
Surveillance et compréhension des métriques Elasticsearch et NiFi
Vous pouvez utiliser Grafana et les outils associés pour analyser les performances du pipeline Ingest et Kibana pour faire de même avec Elasticsearch.
En raison de la forte consommation de ressources, la surveillance doit toujours commencer par les ressources du système d'exploitation et leur utilisation. Identifiez si une ressource est saturée, telle que l'UC (utilisation du processeur), les E/S (réseau, disque ou mémoire), la mémoire, etc. au niveau du système. Il s'agit de la première étape de l'exercice d'optimisation, qui consiste à s'assurer que la solution n'est pas en cours d'exécution avec des ressources système mal configurées, consommées ou étranglées. Le mode de surveillance le plus simple est avec Grafana et Kibana (pour les métriques spécifiques à Elasticsearch), ou tout autre moniteur de niveau système (par exemple, nmon). Si une ressource système est saturée, un ajustement est nécessaire dans l'environnement avant d'essayer toute autre optimisation. Par exemple, il n'est pas utile de régler les threadss/accès concurrents du processeur s'il n'y a pas assez de ressources d'UC disponible dans le système.
Une attention particulière doit être portée au segment de mémoire NiFi et Elasticsearch. Si la taille du segment de mémoire est inadéquate pour la charge de travail, elle devra être adaptée. L'utilisation du segment de mémoire doit être surveillée après chaque modification de l'optimisation. Cela est particulièrement crucial lors de l'augmentation des accès concurrents des processeurs ou des modifications apportées à la taille de bucket.size/flowfile. Ces valeurs de segment de mémoire peuvent être nécessaires pour chaque modification apportée à ces variables de performances clés.
La façon la plus simple d'observer la progression globale de la génération d'index est via le graphique Performances NiFi de Grafana. Nous pouvons observer la vitesse d'exécution globale, identifier la vitesse de groupe de processeurs majeur et afficher la quantité de données générées et poussées vers Elasticsearch.
Grafana
Vous pouvez utiliser Grafana pour analyser les performances du pipeline Ingest. Les deux graphiques les plus utiles sont Articles en file d'attente et Lien d'attente. Pour configurer ces tableaux de bord et d'autres, voir Métriques extensibles pour la surveillance et les alertes.
Dans les connecteurs Ingest NiFi, les groupes de processus WaitLink sont ajoutés entre les groupes de processus pour s'assurer que l'étape précédente est terminée avant le début de l'étape suivante. Ainsi, les étapes suivantes n'utiliseront pas les données actuellement en cours d'utilisation dans un processus non terminé. En outre, cela réduit l'occurrence de différents processus s'exécutant en même temps, ce qui peut entraîner des pics extrêmes au niveau des demandes de ressources pour l'UC, le réseau, la mémoire ou les E/S du disque.
Le temps passé sur WaitLink peut être utilisé pour estimer le temps complet utilisé pour une étape et identifier les étapes dont l'utilisation des ressources et/ou du temps est la plus élevée au sein de la génération. Etant donné que les groupes de processus ne disposent pas tous de WaitLink, le graphique Articles en file d'attente fournit plus de détails sur le temps de traitement dans chaque groupe de processus.
Les graphiques utiles à examiner dans Articles en file d'attente sont les graphiques Service en masse - <XXXX> . Ces groupes de processus envoient les données traitées (documents d'index) à Elasticsearch depuis NiFi. Le plus important est Service en masse - Produit. Etant donné que la courbe commence du début à la fin du pipeline Ingest, nous pouvons utiliser l'horodatage dans Lien d'attente pour obtenir les étapes associées.
Par exemple, les deux graphiques suivants montrent que le plus grand nombre d'articles en file d'attente est à l'étape du produit 1e. Cette observation signifie que le groupe de données de récupération et le groupe de données de traitement peuvent traiter rapidement la tâche et envoyer beaucoup de données au groupe de services en masse pour le transfert.
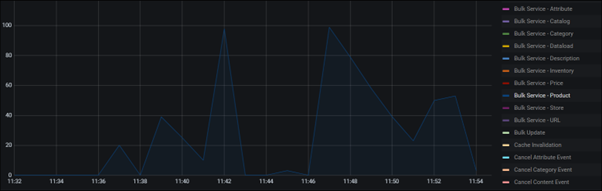
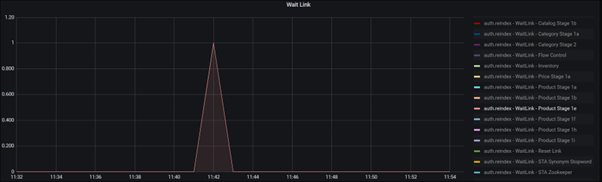
Dans cet exemple, la durée avec 100 éléments en file d'attente est courte et ne constitue donc pas un problème. Si un groupe de processus prend plus de temps, avec un plus grand nombre d'éléments en file d'attente, il s'agit d'un possible goulot d'étranglement dans le pipeline.
Nous pouvons également utiliser Grafana pour surveiller d'autres métriques.
Kibana
Kibana peut être utilisé pour surveiller la consommation de ressources d'Elasticsearch. Pour plus d'informations sur Kibana, reportez-vous à la documentation kibana.
Ce graphique affiche les opérations Elasticsearch de surveillance de Kibana. Pour le processus de création d'index, les métriques clés sont l'utilisation de l'UC, le segment de mémoire JVM et le taux d'opérations d'E/S. Le taux d'opérations d'E/S est la mesure la plus critique, dans le sens où si le taux d'E/S est entièrement utilisé, il n'est pas possible d'accélérer le débit global. Si la vitesse n'est pas acceptable, la meilleure action consiste à examiner des solutions alternatives avec un débit plus élevé.
Compteurs NiFi et rapports
Lors de l'exécution du pipeline Ingest, nous pouvons utiliser les compteurs NiFi ou Grafana pour vérifier le rapport de pipeline.
En raison d'une consommation de ressources élevée, la collecte des compteurs NiFi pour les activités de HCL Commerce est désactivée par défaut.
name: "FEATURE_NIFI_COUNTER"
value: "true"
Après l'avoir activé, vous pouvez afficher le rapport pendant l'exécution du test ou une fois le processus Ingest terminé. L'un des inconvénients est que vous ne pouvez voir qu'un seul rapport pour chaque connecteur. Si vous utilisez le même connecteur pour exécuter un autre pipeline Ingest, le rapport généré pour l'exécution précédente sera supprimé au début du nouveau processus Ingest (ce processus peut prendre quelques minutes).
Une fois qu'un pipeline Ingest est terminé, le rapport Ingest, Métriques Ingest, sera envoyé à l'index run dans Elasticsearch. Vous pouvez configurer Grafana pour afficher le rapport au format que vous avez défini. Les rapports pour les différents pipelines Ingest et les différents connecteurs sont tous stockés. Vous pouvez sélectionner connecteur et runID pour afficher le rapport.
Les données de Métriques Ingest au niveau de Grafana sont différentes de Articles mis en file d'attente/Lien d'attente. Les métriques ne seront envoyées, par NiFi, à Elasticsearch qu'une fois le processus Ingest terminé. Toutefois, Articles mis en file d'attente/Lien d'attente utilisent Prometheus pour collecter des informations au moment de l'exécution.
A des fins d'optimisation, il se peut que vous ne vouliez pas terminer un pipeline Ingest avant de l'avoir à nouveau exécuté ou que le processus échoue à un moment dans le processus Ingest. Dans ce cas, les compteurs NiFi peuvent être plus faciles pour collecter des rapports de certaines étapes d'un pipeline Ingest.