Indexation et manipulation de contenu non structuré
Les informations stockées dans du contenu non structuré peuvent être organisées et stockées à partir de plusieurs emplacements, y compris la base de données HCL Commerce, dans les systèmes de fichiers des serveurs et sur Internet. Par conséquent, le processus d'indexation des contenus non structurés utilise une solution hybride de sources de données pour créer des informations d'indexation en utilisant la structure d'indexation HCL Commerce Search existante.
Organisation et récupération du contenu non structuré
Le contenu non structuré comprend des informations d'entrée de catalogue et ses pièces jointes associées. Les pièces jointes HCL Commerce sont utilisées pour rechercher la pièce jointe liée à l'entrée de catalogue pour une langue spécifique. Etant donné que toutes les pièces jointes ne contiennent pas de language_id, le comportement par défaut fusionne les résultats language_id null avec les résultats language_id spécifiques.
Lorsque la valeur language_id est définie à partir de la table HCL Commerce, -1 représente l'anglais des Etats-Unis et la liste catentry_id est le paramètre d'entrée. Le résultat de la recherche contient la valeur catentry_id, le chemin d'accès de la pièce jointe, l'utilisation de la pièce jointe et la description de la pièce jointe. La liste de types d'utilisation de la pièce jointe par défaut est DOCUMENTS, USERMANUAL, WARRANTY et OTHER. Pour la personnalisation, ces types d'utilisation sont configurables pour répondre à vos besoins de recherche spécifiques.
<script><![CDATA[
function isWriteToFile(row) {
var ruleName = row.get('RULENAME');
var writeToFile = "false";
if(ruleName != null){
if(ruleName == 'DOCUMENTS' || ruleName == 'USERMANUAL' || ruleName == 'WARRANTY'
|| ruleName == 'OTHER'){
writeToFile = "true";
}
}
row.put('writeToFile', writeToFile);
return row;
}
]]></script>
Gestionnaire d'importation de données et indexation du contenu non structuré
Le gestionnaire d'importation de données gère le processus d'indexation des contenus non structurés en utilisant une solution hybride de sources de données pour créer des informations d'indexation qui utilise la structure d'indexation HCL Commerce Search existante. TikaEntityProcessor est utilisé pour prendre en charge les données hybrides.
Le diagramme suivant illustre le rôle de TikaEntityProcessor dans la gestion du contenu non structuré dans HCL Commerce :
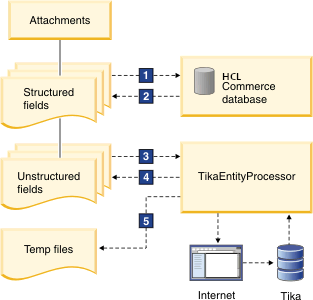
- 1, 2
- Les entrées de catalogue sont indexées depuis la base de données HCL Commerce en tant que contenu structuré.
- 3, 4, 5
- La logique réutilise les fonctions de la structure DIH, telles que le bouclage à travers les lignes du jeu de résultats SQL et la transmission des paramètres dans un format similaire à
${Attachment.CATENTRY_ID}. TikaEntityProcessor utilise le paramètresourceUrlavec des paramètrescommercebasepour récupérer du contenu à partir d'Internet, analyse le contenu binaire et renvoie les résultats à l'index de contenu non structuré. Ensuite, TikaEntityProcessor ajoute le contenu de texte à un fichier catentryId.txt, qui se trouve dans le dossier temporaire sous le dossier racine de base non structuré.
Les paramètres commercebase peuvent être personnalisés pour répondre à vos besoins de recherche spécifiques. Les paramètres tikacontentfield et les paramètres tikaprefix sont directement mappés aux paramètres de la cellule Solr fmap.content et uprefix. Pour plus d'informations, voir ExtractingRequestHandler.
L'appel RESTful buildindex est utilisé pour indexer le contenu non structuré.
Mises à jour du processus du gestionnaire d'importation de données de contenu structuré pour indexer le contenu non structuré
Les objets structurés devront peut-être être recherchés par le contenu d'un contenu non structuré connexe. Par conséquent, le contenu non structuré est également requis par le contenu structuré. Autrement dit, le processus d'indexation DIH du contenu structuré par défaut doit également lire le contenu du contenu non structuré. PlainTextEntityProcessor est utilisé pour lire le contenu des fichiers temporaires et les indexer dans la zone définie. Il utilise les fichiers temporaires créés par TikaEntityProcessor pendant le processus d'indexation DIH du contenu non structuré.
La source de données basePath du fichier de configuration DIH définit l'emplacement temporaire du dossier. Dans cette configuration, onError="continue" est défini de sorte que si le fichier n'existe pas, ou s'il y a d'autres erreurs, le processus DIH continue à s'exécuter et ignore l'erreur. Le nom de colonne de la zone unstructure est une valeur fixe définie sur plainText et ne doit pas être modifié.