
Optimisation des performances de recherche basée sur Elasticsearch, partie II
Plusieurs facteurs influencent les performances de la génération de l'index de recherche, y compris l'encombrement matériel, la taille du catalogue et la richesse des données/cardinalités du dictionnaire d'attributs. Il est essentiel de comprendre les goulots d'étranglement et la façon dont ils s'expriment dans l'ensemble du processus pour affiner la solution de recherche.
Informations de base
- Extraction de données.
- Traitement/Transformation de données.
- Chargement de données.
- Extraction de groupe de données : extrayez des données de la base de données ou d'Elasticsearch.
- Traitement de groupe de données : Pour les données extraites : générez, mettez à jour ou copiez les documents d'index.
- Chargement du groupe de données : chargez le document d'index dans Elasticsearch.
Chaque groupe a une influence sur la vitesse et l'efficacité du processus de génération d'index. Le groupe de données d'extraction, par exemple, contrôle la taille du fichier de flux (taille du compartiment) et la fréquence d'exécution de la requête (taille de défilement de la page). Vous pouvez optimiser la charge utile et le coût d'extraction à partir de la base de données, en tant que bloc de données de processus NiFi en tant qu'unité, en modifiant ces variables. La taille du fichier de flux affecte les performances de chargement Elasticsearch. Les structures complexes et volumineuses peuvent prendre plus de temps à analyser pour Elasticsearch, ce qui entraîne une mauvaise évolutivité.
Le groupe de données de traitement contrôle la quantité de travail que NiFi peut effectuer. Par exemple, vous pouvez réguler le nombre de fichiers de flux pouvant être traités simultanément en contrôlant le nombre d'unités d'exécution du processeur. Cela augmente la vitesse de traitement d'un processeur standard, en améliorant potentiellement l'empilement de fichier de flux devant le processeur. Le processeur NLP, par exemple, est un processeur typique qui bénéficie considérablement des unités d'exécution supplémentaires. Vous pouvez contrôler le nombre de connexions à Elasticsearch que vous effectuez simultanément à l'aide du processeur de type de mise à jour en masse plus spécialisé, ce qui vous permet d'importer plus de données dans Elasticsearch.
Ces scénarios seront examinés plus en détail dans Interprétation des modèles et optimisation de la solution de recherche à l'aide d'exemples et de données réels.
Exigences requises en matière d'infrastructure
Les exigences en matière d'infrastructure du produit sont bien définies et, bien que NiFi/Elasticsearch puisse fonctionner sur un encombrement réduit, les performances peuvent en souffrir. Vous avez besoin d'une bonne bande passante d'E/S sur l'infrastructure NiFi et Elasticsearch, ainsi que d'une bonne quantité de mémoire pour l'allocation de mémoire native Java et de segment Java, et de préférence, de mémoire suffisante pour la mise en cache de fichiers. Cette dernière peut avoir besoin d'être spécifiée dans le pod, car elle garantit que le système d'exploitation dispose de suffisamment de RAM supplémentaire pour le service.
Variables réglables clés
Les variables réglables clés suivantes peuvent être ajustées pour améliorer le temps de traitement global :
Nombre d'unités d'exécution du processeur (tâches simultanées)
Le processeur par défaut exécute une unité d'exécution unique à la fois, en traitant un fichier de flux à la fois. Si le traitement simultané est souhaité, le nombre de tâches simultanées qu'il peut effectuer peut être ajusté. Définissez le nombre d'unités d'exécution pour le groupe de processus en modifiant la valeur Tâches simultanées du processeur (sous l'onglet Configuration du processeur ou Planification).
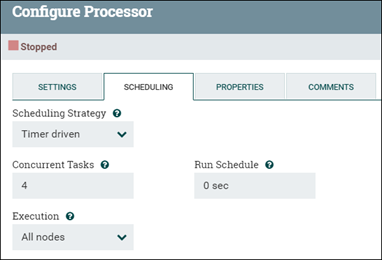
Le débit peut être amélioré si une UC peut effectuer plusieurs tâches en augmentant le nombre d'unités d'exécution qu'il utilise. Le processeur de transformation (comme dans NLP) et le processeur de mise à jour en masse sont deux exemples de ce type (envoie des données à Elasticsearch). Cette mise à jour n'aide pas tous les processeurs. La plupart des processeurs sont fournis avec une configuration par défaut qui prend en compte cette variable et n'a pas besoin d'être modifiée. Lorsque les tests de performances révèlent un goulot d'étranglement devant les processeurs, la configuration par défaut peut bénéficier d'un réglage supplémentaire.
Lorsque le processeur peut traiter les fichiers de flux à la même vitesse qu'ils ne le sont, la valeur Tâches simultanées est idéale, ce qui empêche les empilages importants de fichiers de flux dans la file d'attente du processeur. Etant donné qu'un tel équilibre peut ne pas toujours être atteint, la meilleure configuration se concentre sur la réduction de l'empilage des fichiers de flux dans la file d'attente.