à l'intérieur de la partie SCROLL SQL du flux secondaire. L'emplacement exact du flux NiFi est auth.reindex-Product Stage 1a (Main Document)/Create Product Document/SCROLL SQL.
public class MyProductStage1aProvider implements IngestExpressionProvider { @override public String invoke(final ProcessContext context, final ProcessSession session, final String expression) throws ProcessException { String myExpression = expression; //Logic for customizing database SQL expression goes here return myExpression; } }Etape de prétraitement
IngestFlowPreProcessor à votre profil, en tant qu'exit utilisateur personnalisé avant que la transformation de flux ne se produise à l'étape en cours. L'interface est définie comme suit.public interface IngestFlowPreProcessor { public Map<String, Object> invoke (final ProcessContent context, final ProcessSession session, final Map<String, Object> data) throws ProcessException; }- contexte
- Permet d'accéder à des méthodes pratiques permettant d'obtenir des valeurs de propriété et de retarder la planification du processeur, mais aussi d'accéder aux services du contrôleur, etc.
- session
- Permet d'accéder à un
{@link ProcessSession}, qui peut être utilisé pour accéder à FlowFiles et à d'autres services. - données
- Contient une entrée de l'ensemble de résultats de base de données.
- renvoyer
- Données modifiées pour le traitement en aval.
- renvoie
ProcessExceptionsi le traitement ne s'est pas terminé correctement.
IngestFlowPreProcessor.public class MyProductStage1aPreProcessor implements IngestFlowPreProcessor { @Override public Map<String, Object> invoke(final ProcessContext context, final ProcessSession session, final Map<String, Object> data) throws ProcessException { // TODO: logic for customizing database result entry goes here return myData; } } Post-traitement
IngestFlowPostProcessor en tant qu'exit utilisateur personnalisé après l'étape de transformation et avant l'étape de chargement. La méthode est définie comme suit.public interface IngestFlowPostProcessor { public Map<String, Object> invoke(final ProcessContext context, final ProcessSession session, final Map<String, Object> data, final Map<String, Object> document) throws ProcessoException;- contexte
- Permet d'accéder à des méthodes pratiques permettant d'obtenir des valeurs de propriété et de retarder la planification du processeur, mais aussi d'accéder aux services du contrôleur, etc.
- session
- Permet d'accéder à un
{@link ProcessSession}, qui peut être utilisé pour accéder à FlowFiles et à d'autres services. - données
- Contient une entrée de l'ensemble de résultats de base de données.
- document
- Contient un objet JSON représentant le document final à envoyer à Elasticsearch.
- renvoyer
- Données modifiées pour le traitement en aval.
- renvoie
ProcessExceptionsi le traitement ne s'est pas terminé correctement.
La capture d'écran suivante montre un exemple de code utilisé pour étendre l'étape de post-traitement via IngestFlowPostProcessor. Ici, myDocument représente le document JSON final qui sera envoyé à Elasticsearch.
public class MyProductStage1aPostProcessor implements IngestFlowPostProcessor { @override public Map<String, Object> invoke(final ProcessContext context, final ProcessSession session, final Map<String, Object> data, final Map<String, Object> document) throws ProcessException { Map<String, Object> myDocument = new HashMap(document); // TODO: logic for customizing the Json document before sending to Elasticsearch // // For example .... final Map<String, String> x_field1 = new HashMap<String, String>(); // Retrieve value of FIELD1 from database result entry final String FIELD1 = (String) data.get("FIELD1"); // Insert value of FIELD1 into the resulting document to be sent to Elasticsearch if (StringUtils.isNotBlank(FIELD1)) { // Re-use default dynamic keyword field name "*.raw" (can be found from Product index schema) String field1 = FIELD1.trim(); // // TODO: perform your own transformation of field1 // x_field1.put("raw", field1); // x_field1.raw myDocument.put("x_field1", x_field1); } return myDocument; } }Personnalisation des services en masse
Le flux de réindexation complet se poursuit sous la forme d'un ensemble d'étapes avec des flux secondaires facultatifs. La sortie de ces flux secondaires est acheminée via des services en masse et dans chaque index correspondant. Chaque index dispose d'un service en masse dédié et un profil Ingest peut être lié à ce service s'il est nécessaire d'injecter un exit utilisateur personnalisé dans ce flux de données. Vous pouvez également appeler un pré et un post-processeur à ce stade, avant d'envoyer la charge utile en masse à Elasticsearch et après avoir reçu la réponse d'Elasticsearch.
Génération de personnalisations
- Configurer un environnement de développement de kit d'outils NiFi. Pour plus d'informations, voir Configuration de l'HCL Commerce Developer Search environment.
- Développer et tester vos logiques personnalisées de profil Ingest.
- Créer votre configuration de profil Ingest et l'associer à un canal de connecteur dans un environnement d'exécution NiFi.
- Déployer vos extensions personnalisées de profil Ingest dans votre environnement d'exécution NiFi pour d'autres tests.
Pour un tutoriel détaillé sur la personnalisation, le test et le déploiement de vos personnalisations via les profils Ingest, voir Tutoriel : Personnalisation des connecteurs par défaut avec le profil Ingest. Ce tutoriel couvre des sujets tels que les prérequis de l'environnement de développement, la génération et le transfert de fichiers .jar personnalisés dans votre environnement.
Test et débogage
Vous pouvez effectuer des tests de codage et d'unité à l'intérieur du kit d'outils NiFi basé sur Eclipse à l'aide de données simulées, via l'option de test JUnit fournie par Maven. Deux exemples de test d'unité sont fournis pour vous dans le fichier commerce-custom-search-marketplace-seller.zip. Ces fichiers sont ComposeDatabaseSQLTest.java et CreateProductDocumentFromDatabaseTest.java.
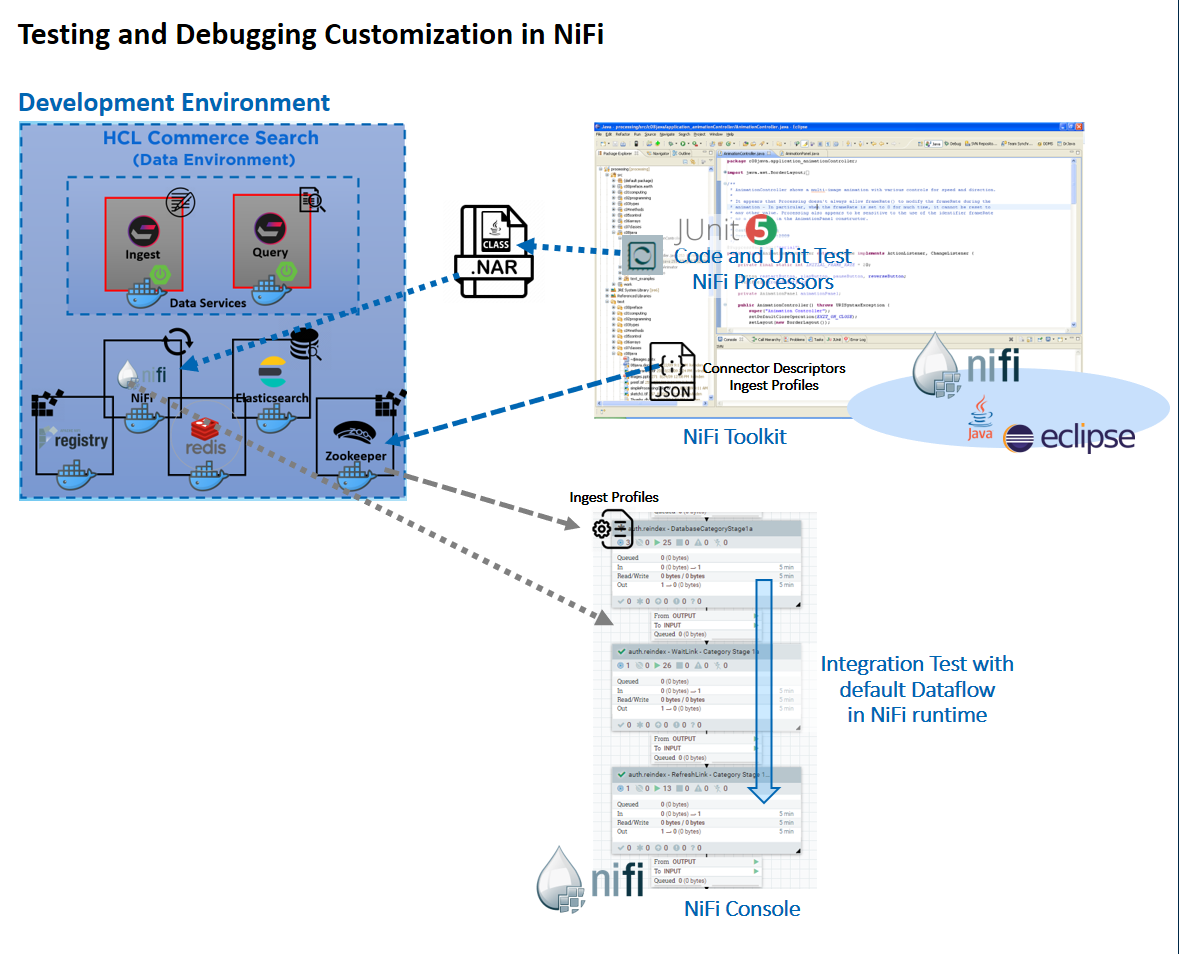
ChangeSQL est un fournisseur d'expression de profil Ingest. Vous pouvez utiliser cet exemple de référence pour apprendre à modifier le SQL utilisé dans les phases d'extraction, de transformation et de chargement (ETL) par défaut. ComposeDatabaseSQLTest est le test JUnit qui peut être utilisé pour vérifier la logique de code dans ChangeSQL.
ChangeDocument est une extension post-processeur de profil Ingest qui montre comment effectuer d'autres manipulations de données après la transformation par défaut, dans une des phases Ingest liées au produit. CreateProductDocumentFromDatabaseTest est le test JUnit qui peut être utilisé pour vérifier la logique de code dans ChangeDocument.
Une fois les configurations personnalisées et les logiques d'extension Java prêtes, elles peuvent être exportées dans un fichier NAR NiFi personnalisé et ajoutées au conteneur NiFi. Cela vous permet de tester la logique personnalisée avec le flux de données par défaut dans l'environnement d'exécution NiFi.
Pour exécuter le test JUnit, cliquez avec le bouton droit de la souris sur la classe de test JUnit choisie et choisissez Exécuter en tant que... ou .