Indexation avec propagation de transfert
Lors de l'indexation avec la propagation de transfert, les utilisateurs professionnels appliquent des modifications à une zone de transfert, qui est ensuite propagée dans l'environnement de production par les administrateurs informatiques. Un répéteur d'index est utilisé pour capturer le contenu de l'index le plus récemment déployé, tout en servant de sauvegarde.
En cas d'application d'un changement d'urgence, le répéteur peut être utilisé pour réindexer au lieu de s'occuper directement des subordonnés de recherche qui sont en production. Cela permet d'éviter toute interruption potentielle due à la corruption lors de la réindexation. Autrement dit, les subordonnés de recherche qui sont en production sont toujours traités comme des serveurs subordonnés, avec la réindexation toujours au niveau du répéteur. Une fois la réindexation terminée avec succès, les modifications delta sont répliquées dans les nœuds subordonnés des subordonnés de recherche en production. Cette réplication d'index semble transparente pour les administrateurs car, une fois la réplication terminée dans le système de production, la nouvelle version de l'index de recherche devient automatiquement active.
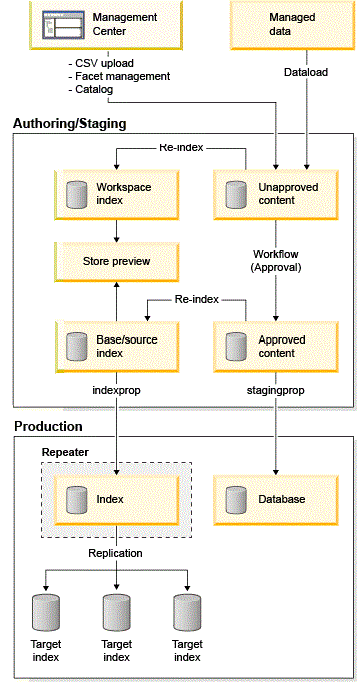
Flux d'index de recherche avec propagation du transfert et index d'espace de travail
Chronologie des événements
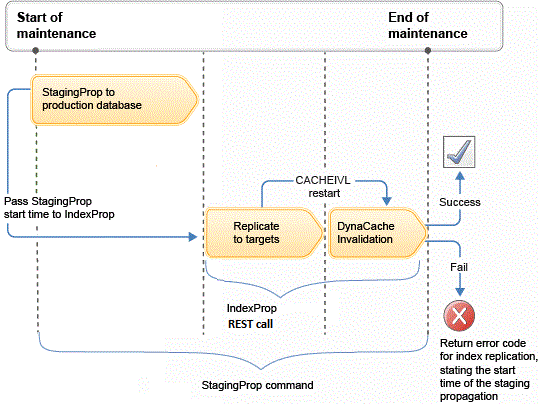
Où :
- Une heure de début est transmise en tant que paramètre à l'API REST indexprop au moment où la commande est émise par un administrateur informatique. Pour plus d'informations sur les API, voir Propagation de l'index de recherche.
- Cette heure de début définit la période de début d'invalidation du cache. En règle générale, le début de l'opération de propagation de transfert.
- L'API REST indexprop peut être utilisée pour surveiller l'avancement de la réplication d'index sur tous les serveurs subordonnés de recherche en production.
- Une fois toutes les réplications d'index terminées avec succès, l'API REST indexprop est appelée pour émettre une instruction d'invalidation du cache en insérant une entrée de type redémarrage dans la table CACHEIVL, en utilisant le paramètre de début d'heure fourni comme heure de démarrage de l'invalidation du cache.
- Les modifications de catalogue sont apportées à HCL Commerce via le Centre de gestion ou l'utilitaire Chargement des données dans un environnement de transfert. Les utilisateurs professionnels testent et prévisualisent tous les changements de cet environnement de préproduction avant de les publier dans les environnements de production. Dans ce scénario, il existe un index de recherche dédié pour l'environnement de transfert et la procédure de mise à jour delta pour synchroniser les modifications de catalogue est la même que dans un environnement autre qu'un environnement de transfert.
- L'index de recherche de l'espace de travail est utilisé pour que les utilisateurs professionnels prévisualisent les modifications apportées dans le Centre de gestion, par exemple, en chargeant des fichiers CSV ou d'autres modifications de catalogue.
- Lorsque les utilisateurs professionnels sont satisfaits de leurs modifications, les données sont publiées en production à l'aide de la propagation de transfert (stagingprop). L'utilitaire est utilisé par les administrateurs informatiques afin de coordonner les tâches suivantes lors de la publication en production :
- stagingprop
- Utilisé pour les données gérées, telles que le catalogue et la configuration.
- L'API REST indexprop est utilisée pour propager l'index HCL Commerce Search :
- L'appel RESTful indexprop est utilisé par les administrateurs informatiques pour initier la réplication d'index de recherche de l'environnement de transfert vers le répéteur et effectuer l'invalidation du cache pour HCL Commerce Search en production. Pour plus d'informations, voir Propagation de l'index HCL Commerce Search avec le répéteur.
Pour plus d'informations sur la mise à jour du fichier de configuration de réplication (replication.csv), téléchargez et extrayez l'archive suivante qui contient des exemples de fichiers CSV sdsearch_replication_samples.zip.Remarque : Lors de l'exécution du travail du planificateur UpdateSearchIndex :- Le travail du planificateur UpdateSearchIndex n'appelle pas l'API indexprop par défaut. Par conséquent, replication.csv n'a pas besoin d'être copié vers un emplacement situé en dehors du répertoire d'origine de Solr.
- Le fichier replication.csv ne doit pas être copié vers un emplacement situé en dehors du répertoire d'origine de Solr. Cela évite la réplication qui a lieu automatiquement chaque fois que le travail du planificateur UpdateSearchIndex est exécuté. Par exemple, copiez replication.csv dans le répertoire WC_installdir/instances/instance_name/search. Ensuite, transmettez la valeur -solrHome lors de l'appel de l'API REST indexprop.
- Le répéteur d'index de recherche est utilisé à la fois comme maître et subordonné pour la réplication de recherche.
Il est utilisé comme subordonné lors de la réplication avec l'index de recherche de transfert, où l'index de recherche de transfert est le maître et le répéteur est le subordonné agissant comme une sauvegarde de l'index de recherche en production. Une fois la première réplication terminée à partir du transfert, le répéteur communique les modifications apportées à ses nœuds subordonnés en production.
Le répéteur devient alors le maître, où tous les nœuds des subordonnés de recherche sont configurés pour interroger les changements du répéteur sur un intervalle de temps fixe régulier et préconfiguré. Cet intervalle de temps est défini dans le fichier solrconfig.xml sous
replication.La réplication entre le répéteur et tous les subordonnés de recherche en production peut être automatisée, car les données indexées dans le répéteur correspondent toujours aux données indexées en production. Le répéteur d'index de recherche doit être subordonné au serveur de recherche de transfert et maître du serveur de recherche en production.
Important : Le répéteur doit résider en production, car il s'appuie sur la base de données de production pour effectuer des mises à jour d'urgence. - Les considérations suivantes doivent être prises en compte lorsque les données de catalogue et les fichiers d'actifs sont publiés en production :
- La prochaine fois que la réplication se produit entre l'index de recherche de production et le répéteur.
- Le temps approximatif que la réplication de l'index pourrait prendre pour s'achever.
- L'invalidation du cache pour la vitrine doit être effectuée avant que les modifications mises à jour ne soient visibles dans la production.
- Une invalidation de cache automatisée peut être effectuée à l'aide de l'appel RESTful indexprop.
Lorsque vous utilisez l'option des temps de redémarrage indexprop pour effectuer la nouvelle invalidation, une fois toutes les réplications d'index terminées avec succès, l'API REST indexprop est appelée pour émettre une instruction d'invalidation du cache en insérant une entrée de type redémarrage dans la table CACHEIVL, en utilisant le paramètre de début d'heure fourni comme heure de démarrage de l'invalidation du cache. Cela permet à la commande du planificateur DynaCacheInvalidation d'effectuer à nouveau la même invalidation, à partir du paramètre d'heure de début donné. Cela empêche l'invalidation précoce, ce qui entraînerait une nouvelle mise en cache du contenu obsolète avant que les dernières modifications d'index ne deviennent disponibles. Ces entrées d'invalidation dans la table CACHEIVL peuvent être des ID de dépendance utilisés pour l'invalidation du cache de fragments JSP ou l'invalidation du cache d'objets de données.
- Une invalidation de cache automatisée peut être effectuée à l'aide de l'appel RESTful indexprop.