Optimisation de la génération d'index et du flux global
Des optimisations sont fournies pour les générations d'index complètes et pour les paramètres d'optimisation. Les améliorations potentielles qui peuvent être implémentées pour les mises à jour d'index en quasi-temps réel (NRT) ne sont pas décrites.
Le processus de génération d'index
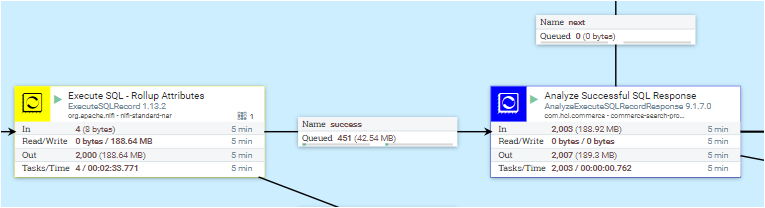
Une génération d'index complète se compose de trois étapes principales : extraction de données, traitement de données et chargement de données. Il existe plusieurs connecteurs prédéfinis, qui se composent de plusieurs groupes de processus à des fins différentes. Généralement, chaque groupe de processus contient des sous-groupes de processus pour gérer les étapes d'extraction, de traitement et de chargement des données associées au processus de génération.
- Extraction de groupe de données : extrayez des données de la base de données ou d'Elasticsearch.
- Traitement de groupe de données : en fonction des données extraites, générez, mettez à jour et/ou copiez les documents d'index.
- Chargement du groupe de données : chargez le document d'index dans Elasticsearch. A partir de l'édition 9.1.3.0 d'HCL Commerce, chaque index a un groupe associé.
Optimisation
En règle générale, les paramètres par défaut fonctionnent pour ce processus, mais la finalisation du processus d'indexation pour un jeu de données de grande taille peut prendre un certain temps. En fonction de la taille du jeu de données et de la configuration matérielle (mémoire, UC, disque et réseau), des améliorations peuvent être apportées aux sous-groupes et aux groupes de processus afin que les flux de processus soient plus rapides et plus efficaces au sein des sous-groupes et entre les sous-groupes connectés.
Extraction de groupe de données
Dans ce groupe, il existe trois sources différentes dont les données peuvent être extraites.
- extraites d'une base de données avec défilement SQL ;
- extraites d'une base de données avec SQL sans défilement ;
- extraites d'Elasticsearch avec défilement.
- Extraire des données d'une base de données avec défilement SQL
-
 Accédez au groupe SCROLL SQL, puis cliquez avec le bouton droit de la souris sur la zone de conception de base et sélectionnez des variables.
Accédez au groupe SCROLL SQL, puis cliquez avec le bouton droit de la souris sur la zone de conception de base et sélectionnez des variables.- scroll.page.size est le nombre de lignes extraites de la base de données par le SQL.
- scroll.bucket.size est le nombre de lignes des données extraites dans chaque compartiment pour traitement. bucket.size détermine la taille des fichiers de flux (et le nombre de documents contenus dans chaque fichier).
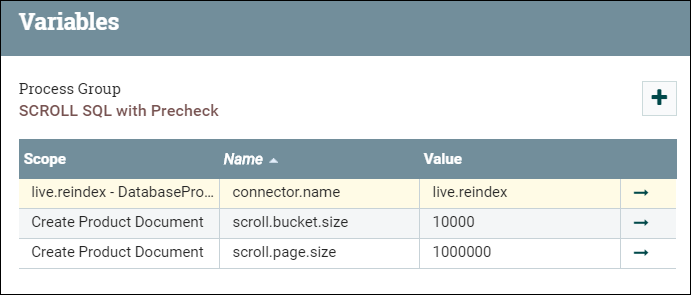
Modifiez les valeurs de scroll.bucket.size et scroll.page.size en fonction des considérations suivantes :
- • Selon la taille du catalogue, le SQL peut prendre un certain temps pour renvoyer les données de réponse vers NiFi. L'objectif de SQL de défilement est de limiter la taille des données qui peuvent être traitées dans NiFi en même temps, afin d'éviter les erreurs de mémoire sur les catalogues de grande taille.
- • Les paramètres de défilement sont optimaux lorsque le temps qu'il faut pour traiter les données est égal au temps que le défilement suivant du SQL prend pour recevoir ses données. Grâce à cette optimisation, le traitement inutile ou le retard d'E/S est réduit.
- • La sortie d'un sous-groupe est transmise tour à tour au sous-groupe de processus connecté suivant. Ce processus doit faire l'objet d'un audit pour s'assurer qu'il n'y a pas de goulot d'étranglement qui peut avoir un impact sur l'efficacité du processus global.
- Extraire les données de la base de données avec SQL sans défilement
-
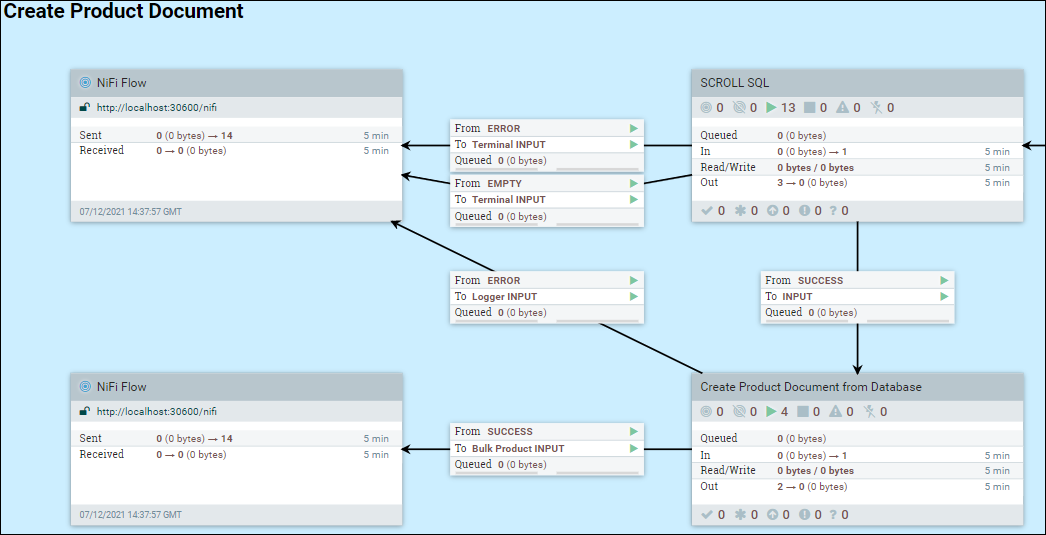
Dans le groupe de processus, le jeu de données est extrait de la base de données à l'aide d'un flux SQL unique. Par exemple, le Find Associations sur DatabaseProductStage1b.
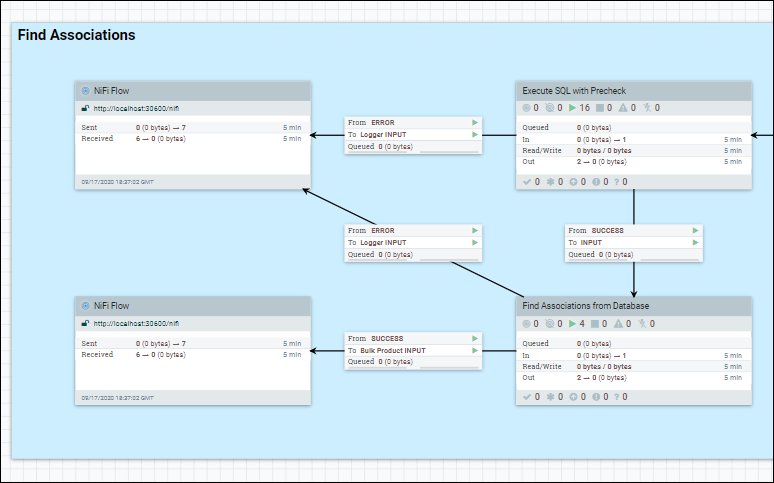
Accédez au groupe Processeur que nous optimisons, cliquez avec le bouton droit de la souris sur la zone de conception de base et sélectionnez des variables.
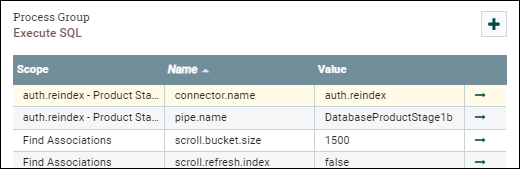
Définissez le paramètre scroll.bucket.size sur le nombre que vous souhaitez.
scroll.bucket.size est le nombre de lignes des données extraites qui sont placées dans chaque compartiment pour traitement. bucket.size détermine la taille des fichiers de flux (et le nombre de documents contenus dans chaque fichier).
- Extraire des données d'Elasticsearch
-
Etant donné que la création d'index est un processus par étape, certaines informations peuvent être ajoutées aux documents d'index existants. Dans ce cas, NiFi doit extraire des données d'Elasticsearch. Prenons l'exemple de l'étape 2 de l'URL.
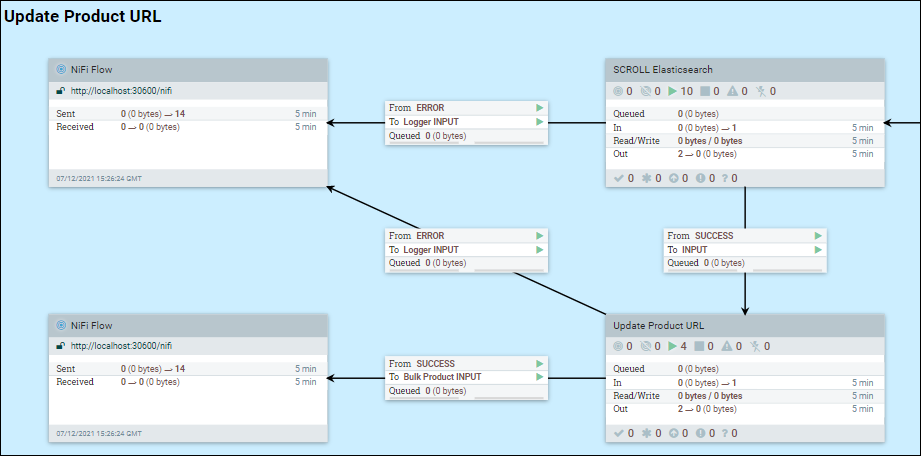
Accédez au groupe SCROLL Elasticsearch, cliquez avec le bouton droit de la souris sur la zone de conception de base et sélectionnez des variables.
Modifiez scroll.bucket.size et scroll.page.size sur les valeurs que vous souhaitez, en fonction des considérations suivantes :
scroll.page.size est le nombre de documents extraits d'Elasticsearch. Si ce nombre est trop petit, NiFi doit établir davantage de connexions à Elasticsearch.
scroll.bucket.size est le nombre de documents provenant des données extraites dans chaque compartiment pour traitement. bucket.size détermine la taille des fichiers de flux (et le nombre de documents contenus dans chaque fichier).
Un autre paramètre utile pour le réglage est scroll.duration. Cette valeur définit la durée pendant laquelle Elasticsearch stockera l'ensemble des résultats de la requête en mémoire. Ce paramètre est utile lorsque vous traitez de nombreux magasins et langues qui s'exécutent en parallèle, où une erreur de fin de défilement peut être rencontrée. Cette erreur indique que vous n'avez plus d'espace de défilement et que la réduction de la durée de défilement force Elasticsearch à libérer plus rapidement des mémoires tampons anciennes ou obsolètes. A l'inverse, l'augmentation de la durée de défilement dans Elasticsearch pour cet index fournira du temps supplémentaire pour terminer les opérations de traitement.
- Traitement de groupe de données
-
Dans l'exemple suivant, le groupe de processus DatabaseProductStage 1a est utilisé.
Accédez à Créer un document de produit à partir de la base de données, cliquez avec le bouton droit de la souris sur Créer un document de produit à partir de la base de données et sélectionnez Configurer. Sous l'onglet PLANIFICATION, mettez à jour la valeur Tâches simultanées pour définir le nombre de threads qui seront utilisés pour le groupe de processus. Lors de l'augmentation du nombre de tâches simultanées, l'utilisation de la mémoire pour le groupe de processus est également augmentée en conséquence. Par conséquent, définir cette valeur sur un nombre supérieur au nombre d'UC allouées au pod, ou au-delà de la quantité de mémoire allouée au pod, peut ne pas être logique et avoir un impact négatif sur les performances.
- Chargement de groupe de documents
-
Accédez au groupe Bulk Elasticsearch. Plusieurs processus sont affichés. Cliquez avec le bouton droit de la souris sur chaque processus et sélectionnez Configurer. Sous l'onglet PLANIFICATION, mettez à jour les valeurs Tâches simultanées sur des valeurs logiques pour votre environnement.
Le processeur Post Bulk Elasticsearch envoie les documents d'index créés à Elasticsearch. Par défaut, Elasticsearch utilisera le même nombre d'UC que le nombre de connexions. Compte tenu du retard ou des pools possibles, le nombre qui est défini pour le processeur Post Bulk Elasticsearch peut être supérieur au nombre d'UC allouées au pod Elasticesearch.
Il est recommandé de considérer tous les processus d'un groupe ensemble. En général, il est préférable d'essayer de faire en sorte que les processus ultérieurs se terminent plus rapidement que les précédents. Sinon, les objets mis en file d'attente consomment de la mémoire supplémentaire et ralentissent l'efficacité globale du traitement.
Considérations générales pour l'optimisation
- Tâches/Threads simultanés
- L'augmentation du nombre de threads qui sont traitées peut aider à améliorer le débit d'un groupe de traitement, mais cela doit être évalué avec soin.
- Taille du compartiment/Taille du fichier de flux
- L'augmentation de la taille du compartiment augmente la taille du fichier de flux, c'est-à-dire le nombre de documents qui sont traités en tant que groupe dans NiFi. Plus le fichier de flux est grand, meilleure est l'efficacité. Toutefois, des ressources limitées du système d'exploitation limiteront la taille maximale du fichier de flux.
- L'optimisation de la taille du fichier de flux est très visible et a un impact sur le système.
- Les fichiers de flux de grande taille ont plusieurs effets secondaires négatifs :
- Ils demandent un segment de mémoire important pour NiFi.
- Ils nécessitent un entonnoir correspondant sur Elasticsearch, pour accepter les données au moment où elles sont acheminées.
- Le temps système GC de NiFi peut devenir excessivement élevé ou NiFi peut arriver à court d'espace de segment avec une erreur
Out of Memory.
- Pression arrière dans les liens entre les processus, les groupes de processus et les sous-groupes de processus
- Dans le pipeline, il existe de nombreux liens entre les étapes. Chaque lien dispose de sa propre file d'attente pour les objets résultants (articles mis en file d'attente) à traiter à l'étape suivante.
-
-