
Tableau de bord des opérations totales
Le tableau de bord des opérations totales affiche une répartition du nombre total d'opérations d'index, de recherche, d'obtention et de suppression effectuées sur votre cluster Elasticsearch.
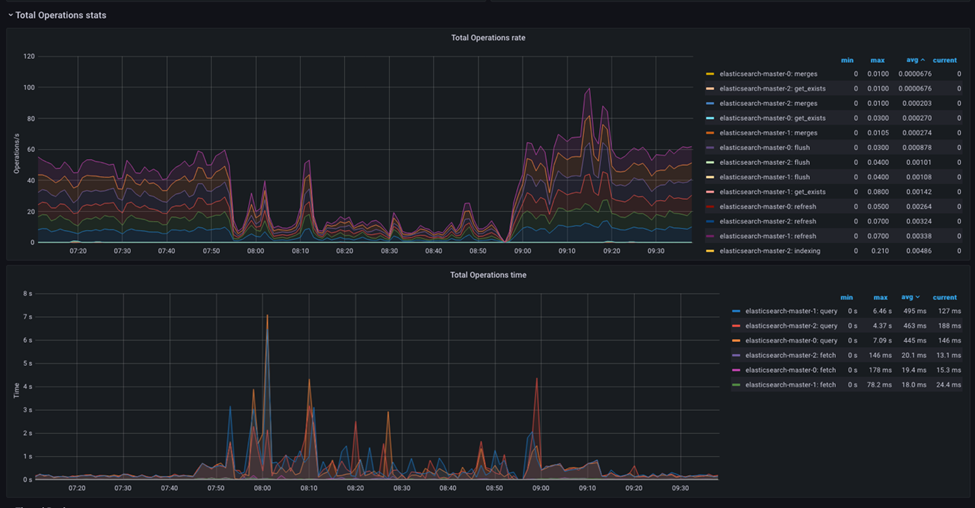
Le tableau de bord visualise le nombre d'opérations effectuées sur votre cluster Elasticsearch, réparties par opérations d'index, de recherche, d'obtention et de suppression.
-
- Taille des opérations totales
- Ce tableau de bord affiche la vitesse à laquelle les opérations sont exécutées sur votre cluster Elasticsearch, réparties par opérations d'index, de recherche, d'obtention et de suppression.
-
- Durée totale des opérations
- Ce tableau de bord affiche la durée totale de chaque opération, répartie par opérations d'index, de recherche, d'obtention et de suppression.
Il peut vous aider à identifier les opérations qui prennent plus de temps que prévu et qui peuvent nécessiter une optimisation.
Surveillance et analyse d'un problème classique
On peut observer les opérations Elasticsearch et les régler pour un seul type de charge de travail ou un mélange de différentes charges de travail d'opérations. Le réglage d'Elasticsearch pour un seul type de charge de travail est relativement simple.
Lorsque vous disposez d'une combinaison d'opérations, par exemple la génération de l'index et le traitement des requêtes de recherche de production, la réussite du réglage dépend de la façon dont le mélange de charge de travail est compris et simulé dans l'environnement de test de performances.
La section suivante décrit le réglage direct de la charge de travail de l'instance pour la création d'un index sur Elasticsearch. Avant de tenter de régler le trafic opérationnel, il s'agira probablement du test d'optimisation initial de l'équipe.
Opérations de type unique d'Elasticsearch
- Utilisation élevée de l'UC
- Si Elasticsearch utilise un pourcentage élevé de l'UC lors de l'indexation, vous pouvez ajouter d'autres ressources de l'UC à votre cluster. Vous pouvez également vérifier si des requêtes ou des processus d'indexation peu performants consomment plus de ressources d'UC que prévu.
- Utilisation élevée de la mémoire
- Si Elasticsearch utilise une grande quantité de mémoire lors de l'indexation, vous pouvez ajouter plus de ressources mémoire à votre cluster. Vous pouvez également vérifier si des requêtes ou des processus d'indexation peu performants consomment plus de ressources mémoire que prévu. En outre, vous pouvez surveiller l'utilisation de la mémoire des caches Elasticsearch, tels que le cache de données de zone, et ajuster la taille du cache en conséquence.
- Taux d'indexation lent
- Si le taux d'indexation est plus lent que prévu, cela peut indiquer qu'Elasticsearch est à court de ressources telles que l'UC ou la mémoire. Vous pouvez vérifier les métriques d'utilisation d'UC et de la mémoire pour voir si elles sont proches de leurs limites. Si tel est le cas, vous devrez peut-être ajouter plus de ressources à votre cluster. Vous pouvez également vérifier si des requêtes ou des processus d'indexation provoquent des goulots d'étranglement ou s'il y a des problèmes d'E/S au niveau du réseau ou du disque.
- E/S élevées au niveau du disque
- Si le niveau d'E/S du disque est élevé lors de l'indexation, vous pouvez ajouter plus de ressources de disque à votre cluster. Vous pouvez également vérifier si des requêtes ou des processus d'indexation peu performants sont à l'origine d'E/S élevées au niveau du disque. En outre, vous pouvez surveiller l'utilisation de l'espace disque et ajuster les paramètres de configuration Elasticsearch, tels que la taille du fragment, pour optimiser l'utilisation du disque.
- Journaux Elasticsearch
- Les journaux Elasticsearch peuvent fournir des informations précieuses sur les erreurs, les avertissements et d'autres problèmes liés aux pénuries de ressources. Vous pouvez consulter les journaux Elasticsearch pour voir s'il existe des messages d'erreur liés aux pénuries de ressources et prendre les mesures appropriées pour les résoudre.
En surveillant ces métriques et en analysant les modèles et les tendances au fil du temps, vous pouvez déterminer si Elasticsearch est à court de ressources et prendre les mesures appropriées pour optimiser les performances de votre cluster pendant le processus d'indexation.
Le cas du segment de mémoire insuffisant
Lorsqu'Elasticsearch présente un segment de mémoire insuffisant, cela peut provoquer divers problèmes, tels que des temps de réponse lents, une latence accrue et même des pannes. Ces comportements instables peuvent être présentés lors de l'exécution d'une seule tâche sur Elasticsearch ou lorsque plusieurs tâches simultanées sont exécutées en même temps sur Elasticsearch, comme dans la génération d'index et le service de requêtes de recherche.
-
- Augmentation de l'activité de récupération de place (GC)
- Le collecteur de place d'Elasticsearch doit s'exécuter plus fréquemment pour récupérer la mémoire à mesure que le segment de mémoire se remplit. Cela peut augmenter l'utilisation de l'UC, entraîner des pauses de GC plus longues et altérer les performances.
-
- Réduction de la taille du cache
- Elasticsearch utilise divers caches pour accélérer les recherches et les requêtes. Lorsque le segment de mémoire est faible, la taille du cache peut être réduite, voire désactivée, ce qui ralentit les temps de recherche.
-
- Hausse des E/S sur le disque
- Si Elasticsearch ne parvient pas à adapter toutes ses données en mémoire, il peut être nécessaire d'échanger des données sur le disque, ce qui augmente les E/S du disque et ralentit les performances.
Il est important de noter qu'Elasticsearch utilise la mémoire native pour divers caches et référentiels de stockage. La configuration généralement recommandée pour le segment de mémoire Elasticsearch consiste à allouer 50 % de la mémoire du pod à l'espace de segment de mémoire JVM. Laissez les 50 % supplémentaires à la mémoire native et au cache de fichiers.
Remarques supplémentaires sur la consommation de mémoire.
- Taille en masse
- L'utilisation de requêtes en masse peut améliorer considérablement les performances d'indexation lors de l'indexation simultanée de plusieurs documents. Toutefois, la taille des requêtes en masse peut également affecter les performances. Si la taille en masse est trop grande, elle peut entraîner l'épuisement des ressources et ralentir le processus d'indexation. Si la taille en masse est trop petite, elle entraîne plus de requêtes et des performances globales plus lentes.
La taille de la requête en masse n'est pas correcte. Testez la taille de la demande en masse avec différents paramètres afin de trouver la taille optimale pour votre charge de travail. Cette configuration peut être effectuée en définissant la taille du fichier de flux NiFi, qui, à son tour, reflétera directement la taille de la requête en masse que NiFi adressera à Elasticsearch.
Il est important de noter qu'Elasticsearch limite la taille maximale d'une requête HTTP à 100 Mo par défaut. Par conséquent, vous devez vous assurer qu'aucune requête ne dépasse cette taille.