
Fonctions d'index du magasin de ressources catalogue
L'indexation dans le modèle de magasin de ressources de catalogue (CAS) est différente de l'approche eSite. Il dispose également d'améliorations de l'index URL et du temps quasi réel (NRT) qui réduisent la charge de traitement et améliorent l'efficacité.
Etapes d'indexation
Le processus d'indexation eSite existant utilise le flux de connecteur de réindexation pour indexer les magasins eSite. Il existe un pipeline de traitement principal et des étapes latérales facultatives où un traitement de données supplémentaire peut se produire.
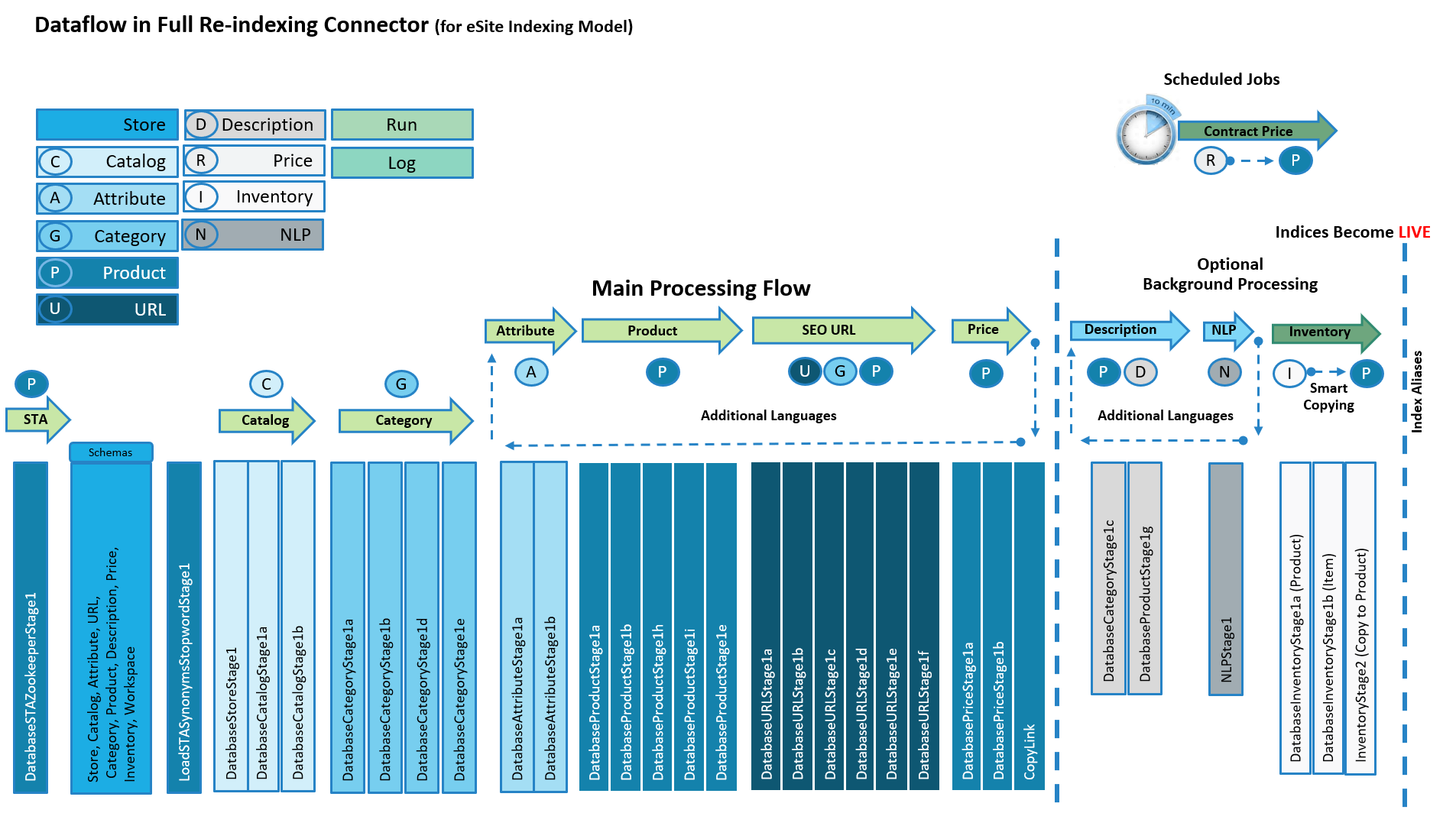
Chaque flux de traitement ne peut gérer qu'un magasin et une langue à la fois. Un composant de contrôle de flux est utilisé pour effectuer des flux de données internes récurrents afin de gérer d'autres langues prises en charge.
Les URL de référencement et d'autres métadonnées associées sont indexées dans un index d'URL distinct pour la recherche du temps de requête.
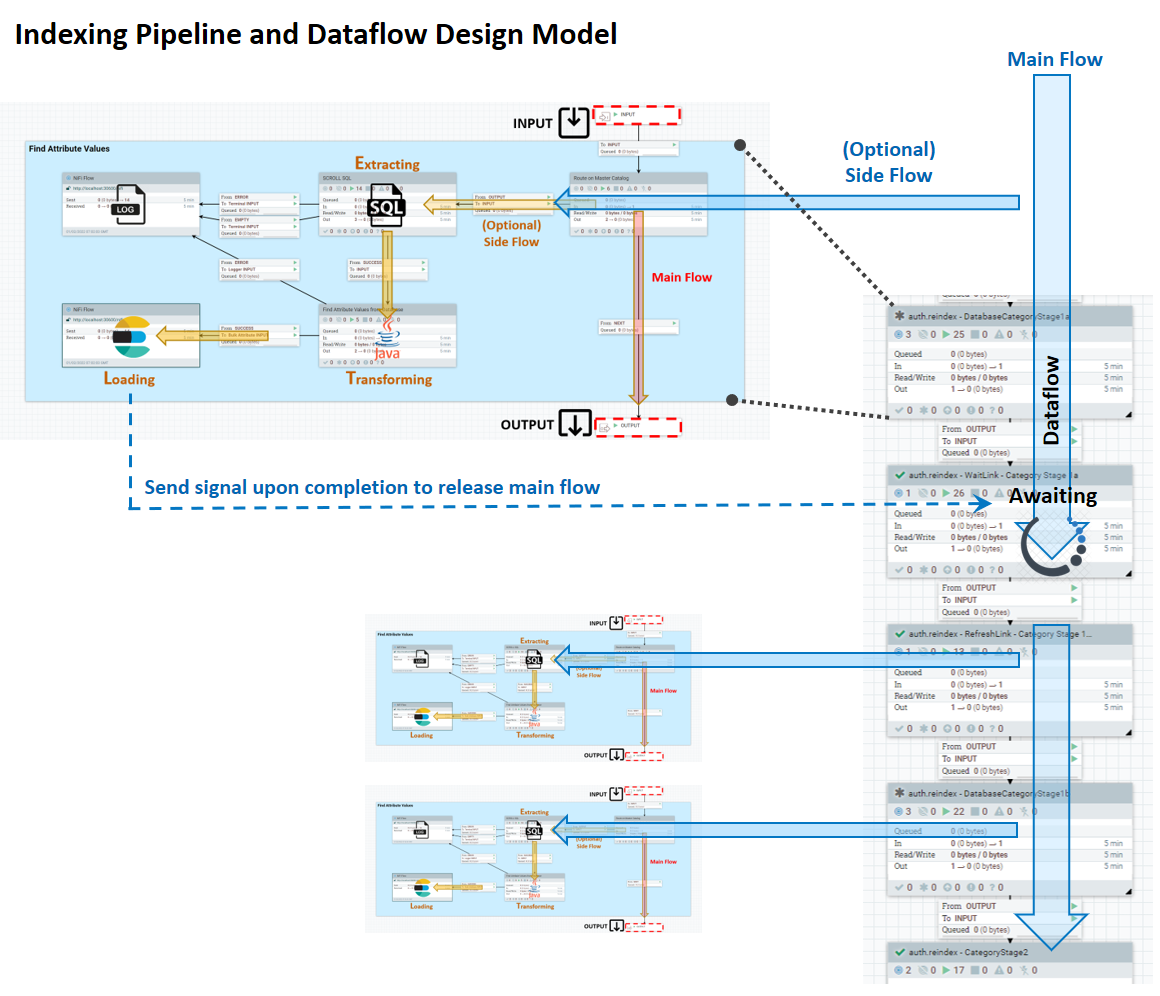
Chaque étape de flux latérale est constituée de la même manière à partir d'une conception de paragraphe passe-partout, avec un module d'entrée, un module de traitement principal et un module de sortie. L'étape est connectée par un lien vers l'étape suivante et appelle également un processus de journalisation. Dans cette structure, vous pouvez personnaliser le traitement en fonction de vos objectifs métier.
Le flux d'indexation CAS est légèrement différent. Il traite tous les sites étendus sous-jacents et toutes leurs langues prises en charge dans un seul flux de données.
Le flux de traitement principal CAS est par ailleurs très similaire au modèle eSite, sauf que l'étape de l'URL est désormais remplacée par une étape Page qui indexe uniquement le modèle de référencement associé à chaque mot clé. Pour plus d'informations, voir Améliorations de l'index URL, plus bas. Les URL de référencement sont indexées dans l'index Catégorie et Produit.
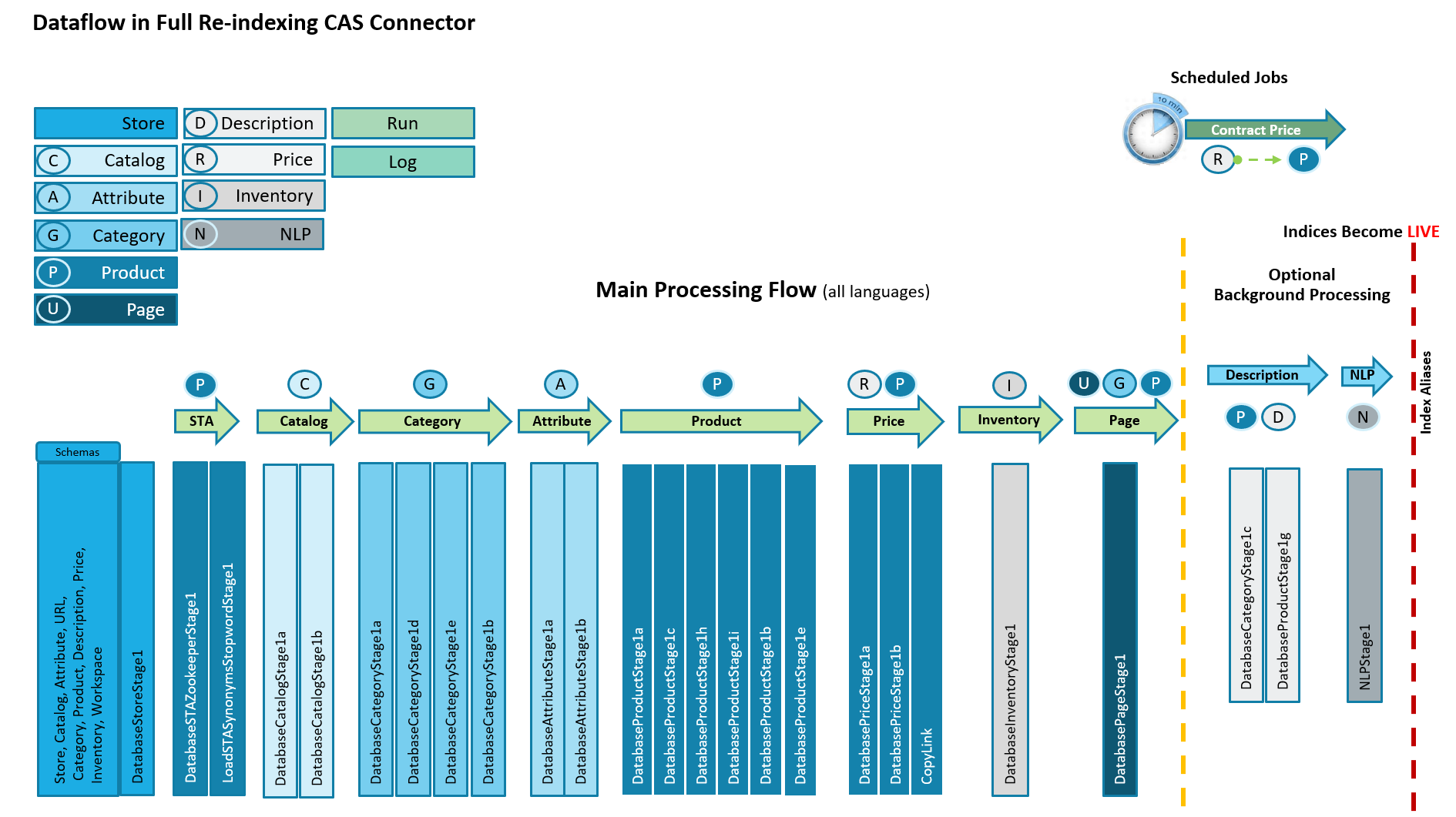
Le flux de pipeline d'indexation CAS est très similaire au modèle eSite, mais la conception du flux de données interne est très différente :
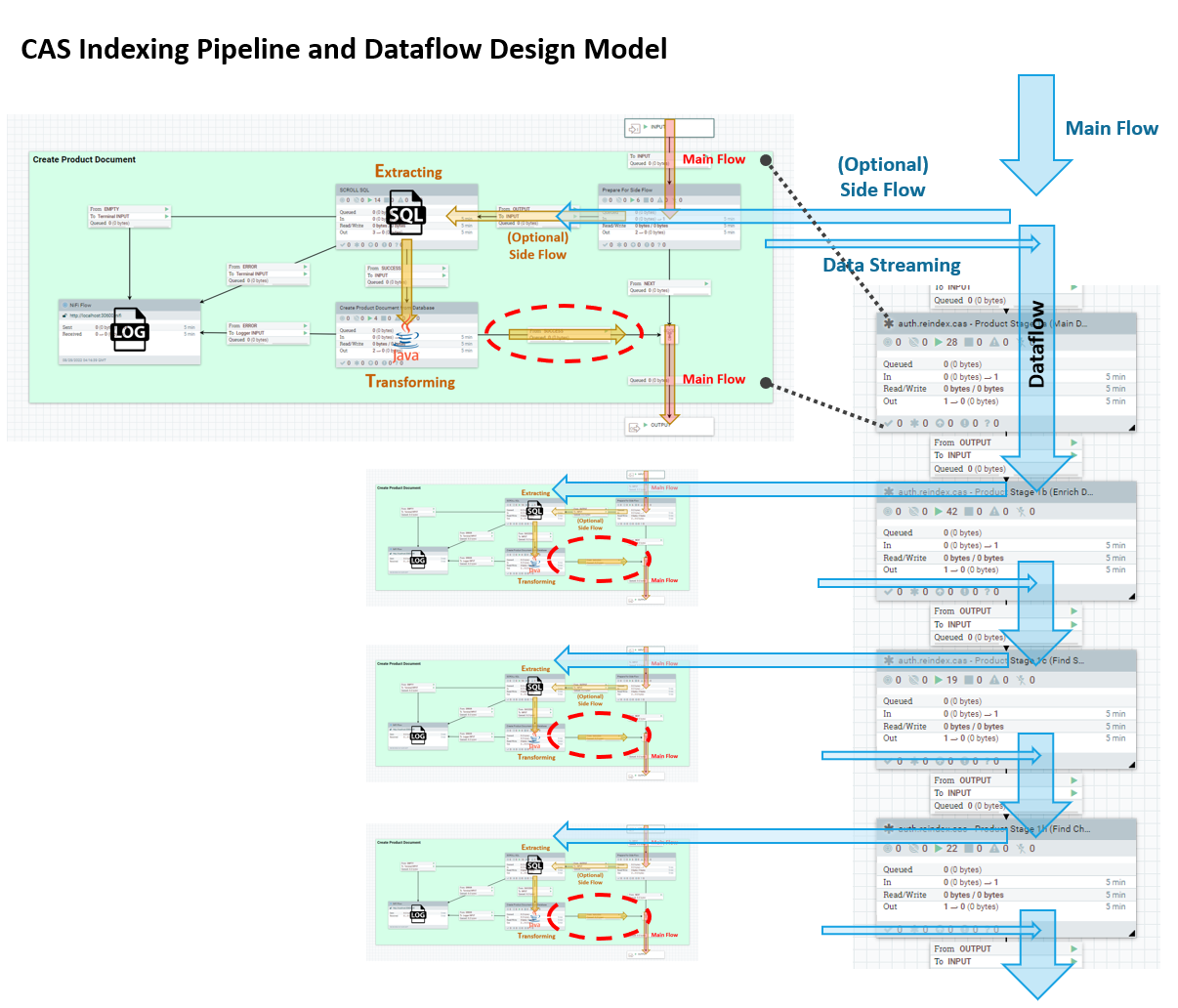
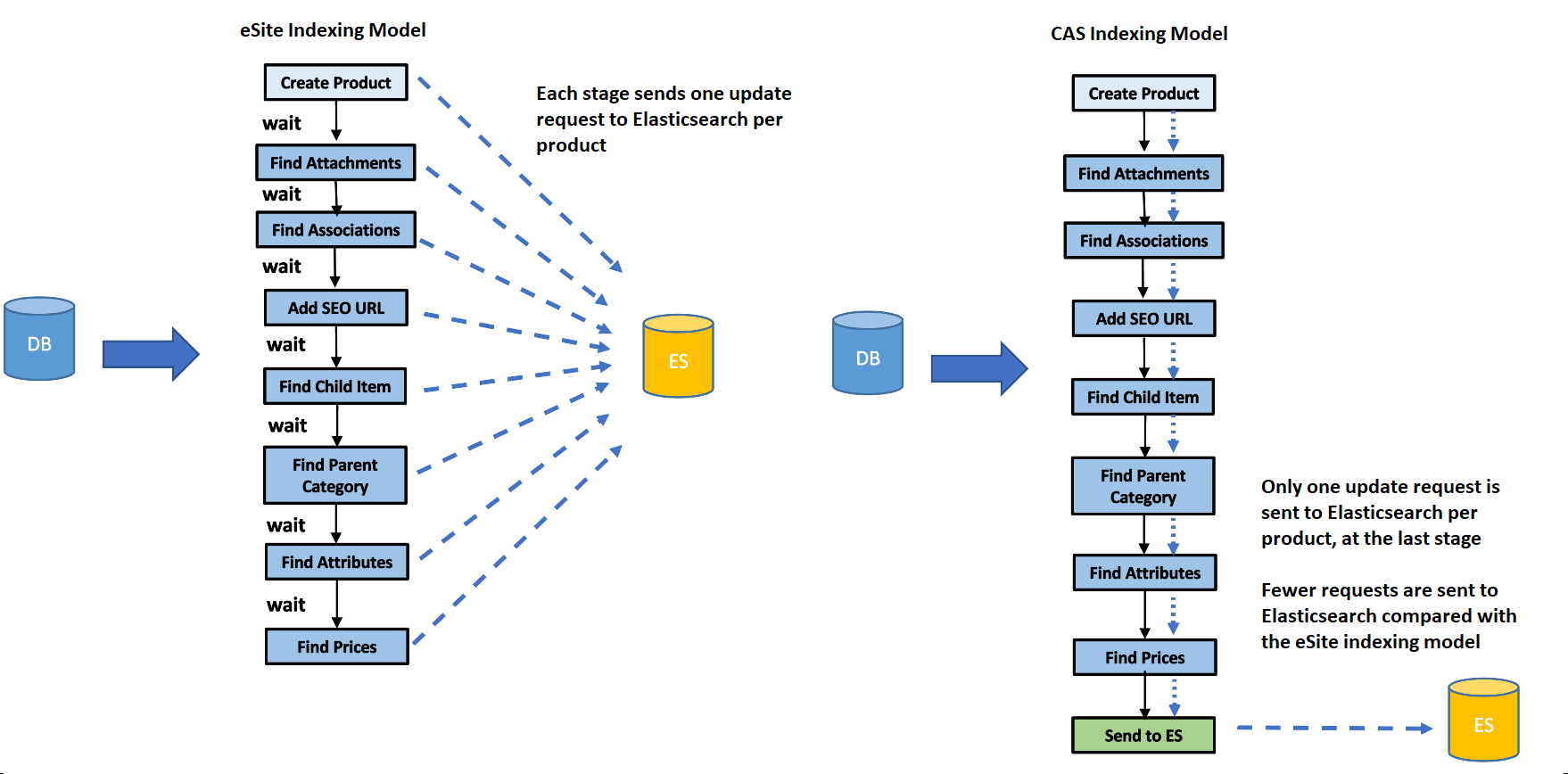
Chaque étape n'écrit plus de mises à jour incrémentielles dans Elasticsearch. A la place, chaque étape transmet le document de travail en cours jusqu'à l'étape suivante où des données métier supplémentaires peuvent être fusionnées. Ce processus se répète jusqu'à ce qu'il atteigne la fin du pipeline d'indexation dans un canal Produit final.
A la fin de chaque pipeline (c'est-à-dire une série d'étapes et de canaux), le document de travail en cours sera ensuite converti en un document prêt pour l'index pour Elasticsearch. Ce document terminé sera envoyé à Elasticsearch à une seule reprise.
Chaque fichier de flux est autonome. Il contient toutes les informations et données qui ont été utilisées pour assembler son contenu. Cette approche supprime la dépendance sur tout stockage temporaire externe entre les étapes, évite la nécessité de coordonner les fichiers de flux entre les étapes (waitLink, par exemple) et facilite même l'identification et la résolution des incidents.
Une SQL pour extraire des données métier de la source de données, telle qu'une base de données, est beaucoup plus simple. Les ID sont transmis en tant qu'attributs de fichier de flux, de sorte que les étapes en aval n'ont plus besoin de régénérer le contexte pour redéfinir la portée du jeu de données source.
La personnalisation d'Ingest est plus facile. Vous n'avez pas besoin de comprendre comment les documents par défaut ont été construits. Pour la personnalisation générale d'un document d'indexation, il suffit de baliser à la fin de notre pipeline par défaut et d'effectuer les modifications personnalisées requises avant de procéder à un envoi à Elasticsearch.
Améliorations de l'index URL
- Nouvel index de page
- L'index URL par défaut, utilisé par le modèle d'indexation eSite, inclut tous les produits, catégories et pages. La plupart de ces informations sont dupliquées dans l'index Produit et l'index Catégorie. Par conséquent, l'index URL est très volumineux et peut prendre beaucoup de temps à traiter et à synchroniser.
- Nouvelle étape de page
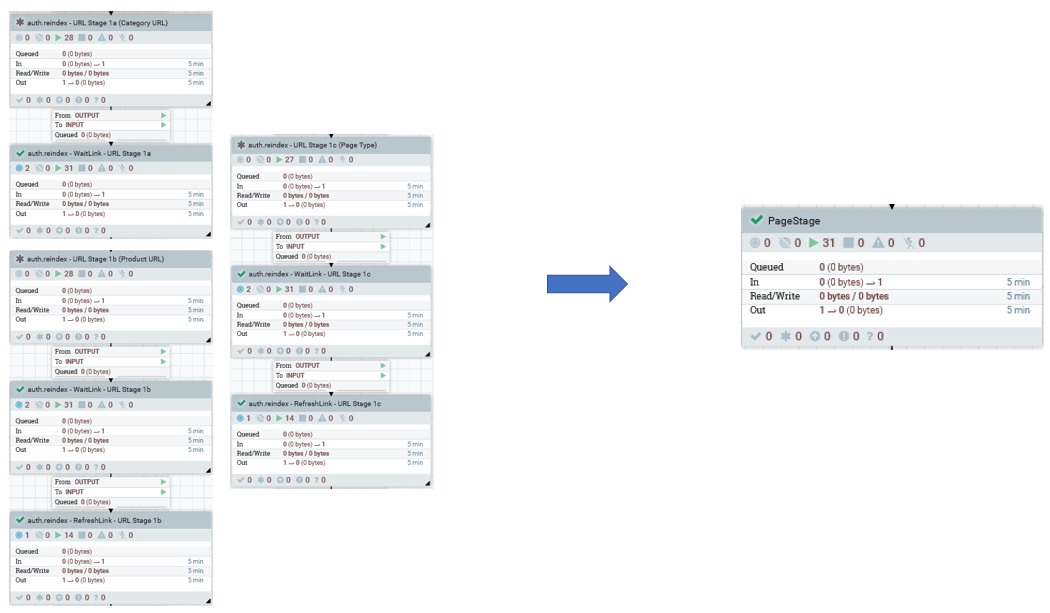
- Dans le modèle d'indexation eSite, l'indexation d'URL inclut trois étapes qui traitent les produits, les catégories et les pages. Dans le modèle Magasin de ressources, ces étapes sont remplacées par une étape Page, qui traite les trois types ensemble. Cela simplifie considérablement le processus d'indexation et améliore les performances.
- Service URL Query
- Un indicateur de niveau site dans le service Query indique quel modèle d'index est utilisé. Lors de l'exécution, le service URL Query interroge l'index Page pour extraire le modèle de page, puis interroge l'index Produit ou Catégorie pour extraire les informations nécessaires pour renseigner le modèle. S'il existe un jeton de description longue dans le modèle de page, le service URL Query interroge également l'index Description pour obtenir de longues descriptions des produits ou des catégories.
Le service URL Query appelle ensuite le Transaction server pour obtenir les informations de présentation de page.
Il existe un profil distinct pour le modèle d'index Magasin de ressources. Le profil peut définir différentes classes de fournisseur, de préprocesseur et de post-processeur pour le modèle d'index Magasin de ressources. De cette manière, le même processus de service Query peut être utilisé pour prendre en charge les deux modèles d'index.
Améliorations en quasi-temps réel (NRT)
- Réduire le nombre de flux
- Dans le modèle d'index Magasin eSite, chaque combinaison eSite et langue génère un flux NRT. Par conséquent, le nombre de flux est égal au nombre d'eSites multiplié par le nombre de langues. Lorsque plusieurs langues sont indexées, le temps d'indexation augmente considérablement.
Dans le modèle d'index Magasin de ressources, un seul flux génère tous les magasins eSite et toutes les langues. Cela entraîne une amélioration considérable des performances par rapport au modèle eSite.
- Hiérarchie de catégories
- Lorsque vous modifiez le parent d'une catégorie, la hiérarchie de catégories est régénérée. Dans le modèle de magasin eSite, toutes les hiérarchies de catégories sont mises à jour, même si une seule catégorie est concernée par la modification de parenté.
Dans le modèle d'index Magasin de ressources, seules la hiérarchie des catégories parent, la catégorie qui est concernée par la modification de parenté et ses sous-catégories sont mises à jour. Par conséquent, moins de mises à jour sont envoyées au serveur Elasticsearch.
- Pas besoin de mettre à jour l'index URL
- Lorsque vous modifiez des produits ou des catégories sous le modèle de magasin eSite, l'index URL pour ces produits ou catégories est régénéré. Au total, il y a six étapes liées à l'index URL.
Optimisation simple des performances
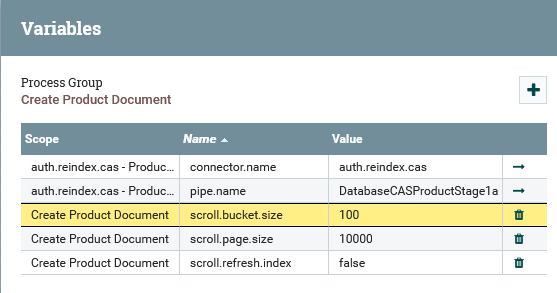
Le nombre d'entrées de catalogue dans chaque fichier de flux est contrôlé par la variable scroll.bucket.size à l'étape auth.reindex.cas - Product Stage 1a (Main Document). Vous pouvez définir une valeur comprise entre 100 et 1000, en fonction de la taille du catalogue. Si la taille du catalogue est importante, définissez scroll.bucket.size sur un nombre plus petit, tel que 200. En outre, la variable scroll.page.size peut également être définie sur un nombre plus petit, tel que 10000.
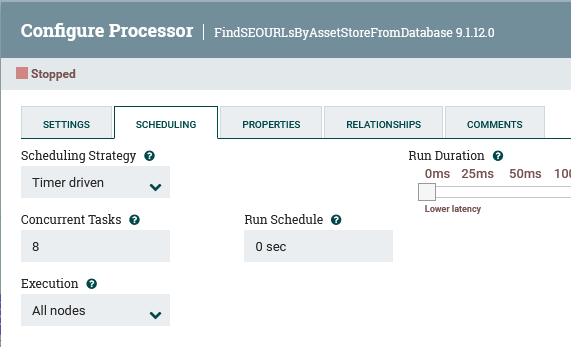
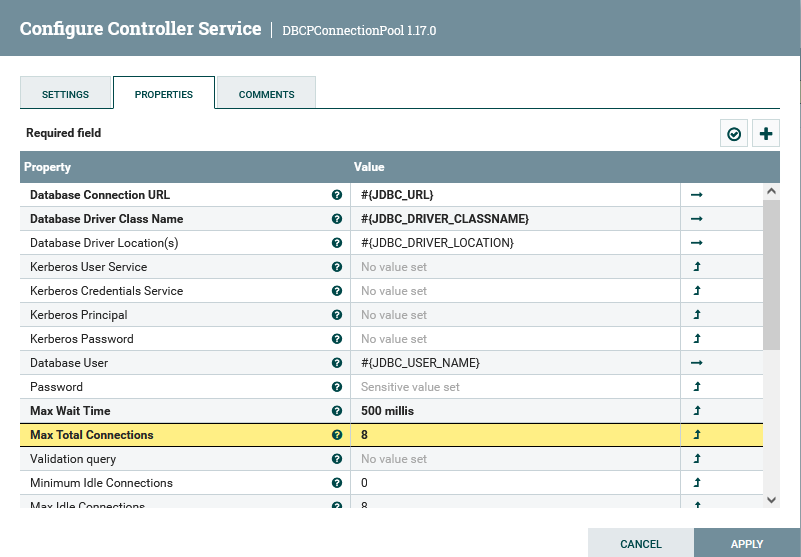
Si vous constatez que de nombreux flux sont bloqués dans une étape particulière, vous pouvez augmenter le nombre dans la zone Tâches simultanées de l'onglet Planification de la fenêtre Configurer le processeur et le nombre maximal de connexions sous l'onglet Propriétés du pool de connexions de base de données.
Limitations
- Commutation de langue
- La commutation de langue n'est actuellement pas prise en charge dans le modèle d'index Magasin de ressources de catalogue. La valeur par défaut du paramètre flow.language.fallback est "true", ce qui reste inchangé lorsque vous activez CAS malgré la limitation. Vous pouvez la laisser définie sur "true". Pour plus d'informations sur la définition de flow.language.fallback et des paramètres associés, voir Configuration d'Ingest via REST.