Indexation du contenu de site avec HCL Commerce Search
HCL Commerce contient du contenu non géré, tel que le contenu de site, qui doit être exploré à l'aide de l'explorateur de contenu de site. Le contenu non structuré destiné à la production doit être publié séparément, car il ne fait pas partie de la propagation de transfert. Une fois que le contenu statique est copié vers l'emplacement correct, une réindexation manuelle du contenu de site à partir du système de production est requise au niveau du répéteur.
Explorateur de contenu de site
L'explorateur de contenu de site exploite les fichiers HTML et les autres fichiers du site à partir des magasins type HCL Commerce afin de faciliter le remplissage de l'index de recherche de contenu de site.
L'explorateur de contenu de site capture le contenu de site, le met en cache dans un répertoire local et place les entrées dans le fichier manifest.txt. Il mappe ensuite les emplacements physiques à leurs URL correspondantes. L'indexeur utilise le fichier du manifeste pour récupérer les emplacements de fichiers temporaires physiques, crée les index et, après segmentation, associe les URL de fichier à l'enregistrement d'index
La table suivante met en évidence le flux de travaux de l'explorateur de contenu de site :
| Action de l'explorateur de contenu de site | Flux de travaux de l'explorateur de contenu de site |
|---|---|
| L'explorateur de contenu de site s'exécute | L'explorateur de contenu de site :
|
| L'explorateur de contenu de site crée l'arborescence de répertoires. | L'explorateur de contenu de site :
Le diagramme suivant représente une vue d'ensemble de haut niveau de l'arborescence de répertoires de l'explorateur de contenu de site : 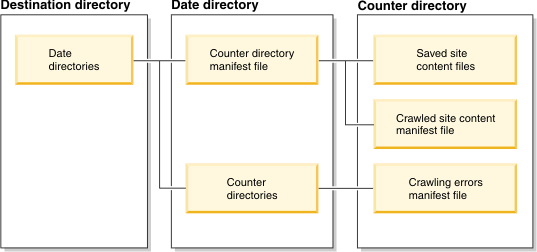 |
| L'explorateur de contenu de site analyse le contenu de site | L'explorateur de contenu de site :
|
| L'explorateur de contenu de site termine son exécution | Si l'explorateur de contenu de site est réussi, il :
|
Intégration de l'explorateur de contenu de site et de l'indexeur
L'indexeur agit en tant que service vis-à-vis de l'explorateur de contenu de site. Une fois chaque l'exécution de chaque explorateur terminée, l'explorateur de contenu de site invoque directement une requête au serveur HCL Commerce Search avec l'URL spécifique. Le processus d'indexation démarre alors de façon asynchrone. L'URL type ressemble à l'exemple d'URL suivant :
- http://localhost:3737/solr/MC_$catalogId_CatalogEntry_Unstructured_$localename/webdataimport?command=full-import&storeId=$storeId