Invalidation de cache à l'aide de Kafka et ZooKeeper
Vous pouvez utiliser Apache Kafka et Apache ZooKeeper pour effectuer l'invalidation du cache. Les tâches d'invalidation peuvent être exécutées à partir de serveurs locaux ou distants.
Si vous n'exécutez pas Redis, vous pouvez utiliser Kafka et ZooKeeper pour exécuter l'invalidation entre des serveurs de transactionnel, entre un serveur de transaction et des serveurs de magasin, ou entre un serveur de transaction et des serveurs de recherche. Si vous utilisez Redis, Kafka n'est pas requis pour l'invalidation du cache. Pour plus d'informations, voir HCL Cache avec Redis.
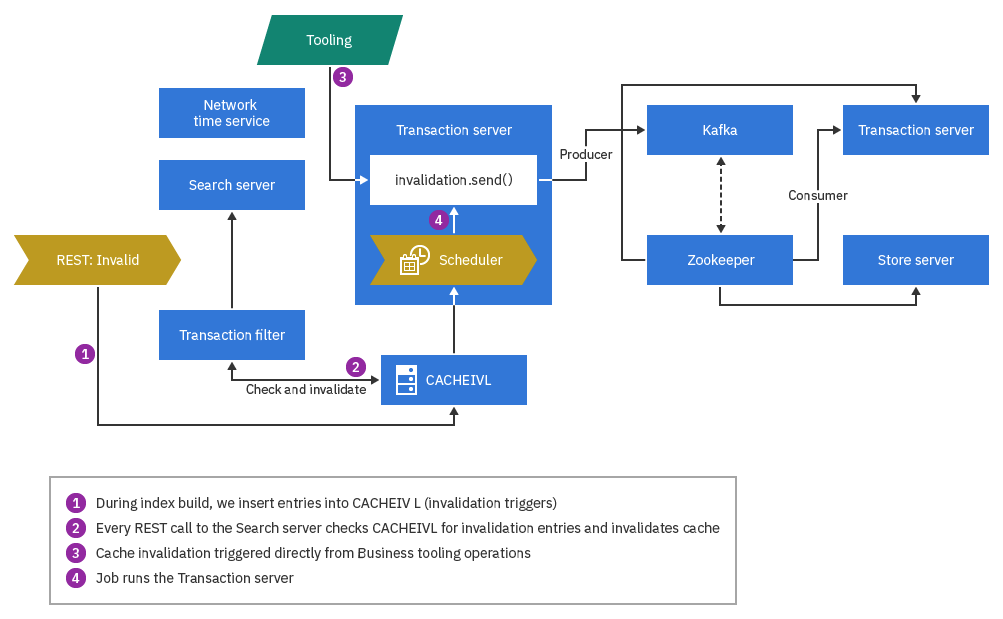
 Vous pouvez utiliser Kafka pour exécuter l'invalidation entre des serveurs de transaction, entre un serveur de transaction et des serveurs de magasin, ou entre un serveur de transaction et des serveurs de recherche. Zookeeper communiquera uniquement avec Kafka dans ces circonstances. Le flux de processus général pour l'invalidation de cache Kafka est indiqué dans le diagramme suivant.
Vous pouvez utiliser Kafka pour exécuter l'invalidation entre des serveurs de transaction, entre un serveur de transaction et des serveurs de magasin, ou entre un serveur de transaction et des serveurs de recherche. Zookeeper communiquera uniquement avec Kafka dans ces circonstances. Le flux de processus général pour l'invalidation de cache Kafka est indiqué dans le diagramme suivant.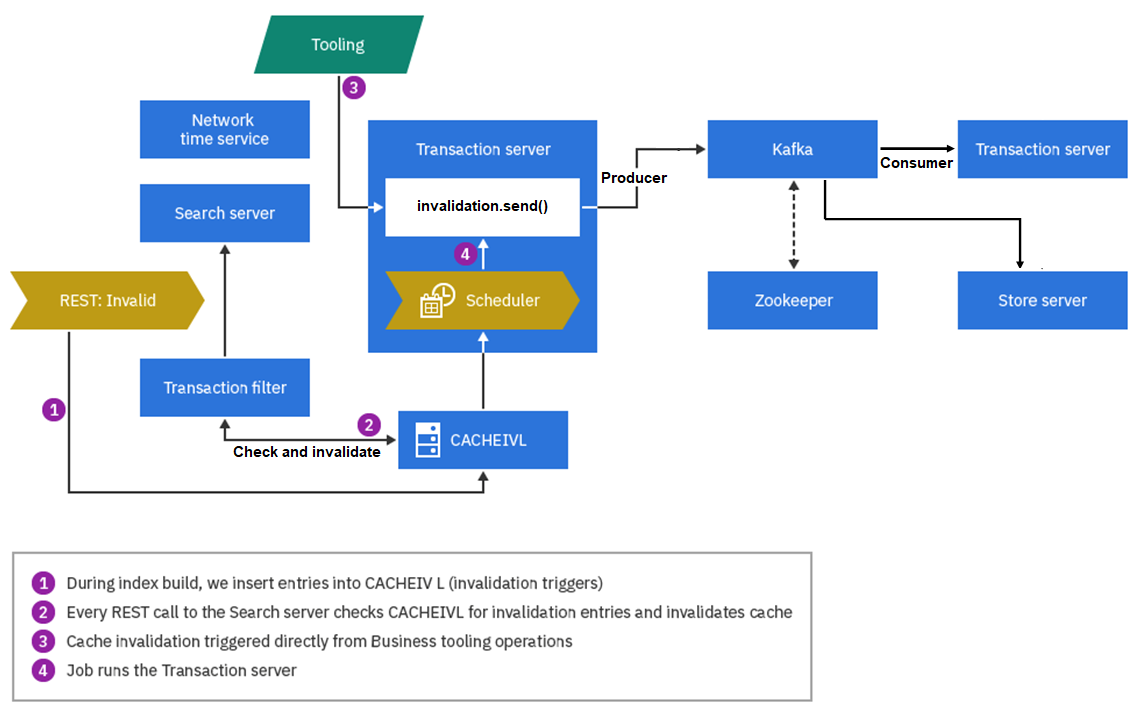
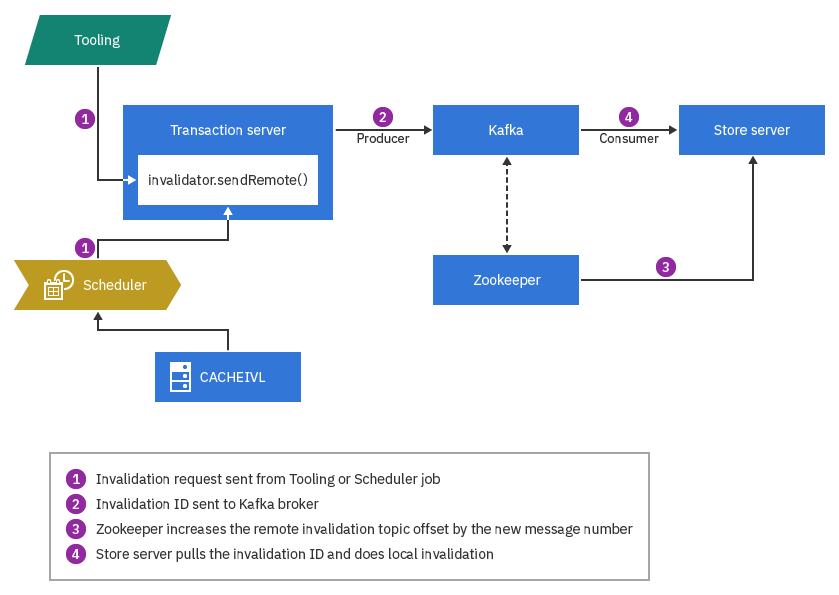
Invalidation entre des serveurs de transaction
topicnamePeerCacheInvalidation, où topicname correspond au nom de votre rubrique Kafka. Le producteur envoie des messages au courtier Kafka, qui les ajoute aux partitions de rubrique. Par exemple, si un utilisateur professionnel met à jour les données de création, son serveur de transaction envoie des ID d'invalidation de cache au courtier Kafka lorsque la transaction d'invalidation est validée. Le serveur de transactions du consommateur surveille les mêmes rubriques sur le serveur Kafka et, lorsqu'il détecte des modifications de décalage des messages, il interroge le courtier Kafka pour les ID d'invalidation. Ensuite, il effectue l'invalidation à l'aide d'un mappage préconfiguré "Table de base de données - Conteneur en cache".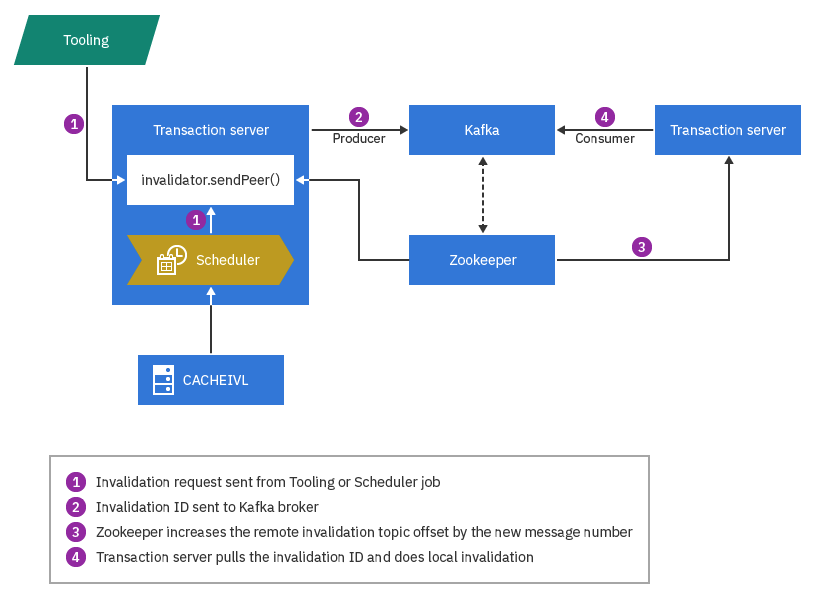
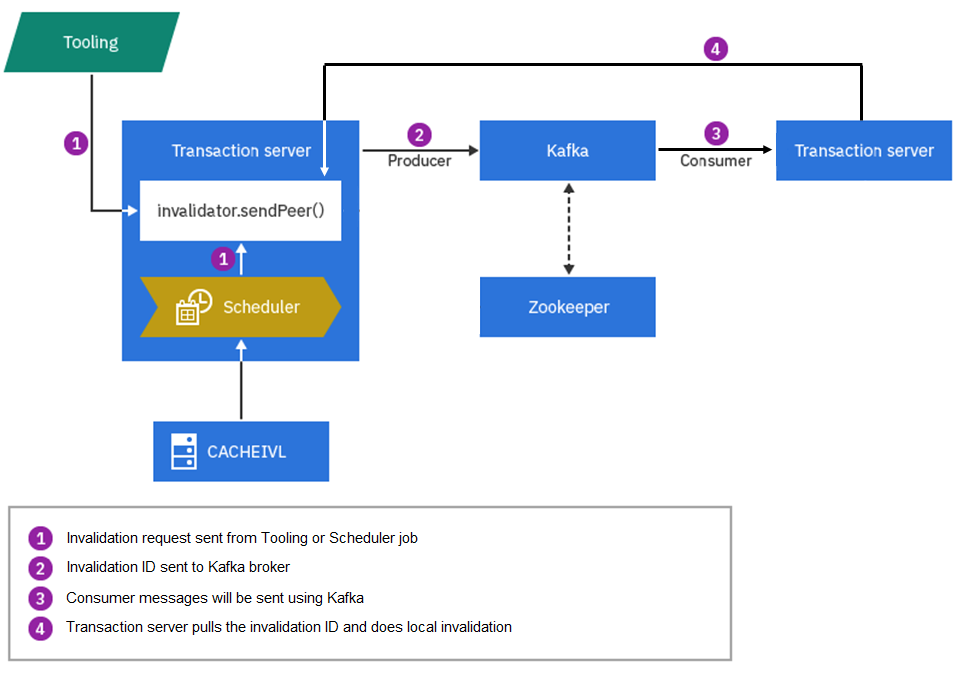
Certains événements, tels que les opérations de chargement de données, ne déclenchent pas directement l'invalidation. Au lieu de cela, les déclencheurs de table de base de données, les tâches de création d'index et d'autres tâches quotidiennes placent de nouveaux enregistrements dans la table CACHEIVL au fur et à mesure qu'ils sont exécutés. Le travail de planification d'invalidation du cache analyse la table CACHEIVL et récupère les dernières modifications. Il effectue ensuite l'invalidation du cache local et envoie des messages d'invalidation au courtier Kafka. Comme dans l'exemple précédent, lorsque les serveurs de transactions homologues détectent les nouveaux messages, il effectue l'invalidation par mappage préconfiguré "Table de base de données - Conteneur en cache".
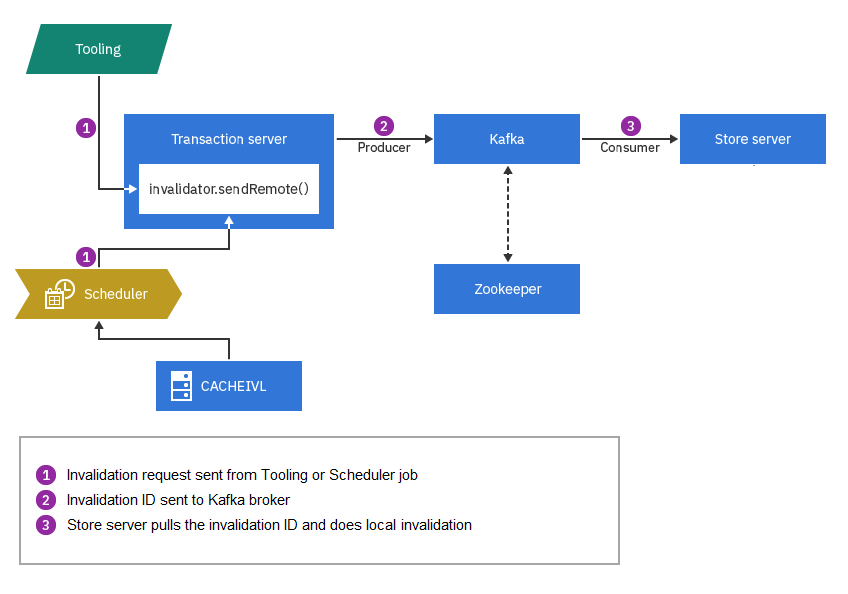
Invalidation entre un serveur de transactions et un serveur de magasin
Dans ce scénario, le serveur de transactions correspond au producteur de messages et le serveur de magasin distant au consommateur de messages. La rubrique d'invalidation du cache dans ce scénario d'invalidation est différente de celle du scénario d'invalidation entre des serveurs de transactions. Si les mêmes données doivent être invalidées sur les serveurs de magasin et de transactions, le même ID d'invalidation sera ajouté aux deux rubriques. Le nom de la rubrique d'invalidation entre un serveur de transactions et un serveur de magasin est structuré comme suit : topicnameCacheInvalidation.
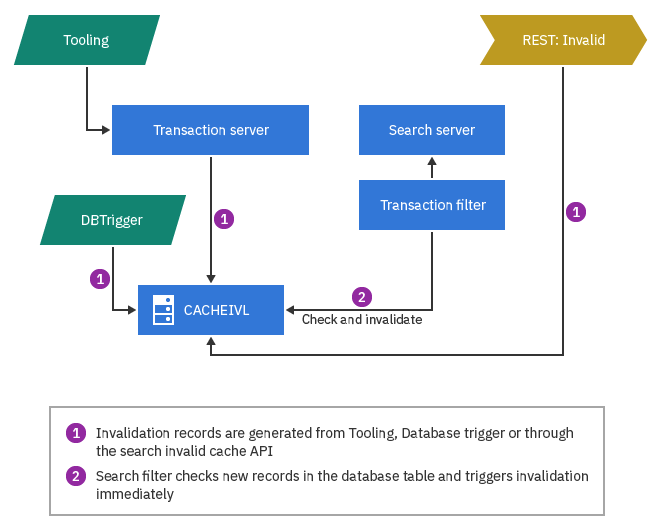
Invalidation d'un serveur de recherche
Le serveur de recherche utilise CACHEIVL pour coordonner l'invalidation du cache. Toutes les requêtes REST qui sont acheminées vers le serveur de recherche passent par un filtre servlet nommé TransactionFilter. A des heures préconfigurées, le filtre vérifie les enregistrements de table CACHEIVL nouvellement insérés. Ceux-ci sont sélectionnés pour l'invalidation.
Invalidation d'un cache personnalisable après la génération de l'index de recherche
L'invalidation du cache sur le serveur de magasin peut utiliser les entrées personnalisées ajoutées par le serveur de recherche pendant le processus de génération d'index. Au cours de ce processus, le serveur de recherche insère les enregistrements d'invalidation personnalisés dans la table de base de données CACHEIVL pendant le processus de génération d'index. La base de données envoie ensuite les enregistrements au serveur de transactions, qui effectue à son tour des requêtes d'invalidation au serveur de magasin, où l'invalidation du cache du servlet est effectuée.
Vous pouvez utiliser le paramètre suivant pour enregistrer les enregistrements dans CACHEIVL lorsque l'API REST d'invalidation search/admin/resources/index/cache/invalidate est appelée.
<_config:property name="CacheInvalidationForCatalogEntry" value="productId:$catEntryId$,CategoryDisplay:storeId:categoryId:$storeId$:$catGroupId$" />
<_config:property name="CacheInvalidationForCatalogGroup" value="CategoryDisplay:storeId:categoryId:$storeId$:$catGroupId$" />
<_config:property name="CacheInvalidationForStoreHeader"value="StoreHeader:storeId:catalogId:$storeId$:$catalogId$,StoreHeader:storeId:$storeId$" />