
Tableaux de bord d'unités d'exécution actives
Les tableaux de bord du pool d'unités d'exécution affichent des informations en temps réel sur les unités d'exécution de travail et leurs opérations sur le cluster, avec des métriques, y compris le nombre de tâches en attente d'exécution et le nombre d'unités d'exécution actives. Il est essentiel de comprendre le rôle de chaque pool d'unités d'exécution, comme les pools Generic, Search, Bulk, Index, GET, Write et Analysis, pour résoudre les problèmes et optimiser les performances dans Elasticsearch (ES). En outre, les données de zone et les caches de requête permettent d'accélérer les opérations de recherche, mais peuvent devoir être effacés périodiquement, ce qui entraîne des ralentissements temporaires.
Les tableaux de bord du pool d'unités d'exécution affichent des informations en temps réel sur les unités d'exécution de travail et leur fonctionnement sur le cluster. Les informations se trouvent au niveau du cluster, mais chaque groupe d'unités d'exécution s'affiche par nœud ES.
- Opérations de pool d'unités d'exécution mises en file d'attente.
- Unités d'exécution de pool d'unités d'exécution actives.
Opérations de pool d'unités d'exécution mises en file d'attente indique le nombre de tâches en attente d'exécution, tandis que Unités d'exécution de pool d'unités d'exécution actives indique le nombre d'unités d'exécution qui exécutent les tâches. Les deux métriques sont essentielles pour surveiller l'état de santé et les performances d'Elasticsearch.
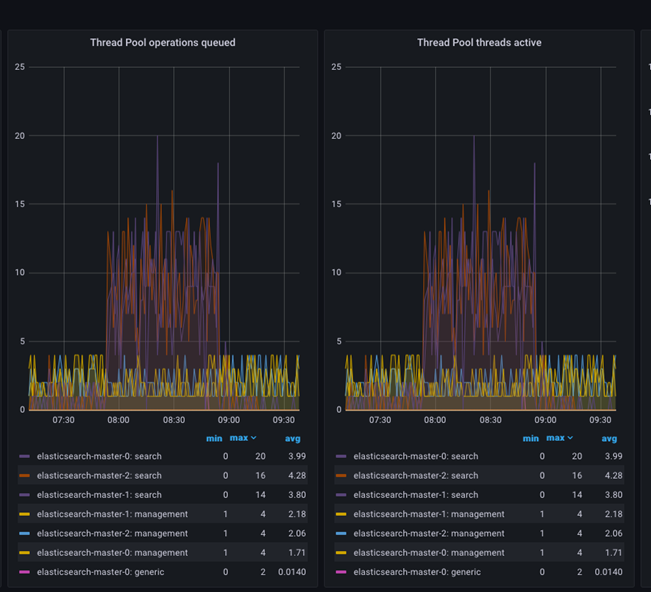
La métrique Opérations de pool d'unités d'exécution mises en file d'attente indique le nombre de tâches en attente d'exécution par le pool d'unités d'exécution. Cela peut se produire lorsque le nombre de tâches soumises au pool d'unités d'exécution dépasse le nombre maximal d'unités d'exécution disponibles pour les exécuter. Lorsque cela se produit, les tâches sont placées dans une file d'attente et exécutées dès qu'une unité d'exécution devient disponible.
La métrique Unités d'exécution de pool d'unités d'exécution actives indique le nombre d'unités d'exécution qui exécutent activement des tâches. Lorsque ce nombre est proche du nombre maximal d'unités d'exécution disponibles, il peut indiquer que le système est soumis à une charge importante et peut rencontrer des problèmes de performances.
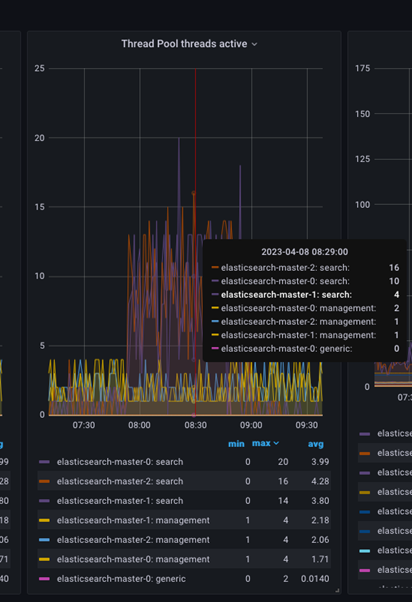
Vous pouvez inspecter davantage les unités d'exécution actives en plaçant le pointeur de la souris sur le graphique à un moment donné pour obtenir le nombre d'unités d'exécution actives à ce moment précis, comme le montre l'image ci-dessous.
- Pool d'unités d'exécution Generic
- Ce pool d'unités d'exécution exécute des tâches qui ne s'intègrent à aucun pool d'unités d'exécution spécialisé. Le pool d'unités d'exécution générique exécute des tâches internes dans Elasticsearch, telles que l'envoi et la réception de requêtes réseau.
-
- Pool d'unités d'exécution Search
- Ce pool d'unités d'exécution est utilisé pour exécuter des requêtes de recherche. Il gère les tâches liées aux opérations de recherche, telles que l'interrogation et le filtrage des données. Le nombre d'unités d'exécution dans le pool d'unités d'exécution de recherche est généralement défini sur le nombre de cœurs d'UC disponibles sur le nœud Elasticsearch.
-
- Pool d'unités d'exécution en masse
- Ce pool d'unités d'exécution exécute des requêtes d'indexation en masse. Il est responsable du traitement des tâches liées à l'indexation de grands volumes de données.
-
- Pool d'unités d'exécution d'index
- Ce pool d'unités d'exécution exécute des requêtes d'indexation qui ne sont pas effectuées en masse. Il est responsable du traitement des tâches liées à l'indexation de documents individuels.
-
- Pool d'unités d'exécution
GET - Ce pool d'unités d'exécution est utilisé pour exécuter des requêtes
GET. Il est responsable du traitement des tâches liées à l'extraction de documents individuels.
- Pool d'unités d'exécution
-
- Pool d'unités d'exécution d'écriture
- Ce pool d'unités d'exécution exécute des opérations liées à l'écriture, y compris l'indexation, la mise à jour et la suppression de documents. Il gère les tâches liées à l'écriture d'opérations qui ne peuvent pas être exécutées sur le pool d'unités d'exécution en masse ou le pool d'unités d'exécution d'index.
-
- Pool d'unités d'exécution d'analyse
- Ce pool d'unités d'exécution est utilisé pour exécuter des tâches d'analyse. Il gère les tâches liées à l'analyse du texte, telles que l'utilisation de jetons (tokenization) et le filtrage.
-
- Pool d'unités d'exécution d'instantané
- Ce pool d'unités d'exécution exécute des instantanés et restaure des opérations. Il est responsable du traitement des tâches liées à la sauvegarde et à la restauration des données.
Note: Le nombre d'unités d'exécution dans les pools d'unités d'exécution en masse, d'index, GET, d'écriture, d'analyse et d'instantané est généralement défini sur un petit nombre, tel que 1 ou 2, pour éviter que le système ne surcharge.
Chaque pool d'unités d'exécution possède ses paramètres, tels que le nombre maximal d'unités d'exécution et la taille de la file d'attente, qui peuvent être configurés pour optimiser les performances en fonction des besoins spécifiques de votre déploiement Elasticsearch.
Le pool d'unités d'exécution d'écriture et le pool d'unités d'exécution de requête de recherche sont les deux unités d'exécution les plus essentielles qui doivent être surveillées de près. Selon le niveau de charge de travail et la combinaison de charge de travail, des paramètres appropriés pour chaque pool d'unités d'exécution peuvent être requis pour contrôler le flux de charge de travail et maintenir le cluster en fonctionnement stable.
Caches internes Elasticsearch :
-
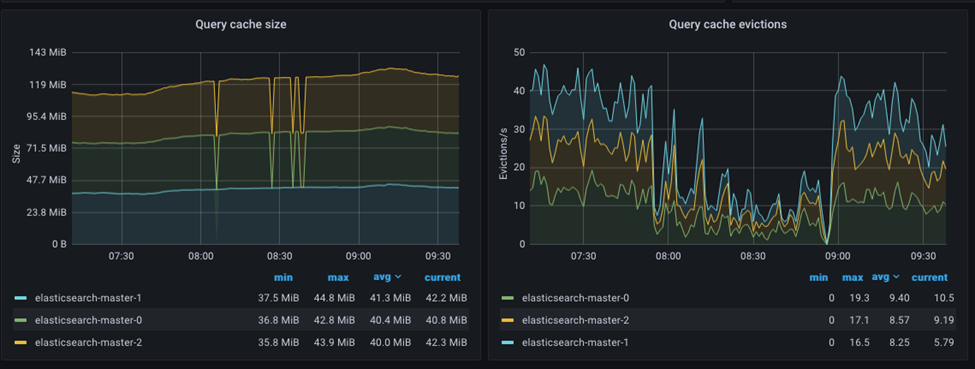
- Cache de données de zone
- Le cache de données de zone est utilisé pour mettre en cache les valeurs de zone pour les zones fréquemment consultées et permet d'accélérer le tri des agrégations et des zones scriptées. Le cache de données de zone est implémenté en tant que cache de référence souple, ce qui signifie que le cache peut être effacé par le récupérateur de place lorsque la mémoire se raréfie.
-
- Cache de requête
- Le cache de requête est utilisé pour mettre en cache les résultats des requêtes fréquemment exécutées et permet d'accélérer les opérations de recherche. Le cache de requête est implémenté en tant que cache LRU (Least Recently Used), ce qui signifie que les requêtes les moins récemment exécutées sont expulsées du cache lorsqu'il devient saturé.
Le cache de zone, par exemple, sera effacé chaque fois qu'une opération d'actualisation d'index ou de fusion d'index est effectuée, ce qui nécessite une nouvelle charge de valeurs de zone du disque vers la mémoire. Chaque fois qu'une opération de réindexation est effectuée, par exemple lorsqu'un nouveau document est ajouté ou modifié, le cache de requête est entièrement supprimé.
Il est important de noter que l'effacement du cache peut entraîner un ralentissement temporaire des performances, car il devra être rempli à nouveau avec de nouvelles données.