Personnalisation du cycle de vie de l'index
Le cycle de vie de l'index HCL Commerce Search fournit de nombreux points d'extension. Le cycle de vie comporte huit grandes étapes, chacune d'entre elles ayant ses propres possibilités d'extension. Votre outil principal de personnalisation est les fichiers de configuration qui contrôlent le processus d'indexation. Au-delà de la configuration, vous pouvez générer et intégrer votre propre code personnalisé.
Le cycle de vie de l'index
L'indexation (y compris le prétraitement) est effectuée dans le serveur HCL Commerce. Une fois le prétraitement d'index terminé avec succès, le gestionnaire d'importation de données (DIH) peut être exécuté à partir du même serveur HCL Commerce. Solr peut commencer à créer et à mettre à jour l'index Lucene à partir des tables de base de données HCL Commerce temporaires. Si le prétraitement n'est pas nécessaire, par exemple pour l'index d'extension de stock, le processus DIH peut être démarré à partir de HCL Commerce ou directement à partir d'une URL émise sur le serveur HCL Commerce Search.
Le cycle de vie de l'indexation lui-même comporte huit étapes, comme indiqué dans la figure suivante.
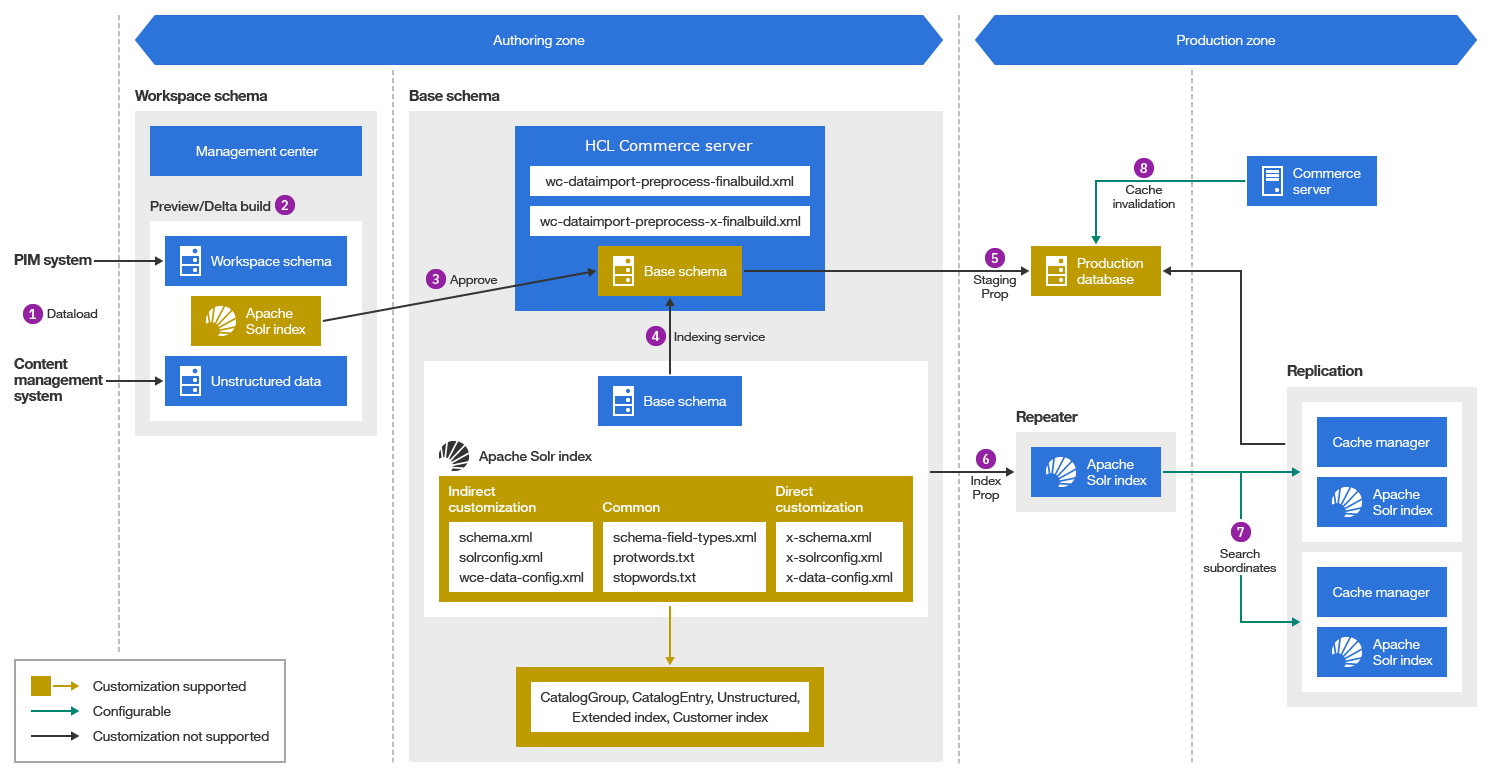
- 1. Chargement des données - Système externe
- PIM : gestion des informations sur les produits ou CMS : un système de gestion de contenu, généralement Websphere Content Hub, est utilisé pour charger des données dans la base de données de création Commerce.
- 2. Prévisualiser
- Une fois le noyau d'index d'espace de travail synchronisé avec la base de données du schéma de l'espace de travail, vos administrateurs d'espace de travail peuvent apporter des modifications aux nouveaux produits de saison. Ils peuvent prévisualiser les nouvelles données, catégories et le nouveau contenu non encore approuvés sur la vitrine. L'analyseur de consommateurs d'événements intégré dans chaque catalogue ajoutera les modifications de données provenant du Centre de gestion dans chaque table delta spécifique à la recherche. Le processus buildIndex lit à nouveau chaque table delta et intègre les données dans un noyau d'index d'espace de travail.
- 3 : Approuver
- Lorsque l'administrateur de l'espace de travail est satisfait des données du catalogue, il approuve et publie l'espace de travail. Les données du schéma de l'espace de travail seront enregistrées dans la base de données du schéma de base, et l'index d'espace de travail sera validé dans l'index de base.
- 4. Service d'indexation
- Le service d'indexation exécute d'abord le script de prétraitement situé dans le serveur de transactions pour aplatir les données dans une table ou une vue temporaire. Ensuite, le service exécute DataImportHandler pour importer des données depuis la table ou la vue temporaire dans l'index.
- 5. Stagingprop
- Lorsque tout est prêt dans l'environnement de création, la base de données est propagée vers l'instance de production.
- 6. Indexprop
- La réplication des données est effectuée par le service d'administration de la recherche.
- 7. Réplication
- Une fois l'index prêt sur le répéteur, le processus de réplication intégré du moteur Solr reproduira l'index à partir du répéteur vers les nœuds subordonnés. Vous pouvez choisir de répliquer un fichier externe ou un fichier de schéma, ou de forcer un contrôle d'intégrité après la réplication. Vous pouvez également effectuer une personnalisation supplémentaire au niveau du gestionnaire de réplication fourni par la recherche.
- 8. Invalidations du cache
- Un cache de données est activé sur le serveur de recherche. Il est principalement utilisé pour mettre en cache trois types de données : opérations centralisées de base de données, telles que l'information sur les autorisations B2B ou la configuration des facettes ; recherche de règles de recherche qui nécessitent un rappel sur le serveur de transactions ; et les informations de hiérarchie de catégorie créées par un accès centralisé à l'index. Lorsqu'une base de données liée à une facette ou à une autorisation, une règle ou un index de recherche est modifié, l'invalidation est déclenchée pour invalider le cache de données et le cache de fragments de vitrine. Normalement, l'invalidation du cache des autorisations, des facettes et des règles de recherche est déclenchée par la définition d'un déclencheur de base de données. Les hiérarchies de catégories sont invalidées en exploitant la table CACHEIVL. Normalement, IndexProp enregistre les événements d'invalidation du cache dans la base de données de la table CACHEIVL. Plus tard, chaque appel REST de recherche appellera le gestionnaire de cache dans le serveur de recherche pour lire CACHEIVL et émettre une invalidation. Remarque : Alors que les serveurs de recherche et de transactions effectuent l'invalidation à l'aide de la table CACHEIVL, le serveur de magasin émet des invalidations en s'abonnant à un message Kafka.
- Pris en charge : Le processus de personnalisation est pris en charge. Pour plus d'informations, voir Contacter le support client HCL.
- Prise en charge ultérieure : IBM a l'intention de prendre en charge la fonction de personnalisation dans une version ultérieure. Si vous avez un besoin de personnalisation associé, vous pouvez contacter l'équipe de support IBM pour plus d'informations.
- Non pris en charge : IBM n'a pas l'intention de prendre en charge une telle fonction de personnalisation à l'avenir. Vous devez éviter de personnaliser la zone connexe ou rechercher des alternatives dans votre implémentation.
Personnalisation par étape du cycle de vie
La table suivante relie les étapes du cycle de vie de l'index aux sujets de configuration correspondantes du Centre de connaissances.
| Méthode | Point de personnalisation | Niveau de prise en charge* | |
|---|---|---|---|
| 1 | chargement de données | utilitaire de buildIndex | Médiateurs personnalisés ; buildIndex. |
| 2 | Aperçu du magasin/génération delta | Réindexation | Personnalisation non prise en charge. Voir Synchronisation d'index et mises à jour delta dans HCL Commerce Search. |
| 3 | Approuver l'index | Les données sont validées dans le schéma de base. | Personnalisation non prise en charge |
| 4 | Personnaliser le fichier schema.xml d'index par défaut | Ajoutez une personnalisée en réutilisant la valeur fieldType d'HCL Commerce dans le schéma d'index par défaut (y compris les utilitaires preprocess oy buildindex). | Personnalisation prise en charge. Voir Fichier de personnalisation du schéma d'index de recherche x-schema.xml. |
| Ajouter une valeur fieldType personnalisée | Personnalisation prise en charge. Voir Fichier de personnalisation du schéma d'index de recherche x-schema.xml. | ||
| Modifier les zones avec la valeur fieldType native de Solr dans schema.xml (notamment int, string, date, float, long, etc.). | Personnalisation non prise en charge | ||
| Modifiez une valeur fieldType d'HCL Commerce dans x-schema.xml (notamment wc_text*, add StopWords to partNumber_ntk). | Personnalisation prise en charge. Voir Fichier de personnalisation du schéma d'index de recherche x-schema.xml | ||
| Modifiez une valeur fieldType d'HCL Commerce dans x-schema.xml pour la langue spécifiée (par exemple, pour personnaliser StopWords pour l'anglais uniquement). | Personnalisation prise en charge. Voir Fichier de personnalisation du schéma d'index de recherche x-schema.xml. | ||
| Ajoutez un nouveau noyau de langue pour l'index par défaut existant. | Personnalisation prise en charge. Voir Configuration de l'index de recherche. | ||
| Personnaliser l'instance Solr native à l'aide de solrconfig.xml | Revenez aux versions précédentes de MultipleQueryComponent pour obtenir un noyau d'extension personnalisé.
|
Personnalisation prise en charge. | |
| Enregistrez un analyseur de requête personnalisé. | Personnalisation prise en charge. Voir Composants personnalisables de la requête Solr finale. | ||
| Enregistrez un analyseur de fonctions. | Personnalisation prise en charge. Voir Activation de la recherche sur d'autres types de contenu non structuré. | ||
| Enregistrez une transformation pendant buildindex. | Personnalisation prise en charge. Voir Processus d'indexation. | ||
| Personnalisez le programme d'écoute d'événement lié à IndexSearcher. | Personnalisation non prise en charge | ||
| Personnalisez le programme d'écoute d'événement lié à la mise à jour. | Personnalisation non prise en charge | ||
| Personnalisation sur wc-data-config.xml | Personnalisation des mappages de zones existantes dans wc-data-config.xml pour CatalogEntry/CatalogGroup/unstructured/Inventory/Price. | Personnalisation non prise en charge | |
| Ajoutez un nouveau mappage de zone dans wc-data-config.xml pour CatalogEntry, CatalogGroup, Unstructured, Inventory, ou Price. | Personnalisation prise en charge. Voir Extension du fichier wc-data-config.xml à l'aide du fichier wc-data-preprocess-x-finalbuild.xml. | ||
| Choisissez un stock non ATP ou DOM pour wc-data-config.xml. | Personnalisation prise en charge. Voir Propriétés de recherche dans le fichier de configuration de composant (wc-component.xml). | ||
| Remplacez complètement la valeur par défaut, wc-data-config.xml . | Personnalisation prise en charge. Voir Extension du fichier wc-data-config.xml à l'aide du fichier wc-data-preprocess-x-finalbuild.xml. | ||
| Personnaliser le chargement d'index | Indexload pour CatalogGroup ou CatalogEntry maître. | Personnalisation non prise en charge | |
| Indexload pour le noyau d'extension personnalisé. | Personnalisation non prise en charge | ||
| Personnalisation de la fragmentation | Partitionnez sur un noyau autre que catentry. | Personnalisation non prise en charge | |
| 5 | Propagez les données de transfert | Modifiez les paramètres de ligne de commande de l'utilitaire StagingProp. | Configurable à l'aide de l'utilitaire StagingProp. Voir stagingprop, utilitaire. |
| 6 | Propagation de l'index | Modifiez les paramètres de ligne de commande de l'utilitaire IndexProp. | Configurable à l'aide de l'utilitaire IndexProp. Voir Propagation de l'index de recherche. |
| 7 | Réplication, opération et contrôle de l'intégrité | Effectuez la réplication sur un index personnalisé, par exemple répliquez depuis un maître vers un répéteur, ou depuis un répéteur vers un subordonné. | Personnalisation non prise en charge |
| Répliquez sur un fichier externe pour un index personnalisé. | Personnalisation non prise en charge | ||
| Personnalisez les fonctions de réplication, d'opération ou de contrôle d'intégrité existantes. | Personnalisation prise en charge. Voir Points d'extension de vérification d'index | ||
| 8 | Cache et invalidation du cache | Invalidation du cache par la table CACHEIVL pour un index personnalisé. | Configurable. Voir Invalidation des données en mémoire cache. |
| Remplacez par un autre fournisseur de cache centralisé (tel que WXS). | Personnalisation non prise en charge |