Génération d'index par fragment à l'aide de plusieurs JVM
Lorsque l'indexation prend trop de temps et que des réglages supplémentaires ne semblent pas aider, il se peut que votre serveur approche de ses limites physiques. Pour éviter une telle condition, vous pouvez distribuer l'index sur deux serveurs de recherche ou plus, de sorte que la charge de travail d'indexation soit également distribuée. Vous pouvez distribuer votre index sur plusieurs machines virtuelles Java.
Avant de commencer
Pour effectuer la fragmentation d'index avec le serveur de recherche, configurez d'abord votre environnement de fragment à l'aide des recommandations suivantes.
- Déterminez le nombre de fragments que vous utiliserez en fonction de la capacité disponible de votre serveur. La capacité d'au moins un cœur d'UC doit être disponible pour chaque fragment d'index distinct.
- Si vous utilisez la réplication d'index, ne configurez aucun de vos fragments d'index pour participer à votre réseau de réplication d'index. Ces fragments ne sont utilisés que pour la génération d'index. La version finale de l'index doit se trouver sur le serveur principal, qui doit ensuite être répliqué au répéteur, puis aux subordonnés.
- Attribuez suffisamment de mémoire de fragment de mémoire à chacun de vos fragments d'index. Reportez-vous à HCL Commerce Search : optimisation des performances pour obtenir des recommandations sur la configuration du fichier solrconfig.xml.
Pourquoi et quand exécuter cette tâche
Pour distribuer un index, vous le divisez en partitions appelées fragments. Les fragments peuvent partager le même conteneur Docker de recherche ou être exécutés séparément dans leurs propres conteneurs de recherche, selon les performances du système. Si vos conteneurs de fragments de recherche et le conteneur principal de recherche ne sont pas situés dans la même machine virtuelle ou le même ordinateur physique, vous pourriez avoir besoin d'une technologie supplémentaire de système de fichiers distribués, par exemple remoteStorage, pour aider les conteneurs de fragments de recherche à partager un dossier d'index avec le conteneur principal.
Une fois que tous les fragments d'index sont renseignés avec succès, ils peuvent être fusionnés dans un index optimisé, à utiliser avec votre vitrine pour le tri, la création de facettes et le filtrage.
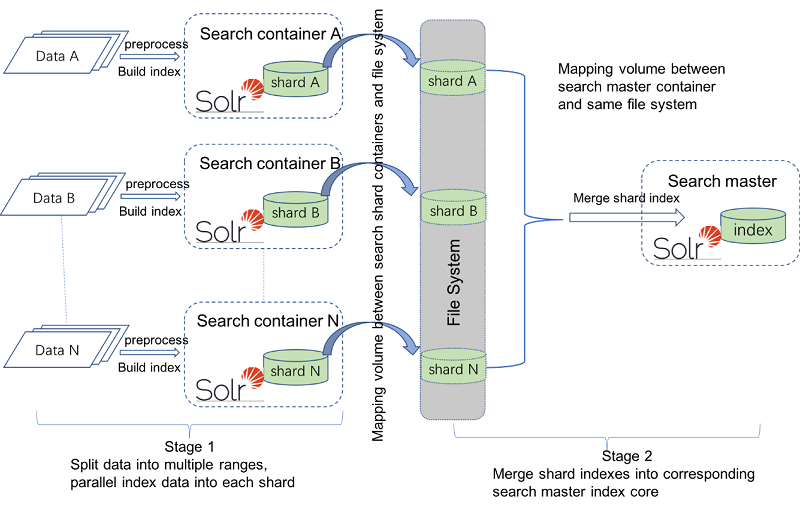
Il y a deux étapes pour indexer la fragmentation avec plusieurs JVM, comme il y en a avec une seule JVM. Dans la première étape, les données d'origine sont divisées en plusieurs plages. Chaque plage de données est prétraitée et elles sont indexées en parallèle dans les noyaux d'index d'un fragment. Dans la deuxième étape, tous les noyaux d'index des fragments sont fusionnés dans le noyau d'index correspondant du maître de recherche. Par exemple, les index de fragments structurés de CatalogEntry sont fusionnés dans l'index structuré CatalogEntry du maître de recherche et les index de fragments non structurés sont fusionnés dans le noyau d'index non structuré du maître de recherche. Pour plusieurs JVM, l'approche standard consiste à générer chaque index de fragments dans un conteneur de serveur de recherche distinct. Si les ressources système le permettent, vous pouvez configurer un serveur de recherche pour générer plusieurs index de fragments.
Quelques étapes supplémentaires sont nécessaires pour mapper les volumes entre les conteneurs et un système de fichiers extérieur. Le conteneur maître de recherche a besoin de ce mappage pour pouvoir accéder à tous les dossiers d'index de fragments.
Une fois que vous avez configuré votre environnement de fragments, vous pouvez effectuer l'indexation à chaque fragment à l'aide de l'utilitaire di-parallel-process. Le diagramme suivant montre les deux étapes de fragmentation dans plusieurs conteneurs Docker de recherche.
Procédure
- Copiez docker-compose.yml dans votre environnement de développement Renommez-le docker-compose-shardingMultiJVMs.yml.
-
Exécutez la commande suivante pour mettre en place l'environnement :
Si vous n'avez pas modifié les paramètres par défaut dans le fichier, cette commande crée trois serveurs de fragments de recherche, un serveur principal de recherche, un serveur de transactions, un conteneur DB2 et un conteneur d'utilitaire. Trois serveurs de fragments de recherche sont mappés à différents ports pour chaque conteneur. Les ports sont le port 3737docker-compose -f docker-compose-shardingMultiJVMs.yml up -dhttpet le port 3738https.Pour les serveurs de fragments de recherche, modélisez votre configuration sur l'exemple suivant :shard_a: image: search-app:latest hostname: search_shard_a environment: - WORKAREA=/shard_a - LICENSE=accept - TZ=Asia/Shanghai ports: - 3747:3737 - 3748:3738 volumes: - /shard_a depends_on: db: condition: service_healthy healthcheck: test: ["CMD", "curl", "-f", "-H", "Authorization: Basic ","http://localhost:3737/search/admin/resources/health/status?type=container"] interval: 20s timeout: 180s retries: 5Remarque : Définissez différents noms d'hôte, ports externes et dossiers externes pour différents conteneurs de fragments de recherche.Pour le conteneur maître de recherche :master: image: search-app:latest hostname: search_master environment: - SOLR_MASTER=true - WORKAREA=/search - LICENSE=accept - TZ=Asia/Shanghai ports: - 3737:3737 - 3738:3738 volumes_from: - shard_a:ro - shard_b:ro - shard_c:ro networks: default: aliases: - search depends_on: db: condition: service_healthy healthcheck: test: ["CMD", "curl", "-f", "-H", "Authorization: Basic ","http://localhost:3737/search/admin/resources/health/status?type=container"] interval: 20s timeout: 180s retries: 5Remarque : Le mappage de volume externe pour le nœud maître de recherche est configuré pour le dossier d'index de fragments, afin de permettre à l'accès du nœud maître à tous les index de fragments. -
Dans le conteneur Docker du serveur d'utilitaire, modifiez
/opt/WebSphere/CommerceServer90/properties/parallelprocess/di-parallel-process.propertiespour qu'il corresponde à votre environnement. Vous pouvez utiliser les exemples suivants comme guide.Configurez le nom d'hôte et le port pour différents serveurs de fragments comme ci-dessous.
Le nom du serveur de fragments doit être le même que le nom d'hôte/alias avec le fichier de composition Docker. b). Configurez le répertoire de base d'index de fragment comme suit :Shard.A.common.index-server-name=shard_a Shard.A.common.index-server-port=3738 … Shard.B.common.index-server-name=shard_b Shard.B.common.index-server-port=3738Shard.A.en_US.unstructured-index-core-dir=/shard_a/index/solr/MC_10001/en_US/Unstructured_A/ Shard.A.en_US.structured-index-core-dir=/shard_a/index/solr/MC_10001/en_US/CatalogEntry_A/ … Shard.B.en_US.unstructured-index-core-dir=/shard_b/index/solr/MC_10001/en_US/Unstructured_B/ Shard.B.en_US.structured-index-core-dir=/shard_b/index/solr/MC_10001/en_US/CatalogEntry_B/ Note: the directory should be absolute path inside each shard container.Vous pouvez automatiser le processus de configuration des fragments. C'est utile si, par exemple, vous vous attendez à créer un grand nombre de fragments. Le processus de fragmentation automatique configurera automatiquement des propriétés telles que preprocessing-start-range-value, preprocessing-end-range-value, index-core-name et index-core-dir.
Pour plus d'informations sur la configuration de la fragmentation automatique, voir Fichier des propriétés d'entrée de fragmentation.
-
Placez-vous dans le répertoire
/opt/WebSphere/CommerceServer90/bin. -
Exécutez la commande suivante pour effectuer une fragmentation dans plusieurs JVM.
Pour plus d'informations, voir Exécution des utilitaires à partir de Utility server Docker container../di-parallel-process.sh /opt/WebSphere/CommerceServer90/properties/parallelprocess/di-parallel-process.properties