Tutoriel : Ingestion de fichier Elasticsearch
Ingérer les données non structurées pour les fichiers MS Word .docx, PDF, Excel.xlsx, CSV, .txt et les fichiers HTML, y compris les métadonnées de support.
About this task
Procedure
-
Dans le conteneur Elasticsearch, activez la pièce jointe de support (plug-in) docker.elastic.co/elasticsearch/elasticsearch:7.x.0.
- Dans la fenêtre du terminal, exécutez la commande suivante :
docker exec -it -u 0 commerce_elasticsearch_1 bash - A partir du terminal bash de conteneur, exécutez la commande suivante :
elasticsearch-plugin install ingest-attachment - Redémarrez le Docker Elasticsearch :
docker restart commerce_elasticsearch_1 - Après avoir ajouté la commande de pièce jointe au fichier Dockerfile, créez une image Elasticsearch à partir de l'image de base.
- Dans la fenêtre du terminal, exécutez la commande suivante :
-
Créez le répertoire commerce/search-nifi-app:9.1.x.0. dans le conteneur NiFi en utilisant les commandes suivantes :
-docker exec -it -u 0 commerce_nifi_1 bash -mkdir /opt/nifi/extDocs/ chown nifi:nifi /opt/nifi/extDocsPour copier les fichiers dans le répertoire que vous souhaitez ingérer dans Elasticsearch, exécutez la commande suivante sur la ligne de commande :
Dans cet exemple, les fichiers suivants seront utilisés : SampleDocs-travel-laptop.docx et SampleDocs-office-laptop.ppt.docker cp /home/ingestfiles/. commerce_nifi_1:/opt/nifi/extDocs/. -
Importer les connecteurs suivants dans le registre NiFi commerce/search-registry-app:9.1.x.0.
-
docker cp custom-UnstructuredIndexSchemaUpdateConnector-attachment.json commerce_registry_1:/opt/nifi-registry/flows/.
Pour plus d'informations, voir custom-UnstructuredIndexSchemaUpdateConnector-attachment.json.
-
docker cp custom-UnstructuredIndexSchemaUpdate.json commerce_registry_1:/opt/nifi-registry/flows/.
Pour plus d'informations, voir custom-UnstructuredIndexSchemaUpdate.json.
-
docker cp custom-UnstructuredIndexDatabaseConnectorPipe-Attachment.json commerce_registry_1:/opt/nifi-registry/flows/.
Pour plus d'informations, voir custom-UnstructuredIndexDatabaseConnectorPipe-Attachment.json.
Ouvrez le conteneur de registre NiFi et exécutez la commande suivante :docker exec -it -u 0 commerce_registry_1 bashExécutez les commandes suivantes à partir du terminal de registre.- /opt/nifi-registry/scripts/import_flow.sh custom-UnstructuredIndexSchemaUpdateConnector-attachment /opt/nifi-registry/flows/custom-UnstructuredIndexSchemaUpdateConnector-attachment.json
- /opt/nifi-registry/scripts/import_flow.sh custom-UnstructuredIndexSchemaUpdate /opt/nifi-registry/flows/custom-UnstructuredIndexSchemaUpdate.json
- /opt/nifi-registry/scripts/import_flow.sh custom-UnstructuredIndexDatabaseConnectorPipe-Attachment /opt/nifi-registry/flows/custom-UnstructuredIndexDatabaseConnectorPipe-Attachment.json
-
docker cp custom-UnstructuredIndexSchemaUpdateConnector-attachment.json commerce_registry_1:/opt/nifi-registry/flows/.
-
A l'aide de Postman, créez un connecteur Ingest. Pour plus d'informations, voir Interface utilisateur swagger.
Ouvrez le Postman et entrez les détails suivants :
- URL - http://localhost:30800/connectors
- Méthode = POST
- Corps = le corps JSON suivant :
{ "name": "auth.unstructured", "description": "This is the connector for the unstructured processing", "pipes": [ { "name": "custom-UnstructuredIndexSchemaUpdate" }, { "name": "custom-UnstructuredIndexSchemaUpdateConnector-attachment" }, { "name": "custom-UnstructuredIndexDatabaseConnectorPipe-Attachment", "properties": [ { "name": "Database Driver Location(s)", "value": "${AUTH_JDBC_DRIVER_LOCATION}", "scope": { "name": "Database Connection Pool", "type": "CONTROLLER_SERVICE" } }, { "name": "Database Connection URL", "value": "${AUTH_JDBC_URL}", "scope": { "name": "Database Connection Pool", "type": "CONTROLLER_SERVICE" } }, { "name": "Database User", "value": "${AUTH_JDBC_USER_NAME}", "scope": { "name": "Database Connection Pool", "type": "CONTROLLER_SERVICE" } }, { "name": "Password", "value": "${AUTH_JDBC_USER_PASSWORD}", "scope": { "name": "Database Connection Pool", "type": "CONTROLLER_SERVICE" } } ] }, { "name": "Terminal" } ] }
-
Ajoutez le groupe de processus à l'interface utilisateur NiFi et liez les ports d'entrée/sortie comme illustré dans l'image ci-dessous. Quatre canaux de groupe de processus seront disponibles dans NiFi après l'exécution du connecteur :

- a) custom-UnstructuredIndexSchemaUpdate
- Ce groupe de processus est utilisé par Elasticsearch pour activer les paramètres de pièce jointe. Si le paramètre de pièce jointe est déjà activé, il sera ignoré. Modifiez le nom de l'index dans le fichier de propriétés de nom de schéma pour utiliser un schéma existant.
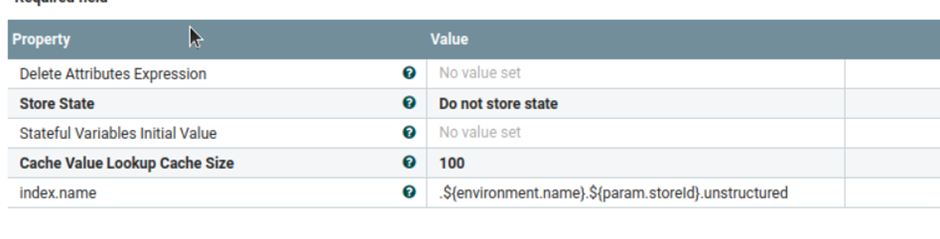
- b) custom-UnstructuredIndexSchemaUpdateConnector-attachment
- Ce groupe de processus est utilisé par Elasticsearch pour activer les paramètres de pièce jointe. Si les paramètres de pièce jointe sont déjà accessibles, ils seront ignorés. Les paramètres suivants sont utilisés par défaut, mais vous pouvez les mettre à jour pour qu'ils correspondent à vos besoins. Dans le processeur Définir une pièce jointe non structurée, param.attach est accessible.
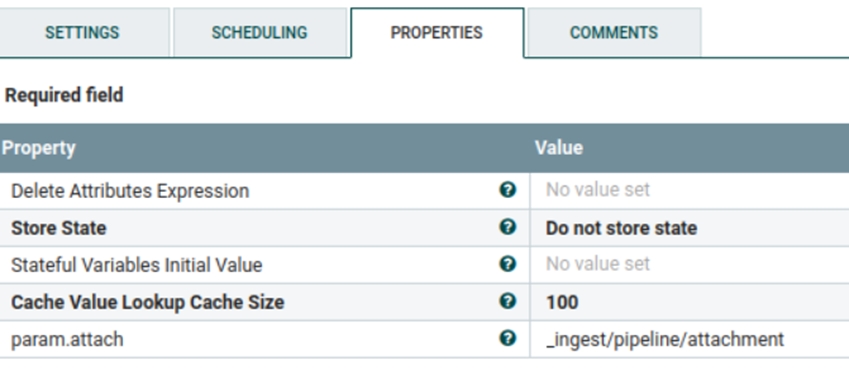 Le code json suivant est disponible dans le processeur Remplir le schéma d'index non structuré. Ici, vous pouvez ajouter ou mettre à jour un mot clé. Ce mot clé sera utilisé pour ingérer et rechercher des données non structurées.
Le code json suivant est disponible dans le processeur Remplir le schéma d'index non structuré. Ici, vous pouvez ajouter ou mettre à jour un mot clé. Ce mot clé sera utilisé pour ingérer et rechercher des données non structurées.{ "description" : "Extract attachment information", "processors" : [ { "attachment" : { "field" : "data", "indexed_chars_field" : "max_size", "properties": [ "content", "title", "keywords", "content_type", "content_length" ] } } ] } - c) custom-UnstructuredIndexDatabaseConnectorPipe-Attachment
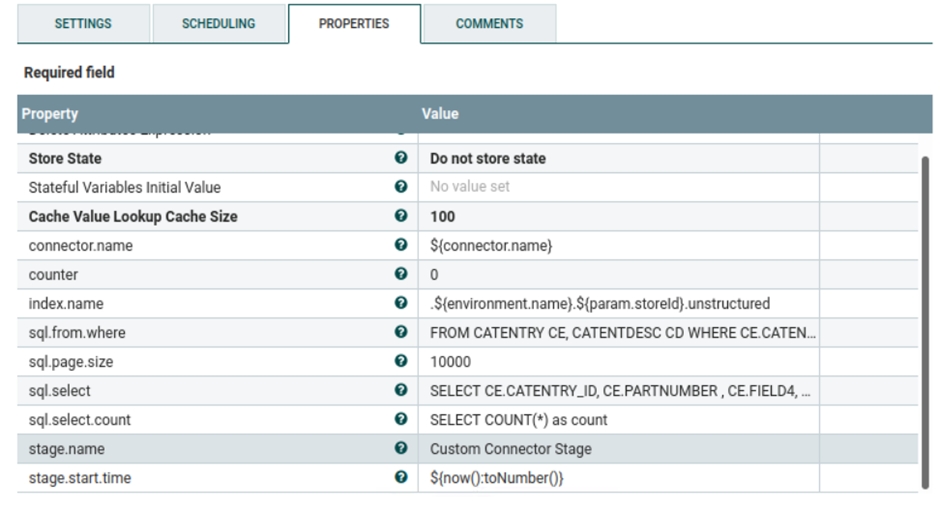
- Ce groupe de processus est chargé d'extraire les emplacements de fichier de la base de données, de lire le contenu du fichier à partir du répertoire spécifié de la base de données, de l'encoder en base64 et de l'ingérer dans Elasticsearch. Ce groupe de processus utilise plusieurs processeurs pour importer des fichiers dans Elasticsearch.
Le processeur Définir un attribut permet de spécifier le paramètre qui sera utilisé pour traiter le fichier, que vous pouvez modifier selon vos besoins.
- d) Terminal
- Ce groupe de processus termine le flux de processus et est responsable de la fin de la sortie du processus précédent.
-
Exécutez les requêtes suivantes pour définir l'emplacement du fichier dans Catentry.field4 (ce tableau est actuellement utilisé dans le groupe de processus). Vous pouvez modifier la requête et ajouter plusieurs transactions si nécessaire pour définir l'emplacement du fichier pour les entrées de catalogue.
UPDATE catentry SET FIELD4 = '/opt/nifi/extDocs/SampleDocs-travel-laptop.docx' WHERE PARTNUMBER = 'CLA022_2203' UPDATE catentry SET FIELD4 = '/opt/nifi/extDocs/SampleDocs-office-laptop.ppt' WHERE PARTNUMBER = 'CLA022_2205'Note: Si vous souhaitez définir l'emplacement du fichier dans un autre tableau, vous devrez modifier les propriétés suivantes dans le processeur Définir un attribut sous custom-UnstructuredIndexDatabaseConnectorPipe-Attachment. Actuellement, les requêtes ci-dessous sont utilisées. Vous pouvez les mettre à jour ou les modifier selon vos besoins.
Actuellement, les requêtes ci-dessous sont utilisées. Vous pouvez les mettre à jour ou les modifier selon vos besoins.SELECT COUNT(*) as count FROM CATENTRY CE, CATENTDESC CD WHERE CE.CATENTRY_ID = CD.CATENTRY_ID AND CD.LANGUAGE_ID =-1 AND CE.MARKFORDELETE =0 AND CE.BUYABLE =1 AND CD.PUBLISHED =1 AND ce.FIELD4 IS not NULL AND CE.CATENTRY_ID IN (SELECT C.CATENTRY_ID FROM CATGPENREL R, CATENTRY C WHERE R.CATALOG_ID IN (SELECT CATALOG_ID FROM STORECAT WHERE STOREENT_ID IN (SELECT RELATEDSTORE_ID FROM STOREREL WHERE STATE = 1 AND STRELTYP_ID = -4 AND STORE_ID = ${param.storeId})) AND R.CATENTRY_ID = C.CATENTRY_ID AND C.MARKFORDELETE = 0 AND C.CATENTTYPE_ID <> 'ItemBean') SELECT CE.CATENTRY_ID, CE.PARTNUMBER , CE.FIELD4, CD.NAME, CD.SHORTDESCRIPTION , CD.PUBLISHED FROM CATENTRY CE, CATENTDESC CD WHERE CE.CATENTRY_ID = CD.CATENTRY_ID AND CD.LANGUAGE_ID =-1 AND CE.MARKFORDELETE =0 AND CE.BUYABLE =1 AND CD.PUBLISHED =1 AND ce.FIELD4 IS not NULL AND CE.CATENTRY_ID IN (SELECT C.CATENTRY_ID FROM CATGPENREL R, CATENTRY C WHERE R.CATALOG_ID IN (SELECT CATALOG_ID FROM STORECAT WHERE STOREENT_ID IN (SELECT RELATEDSTORE_ID FROM STOREREL WHERE STATE = 1 AND STRELTYP_ID = -4 AND STORE_ID = ${param.storeId})) AND R.CATENTRY_ID = C.CATENTRY_ID AND C.MARKFORDELETE = 0 AND C.CATENTTYPE_ID <> 'ItemBean')Note: Si vous souhaitez mettre à jour le nom du schéma où la pièce jointe du fichier sera ingérée, modifiez les propriétés suivantes dans le processeur Définir un attribut sous custom-UnstructuredIndexDatabaseConnectorPipe-Attachment.
-
Connectez le groupe de processus auth.unstructured - custom-UnstructuredIndexSchemaUpdate au groupe de processus Service de routage avec INPUT défini sur auth.unstructured.
Note: Si la procédure de connexion est suivie, ce processus doit déjà être lié au service de routage. Assurez-vous que la route auth.unstructured fonctionne.
-
Accédez au groupe de processus suivant.

- Sélectionnez le processeur Exécuter SQL.
- Cliquez avec le bouton droit de la souris et sélectionnez Afficher la configuration.
- Sélectionnez le bouton Flèche sur le côté droit de la propriété suivante.

- Assurez-vous que le service de pool Connexion à la base de données est activé.

-
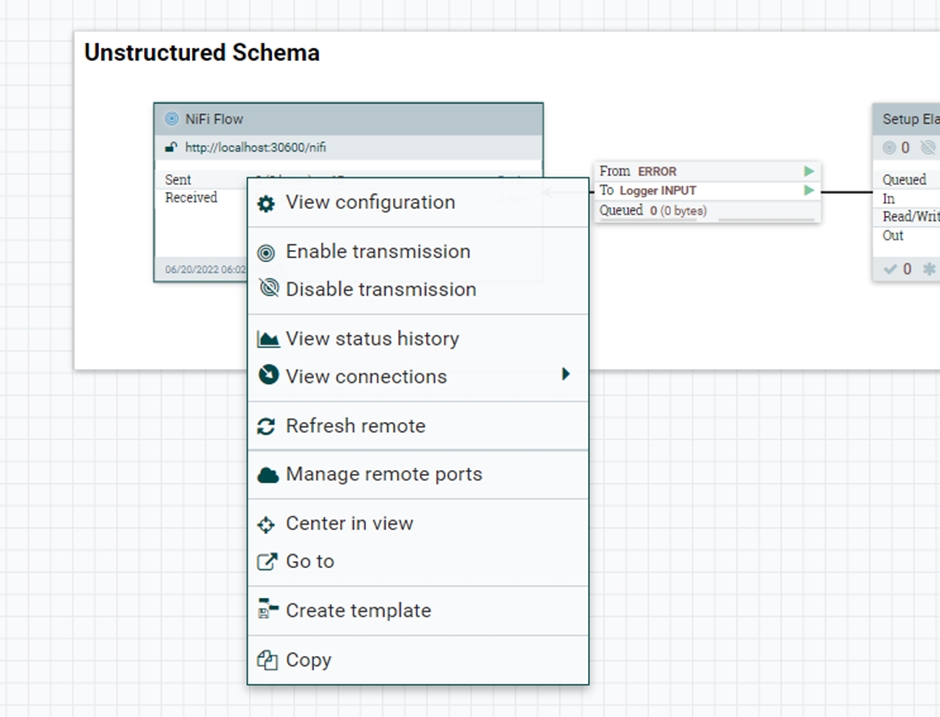
Démarrez chacun des quatre groupes de processus, puis accédez à chacun d'eux et cliquez avec le bouton droit de la souris sur le flux NiFi, puis sélectionnez Activer la transmission..
Note: Il est possible que les transmissions aient déjà été activées.
-
Après avoir démarré le groupe de processus, exécutez l'URL suivante à partir de Postman.
POST- https://localhost:5443/wcs/resources/admin/index/dataImport/build?connectorId=auth.unstructured&storeId=1Pour vérifier le statut :GET- https://localhost:5443/wcs/resources/admin/index/dataImport/status?jobStatusId=1036 -
Vous pouvez désormais valider les données non structurées indexées et transmettre le mot clé que vous avez spécifié lors de la configuration de la pièce jointe :
POST - localhost:30200/.auth.1.unstructured/_searchCorps : Avec contenu disponible dans le fichier.{ "query": { "bool": { "must": [ { "query_string": { "query": "lightweight" } } ] } } }Corps – avec SKU (numéro de référence).{ "query": { "bool": { "must": [ { "query_string": { "query": "CLA022_2205" } } ] } } }Corps – avec l'extension de fichier.{ "query": { "bool": { "must": [ { "query_string": { "query": "docx" } } ] } } }