Paramètres ajustables dans la configuration de NiFi et Elasticsearch
Comment modifier les valeurs des paramètres ajustables et certaines valeurs par défaut, et comment elles peuvent être améliorées dans différentes circonstances.
Ressources système, encombrement de mémoire et allocation d'UC
L'environnement (recommandé ou minimal) se compose de plusieurs nœuds qui hébergent les pods Elasticsearch et NiFi. En général, après l'installation initiale, vous aurez trois pods pour Elasticsearch et un pour NiFi.
Dans la configuration minimale, chacun des pods reçoit 6 VCPU et 10 Go de mémoire.
Dans la configuration recommandée, chaque pod reçoit 16 VCPU et au moins 16 Go de mémoire.
L'ajustement ou l'augmentation des ressources allouées est possible. Toutefois, dans ces cas, des tests supplémentaires pour valider de telles modifications de la configuration sont nécessaires pour garantir la stabilité et l'opérabilité.
Espace disque par nœud
La quantité d'espace disque dont vous avez besoin dépend fortement de la taille de votre index. Etant donné que cela varie considérablement d'une installation à l'autre, il n'y a pas de figure recommandée unique. Pour estimer, considérez qu'un index d'un million d'articles de catalogue exécutés sur la configuration système recommandée génère un index d'une taille d'environ six gigaoctets.
Toutefois, ce nombre ne correspond pas à vos besoins réels. Les fichiers d'index sont datés et s'accumulent avec le temps sur le disque. En règle générale, fournissez au moins dix fois l'espace disque de la taille d'index prévue pour refléter cette variabilité et supprimez quotidiennement les anciens fichiers d'index. Dans le cas de l'index de six gigaoctets, cela signifierait l'allocation d'au moins soixante gigaoctets et l'exécution d'un travail standard pour supprimer les fichiers périmés.
NiFi
La vitesse de traitement du jeu de données et la vitesse résultante de la création de l'index de recherche sont le résultat du débit que l'on peut atteindre dans le cluster NiFi et Elasticsearch. Plusieurs paramètres améliorent et optimisent le débit pour l'encombrement matériel donné, à savoir les threads des processeurs NiFi et la taille du compartiment.
Forums
Chaque processeur dans NiFi a la possibilité de traiter des flowfiles simultanément. Pour ce faire, vous devez affecter plus de threads au processeur ou définir la variable Tâches simultanées sur une valeur supérieure à 1. La capture d'écran suivante représente un processeur NLP qui est défini sur 16 tâches simultanées, soit le nombre de VCPU disponibles sur le nœud.
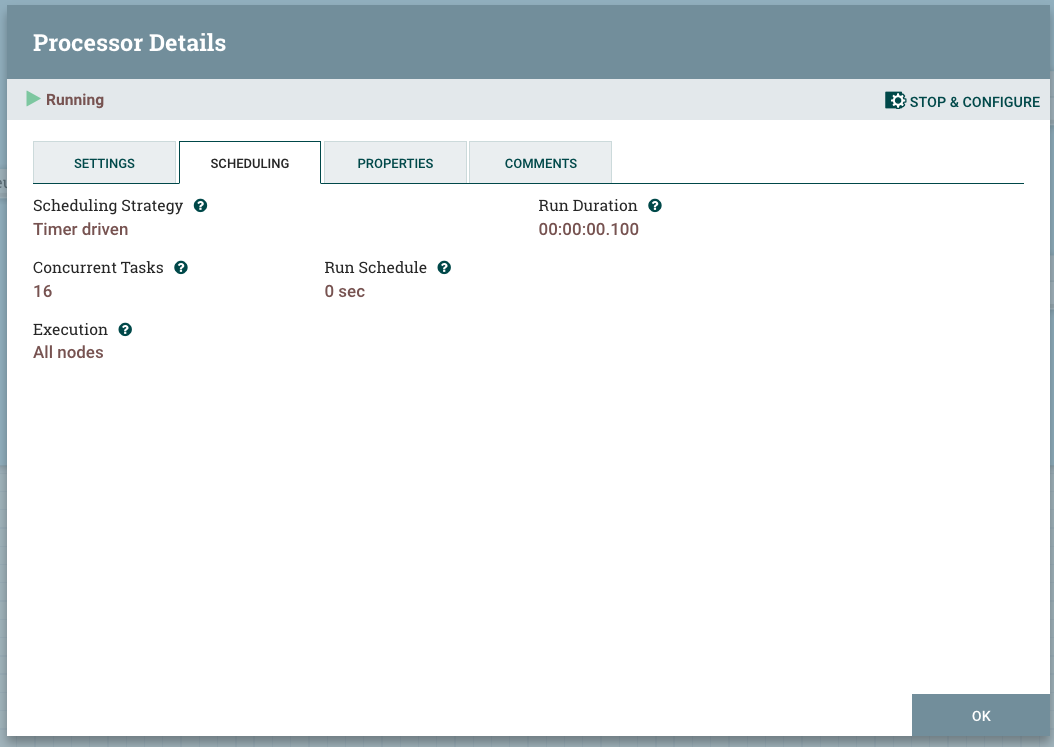
L'augmentation des threads du processeur entraîne une amélioration du débit du processeur. Les threads supplémentaires multiplie la bande passante du processeur autant de fois qu'il y a de threads, si le processeur procède à un traitement computationnel (c'est-à-dire que vous pouvez bénéficier d'une mise à l'échelle linéaire). : une évolutivité non linéaire qui se terminerait par une saturation).
Dans le cas du processeur NLP, le processeur est purement computationnel et la limite de threads est considérée comme étant le même nombre de VCPU disponibles pour le pod NiFi.
Taille du compartiment
La taille du compartiment (scroll.bucket.size) est un autre paramètre que vous pouvez modifier pour améliorer la bande passante d'un processeur. Elle modifie la taille du flowfile qui est traité. En augmentant la taille du compartiment, vous augmentez la taille des données qui seront traitées par un seul processeur en tant que groupe.
Les changements de taille de compartiment sont un peu plus difficiles à implémenter. L'emplacement de la variable se trouve sur les paramètres de deuxième niveau du groupe de processeurs.
Par exemple, pour DataBaseProductStage1a :
Le niveau supérieur ressemble à ceci :
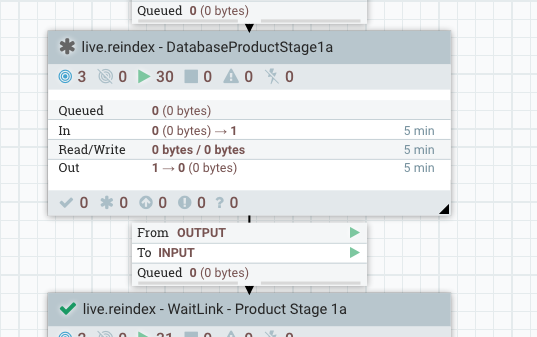
Explorez un niveau, cliquez avec le bouton droit de la souris sur Créer un document de produit et sélectionnez des variables.
La fenêtre Variables s'ouvre. Ici, vous pouvez modifier la valeur de la taille du compartiment.
LISTAGG() et Serialize
Dans le pipeline Ingest, la plupart des SQL utilisent l'agrégat pour combiner plusieurs lignes. En raison d'une limitation de la base de données (en particulier avec Oracle) et de la taille des données, LISTAGG peut dépasser les limites mises en place lors des générations d'index live.reindex et auth.reindex. Pour résoudre le problème, vous pouvez désactiver LISTAGG.
Vous pouvez définir LISTAGG localement ou globalement. Pour le définir localement, modifiez l'attribut flow.database.listagg.
UpdateAttribute, qui mettent à jour les attributs des fichiers de flux. Par exemple, si vous souhaitez définir flow.database.listagg="false" pour AttributeStage1b dans auth.reindex, définissez-le dans les propriétés comme suit : .- Accédez à .
- Cliquez deux fois sur le processeur Définir le décalage de défilement et la taille de la page.
- Cliquez sur ARRETER ET CONFIGURER dans le coin supérieur droit du processeur pour arrêter le processeur.
- Cliquez sur l'onglet Propriétés du processeur, puis sur l'icône + pour ajouter la propriété
flow.database.listagget définir sa valeur surfalse. - Redémarrez le processeur.
 Pour les versions 9.1.11 et ultérieures, utilisez le nœud final suivant :
Pour les versions 9.1.11 et ultérieures, utilisez le nœud final suivant : https://data-query/search/resources/api/v2/configuration?nodeName=ingest&envType=auth{ "global": { "connector": [ { "name": "attribute", "property": [ { "name": "flow.database.listagg", "value": "false" } ] } ] } }Vous pouvez effectuer des modifications globales à l'aide des profils Ingest. Pour plus d'informations et un exemple de modification de LISTAGG à l'aide d'un profil Ingest, voir Configuration d'Ingest via REST.
Lorsque l'agrégation de liste est désactivée, la procédure SQL renvoyera plus de lignes et NiFi utilisera le processus Sérialiser pour traiter les données renvoyées. Dans ce cas, la durée de traitement des données sera bien plus longue. Pour tenir compte de cela, les valeurs page.size et bucket.size pour le processus SQL et le nombre de threads du processus Sérialiser doivent être augmentées.
Elasticsearch
La section suivante va discuter de quelques améliorations qui peuvent être apportées à la configuration d'Elasticsearch pour augmenter le débit global et la vitesse de génération d'index.
- Taux d'actualisation des indices
- Par défaut, Elasticsearch actualise périodiquement les indices toutes les secondes, mais uniquement sur les indices qui ont reçu une ou plusieurs demandes de recherche au cours des 30 dernières secondes. Le schéma d'indexation d'HCL Commerce fixe cet intervalle à 10 secondes par défaut.
Toutefois, s'il est viable, désactivez ce comportement en lui définissant sa valeur sur -1. Si la désactivation de cette option n'est pas viable, un intervalle plus long, tel que 60 secondes, aura également un impact. En augmentant le taux d'actualisation sur des périodes plus longues, les documents mis à jour à partir de la mémoire tampon sont moins fréquemment écrits dans les index (et éventuellement écrits sur le disque). Cela améliore la vitesse de traitement sur Elasticsearch, étant donné qu'un nombre moins élevé d'événements d'actualisation aura pour effet d'augmenter la bande passante des ressources pour recevoir des données. En outre, des mises à jour en masse du système de fichiers sont toujours plus souhaitables. De l'autre côté de l'équation, les intervalles d'actualisation plus longs entraînent une augmentation de la taille de la mémoire tampon tout en essayant de prendre en charge toutes les données entrantes.
Pour plus d'informations sur le paramètre d'intervalle d'actualisation d'index, voir la documentation Elasticsearch.
Pour définir une valeur personnalisée :Assurez-vous d'arrêter le processeur. Sélectionnez et éditez l'objet JSON en remplaçant la valeur refresh_interval par la valeur de votre choix.
- Indexation des tailles de la mémoire tampon
-
L'augmentation des tailles de mémoire tampon d'indexation permettra d'accélérer l'opération d'indexation et améliorera la vitesse de génération globale de l'index.
La valeur est définie dans la variable indices.memory.index_buffer_size et est généralement définie sur 10 % de la taille du segment de mémoire par défaut.
Définissez une valeur plus élevée, sur 20 % de la taille du segment de mémoire.
- Configuration de l'entonnoir Elasticsearch
- Le cluster Elasticsearch a des exigences d'entonnoir compliquées. En général, pour une utilisation ordinaire, le cluster Elasticsearch déterminera les tailles initiales des threads sur chaque serveur en fonction du nombre d'UC disponibles pour ce pod. En termes simples, si le pod est configuré pour autoriser jusqu'à six UC, les threads de travail seront également limités au même nombre.
Toutefois, cela peut ne pas être suffisant lorsque vous traitez des catalogues de grande taille et des compartiments de grande taille. Dans le cas de la génération d'index, une requête de mise à jour en masse est émise depuis NiFi vers Elasticsearch. Le nœud maître Elasticsearch reçoit le corps de la requête, qui est composé de plusieurs documents, et pour chaque document, il détermine le fragment dans lequel il doit être stocké. Une connexion est ouverte ves le nœud/fragment approprié afin que le document puisse être traité.
Par conséquent, la mise à jour en masse se termine par l'utilisation de plusieurs connexions et il est tout à fait possible d'arriver à court de threads et de connexions. Si Elasticsearch arrive à court de connexions, un code de réponse,
429, est renvoyé. Cela interrompra le processus de génération d'index et la génération d'index échouera.Pour répondre aux besoins d'un plus grand nombre de connexions et de threads, le serveur Elasticsearch peut être configuré pour démarrer avec plus de threads et une file d'attente de connexions plus profonde sur chaque nœud. Le fichier suivant décrit les configurations Elasticsearch clés (le contenu est défini dans le fichier de configurationes-config.yaml) :replicas: 3 minimumMasterNodes: 2 ingress: enabled: true path: / hosts: - es.andon.svt.hcl.com tls: [] volumeClaimTemplate: accessModes: [ "ReadWriteOnce" ] storageClassName: local-storage-es resources: requests: storage: 15Gi esJavaOpts: "-Xmx12g -Xms12g" resources: requests: cpu: 2 memory: "14Gi" limits: cpu: 14 memory: "14Gi" esConfig: elasticsearch.yml: | indices.fielddata.cache.size: "20%" indices.queries.cache.size: "30%" indices.memory.index_buffer_size: "20%" node.processors: 12 thread_pool: search: size: 100 queue_size: 10000 min_queue_size: 100 max_queue_size: 10000 auto_queue_frame_size: 10000 target_response_time: 30s thread_pool: write: size: 100 queue_size: 10000Le fichier définit deux pools de threads, write et search.
Pour chaque pool de threads, nous pouvons définir les paramètres suivants :- size : nombre de threads de travail par nœud.
- queue_size : nombre de connexions qui peuvent être reçues et suivis dans la file d'attente de connexions
- min_queue_size : taille minimale de la file d'attente de connexions.
- max_queue_size : taille maximale de la file d'attente, au-delà de laquelle Elasticsearch enverra le code de réponse 429.
Les valeurs réelles doivent être spécifiques à l'environnement et à sa configuration.
L'augmentation des threads de travail à 100 et du pool de connexions à 10 000 suffit pour les catalogues d'un million d'articles sur un cluster Elasticsearch de 3 nœuds et 3 fragments avec les configurations par défaut en place.
Pour appliquer les modifications, le cluster Elasticsearch doit être réinstallé à l'aide du nouveau fichier de configuration.
Les étapes suivantes décrivent le processus :- Supprimez le cluster Elasticsearch existant.
helm delete -n elastic elasticsearch - Réinstallez le cluster Elasticsearch à l'aide du fichier de configuration modifié.
helm install elasticsearch elastic/elasticsearch -f es_es_config.yaml -n elastic
Partitionnement
- Un fragment d'index ne doit pas dépasser 40 % du stockage total disponible de son cluster de nœuds.
- Une taille de fragment d'index ne doit pas dépasser 50 Go. Généralement, l'index fonctionne mieux lorsque sa taille est inférieure à 25 Go par fragment.
- Le nombre et la taille des documents entre les fragments doivent être similaires.