Réglage de Chargement d'index
Vous pouvez régler Chargement d'index pour des performances optimales en configurant les valeurs réglables et en évaluant les résultats.
Pourquoi et quand exécuter cette tâche
Chargement d'index commence par une seule source d'entrée, utilise un traitement sur plusieurs unités d'exécution et se termine par l'écriture d'un seul service de lot sur un seul index.
Le diagramme suivant montre les zones ajustables disponibles de Chargement d'index :
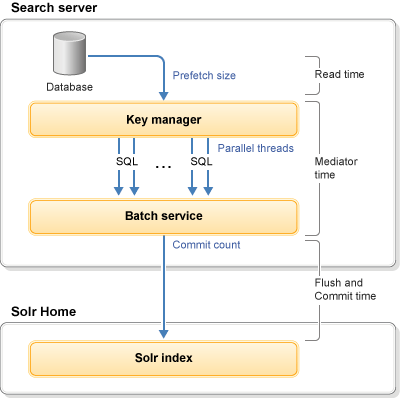
Lorsqu'il les principales zones de réglage suivantes existent :
- Unités d'exécution parallèles
- Nombre d'unités d'exécution à utiliser pour l'indexation parallèle.
- Taille de lecture anticipée
- Nombre de lignes à renvoyer pour chaque appel de base de données (SQL).
- Le nombre de validations (validation en dur)
- Le nombre de documents d'index à conserver en mémoire avant d'écrire sur l'index Solr.
- Nombre de lots (validation temporaire)
- Le nombre de documents d'index à conserver dans la mémoire tampon d'exécution de Chargement d'index avant de les envoyer vers la pile de mémoire Solr.
Plus la valeur du nombre de lots est élevée, plus le débit d'indexation est élevé, mais plus le nombre de résultats non pertinent généré est élevé.
Les jauges de mesure suivantes permettent de déterminer les performances et peuvent être affichées à partir de la page de statut de Chargement d'index :
- Taux
- Le nombre moyen de documents indexés par seconde sur la pile Solr.
- Temps de lecture
- La durée moyenne passée à exécuter des appels SQL.
- Temps de vidage
- La durée moyenne passée sur les validations temporaires Solr.
- Heure de validation
- La durée moyenne passée sur les validations en dur Solr.
- Temps d'indexation
- Le temps global de bout en bout consacré à l'indexation.
Vous pouvez utiliser ces statistiques pour régler les principales zones réglables de Chargement d'index.
Le diagramme suivant montre le fonctionnement de Chargement d'index avec des ensembles de données et comment régler le nombre de préextractions, d'unités d'exécution et de lots pour les performances :
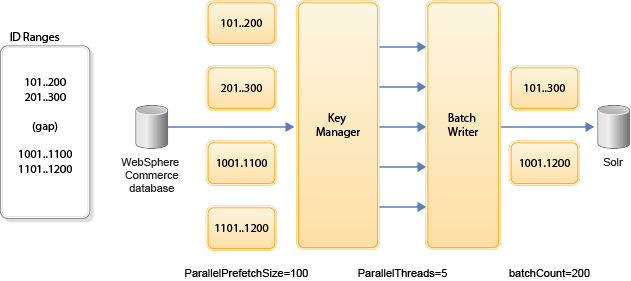
Où :
Où :
- Le gestionnaire de clés utilise la préextraction pour obtenir de petits ensembles de données depuis la base de données et les distribue uniformément sur toutes les unités d'exécution de travail. Cette technique permet d'éviter de surcharger la base de données lors du traitement d'un jeu de résultats de très grande taille. De très grandes tailles de jeux de résultats peuvent même ne pas tenir dans le journal des transactions de la base de données. En utilisant de plus petits ensembles de données, le temps de requête est amélioré et la charge de travail de l'unité d'exécution Chargement d'index est répartie plus uniformément.
- La taille de la préextraction (ParallelPrefetchSize) définit la taille du bloc lookahead, tandis que l'instruction SQL de plage suivante (ParallelNextRangeSQL) est utilisée pour traiter les grands écarts de plages d'ID vides. L'instruction SQL de plage suivante n'est utilisée que lorsque lookahead ne contient pas de données. C'est-à-dire lorsqu'un écart est détecté. Cette instruction SQL est utilisée pour renvoyer l'ID disponible suivant et évite donc une exploration inutile.
- La taille de préextraction, le nombre d'unités d'exécution, les plages et le nombre de lots sont tous des facteurs à prendre en compte lors du réglage de Chargement d'index.
Procédure
-
Utilisez la technique de réglage générale suivante pour obtenir des performances optimales de Chargement d'index :
- Commencez avec une fenêtre de temps fixe ou un petit ensemble de données à régler avant de passer à l'échelle supérieure. Cela permet de calibrer les tâches avec votre matériel.
- Déterminez la taille optimale de la préextraction, lorsque le temps de lecture est légèrement supérieur à 0, et idéalement lorsque le temps de lecture total écoulé est inférieur à 1 minute. La taille de la préextraction est utilisée pour contrôler le temps de lecture.
- Atteignez le meilleur débit, lorsque les temps de vidage et de validation sont proches de 0. C'est-à-dire lorsque l'index Solr global est de 0. Le nombre de lots est utilisé pour contrôler le temps de vidage (validation temporaire). Le nombre de validations est utilisé pour contrôler le temps de validation.
- Lorsque les paramètres optimaux sont trouvés, réduisez le nombre d'unités d'exécution jusqu'à ce que le débit baisse. Cette technique permet de trouver la puissance maximale à définir sur chaque pipeline.
-
Utilisez les paramètres généraux suivants pour maximiser le taux d'indexation :
- Utilisez une JVM 64 bits et attribuez-lui autant de segments de mémoire que possible pour réduire la récupération de place globale.
- Utilisez une plage de clés codées en dur, afin de Chargement d'index ne perde pas de temps à examiner les plages vides.
- Utilisez ThreadLaunchTimeDelay pour éviter de traiter toutes les unités d'exécution d'indexation en parallèle au démarrage et de surcharger les ressources de base de données.
-
Réglez les valeurs suivantes pour déterminer comment Chargement d'index fonctionne avec des ensembles de données :
- Réglez la taille de la préextraction pour contrôler le nombre de lignes lues à partir de la source de données à la fois. Cette valeur doit être réglée pour équilibrer le chargement de la base de données par rapport à la disponibilité des données pour les unités d'exécution de travail.
- Réglez le nombre d'unités d'exécution pour contrôler le nombre d'unités d'exécution parallèles qui traitent ces lignes. Cette valeur doit être réglée pour équilibrer la charge globale de l'UC tout en ayant la possibilité de traiter les données en parallèle.
- Réglez ParallelNextRangeSQL pour éviter les écarts dans les plages d'ID d'entrée. Chaque plage est récupérée et distribuée sur les unités d'exécution de travail.
- Réglez le nombre de lots pour contrôler les tailles des lots envoyés à Solr.
-
Réglez les attributs de performance configurables dans les fichiers de configuration wc-indexload-profileName.xml et wc-indexload-businessobject.xml de Chargement d'index.
Pour plus d'informations, voir Fichiers de configuration du chargement d'index pour l'indexation à partir de la base de données.
-
Sélectionnez l'une des méthodes de réglage suivantes qui affectent le taux d'indexation global et ajustez les paramètres de réglage en conséquence.
Remarque : L'association de méthodes de réglage multiples peut entraîner des résultats imprévisibles et avoir un impact négatif sur le taux d'indexation global.
Option Description Recommandation : Configuration basée sur l'allocation de mémoire Définissez les valeurs suivantes dans le fichier solrconfig.xml. Lucene ramBufferSizeMBbatchSizedisable commitCount
Configuration de Chargement d'index basée sur le nombre de documents Définissez les valeurs suivantes lors de la configuration de Chargement d'index : batchSizecommitCount
Configuration Solr basée sur le nombre de documents Définissez les valeurs suivantes dans le fichier solrconfig.xml. maxDocs of Solr autoCommitbatchSize- désactiver
commitCount
Configuration Lucene basée sur le nombre de documents Définissez les valeurs suivantes dans le fichier solrconfig.xml. Lucene maxBufferedDocsbatchSize- désactiver
commitCount
Où :- Lucene ramBufferSizeMB
- Définit la quantité d'espace mémoire, en Mo, à utiliser pour la mise en mémoire tampon des documents indexés. Une fois que les mises à jour de documents accumulées dépassent l'espace de mémoire alloué, un vidage de disque se produit. Cela peut également créer de nouveaux segments ou déclencher une fusion de segment d'index.
- Lucene maxBufferedDocs
- Définit le nombre de mises à jour de documents effectuées au niveau de la mémoire tampon avant qu'elles ne soient vidées en tant que nouveau segment. Une fois que les mises à jour de documents accumulées dépassent cette valeur, un vidage de disque se produit. Cela peut également créer de nouveaux segments ou déclencher une fusion de segment d'index.
- maxDocs de Solr autoCommit
- Un paramètre de niveau Solr qui définit le nombre maximal de documents indexés à mettre en mémoire avant qu'un vidage de disque ne se produise. Par rapport au niveau maxBufferedDocs de Lucene, ce paramètre ne garantit pas un vidage de disque de bas niveau. Lorsque la valeur Lucene maxBufferedDocs est supérieure à cette taille autoCommit, ce paramètre n'est pas pertinent.
- Chargement d'index - commitCount
- Définit le nombre maximal de documents non validés à mettre en mémoire avant qu'un vidage de disque ne se produise. Il s'agit d'un contrôle de niveau l'application. Il vide au stockage physique à l'aide de l'API de validation en dur Solr. Définissez la valeur sur 0 pour le désactiver.
- Chargement d'index - batchSize
- Définit le nombre de documents à garder en mémoire avant d'effectuer une validation temporaire dans Solr. Cette action ne garantit pas le vidage du disque, car la décision finale dépend également des valeurs de maxDocs, et des valeurs Lucene ramBufferSizeMB et maxBufferedDocs, si l'une d'entre elles est configurée. Définissez la valeur sur 0 pour le désactiver.
Remarque : La valeur du nombre de validations remplace la valeur de taille de lot lorsque la taille du lot est supérieure au nombre de validations. -
Surveillez Chargement d'index et utilisez les métriques lors de l'indexation pour affiner les paramètres de réglage et améliorer le débit des performances.
Pour plus d'informations, voir Surveillance de Chargement d'index.