


idresgen utility
If your XML content already supplies identifiers, you do not have to run the idresgen utility.
The idresgen utility includes an error reporter that generates a log file if there is an error.
The following are examples of situations in which you might want to use the idresgen utility:
- Loading new content in XML format when identifiers for the data are required
- Updating content when identifiers exist for an object in the database
The idresgen utility can supply actual identifiers, or identifiers can be resolved with the following techniques:
- Internal-alias resolution
- To use internal-alias resolution with the idresgen utility, an alias is placed in the primary-key attribute (identifier) in the XML file. The alias can then be used throughout the XML file to refer to that element. This process eliminates the need for a program to determine the unique indexes necessary to build the XML file.
- Properties-file specification
- The idresgen utility in the loading utilities can use a Java properties file to determine which columns of a primary table should be used as lookups for tables that require the identifier of a primary table. A table is primary if it is listed in the KEYS or SUBKEYS table.
- Unique-index resolution
- In the idresgen utility, unique-index resolution uses any specified unique indexes on a table as a means of determining an identifier. For example, MEMBER_ID plus IDENTIFIER is a unique index on the CATALOG table and can therefore be used as a resolution point to the primary key CATALOG_ID of the CATALOGDSC table.
The idresgen utility can analyze the database schema to determine whether a unique index fulfills its requirements. The idresgen utility looks for a unique index only when there is no entry in the properties file for the table that is being analyzed or when there is no properties file. If these conditions are true, a unique-index check is performed. The unique index is considered valid if it exists and does not include the primary key for the table.
Before you run this utility, ensure that you have complete the required configuration tasks:
- Configure the loading utilities.
- Configure tracing and logging for the loading utilities.
- Configure the idresgen utility.
In addition to the trace log and message log for the loading utilities, this utility produces the following log file:
 WC_installdir/logs/idresgen.db2.log
WC_installdir/logs/idresgen.db2.log
 WC_installdir/logs/idresgen.oracle.log
WC_installdir/logs/idresgen.oracle.log
Run this utility as the non-root WebSphere Commerce user ID. Do not run
this command as root.
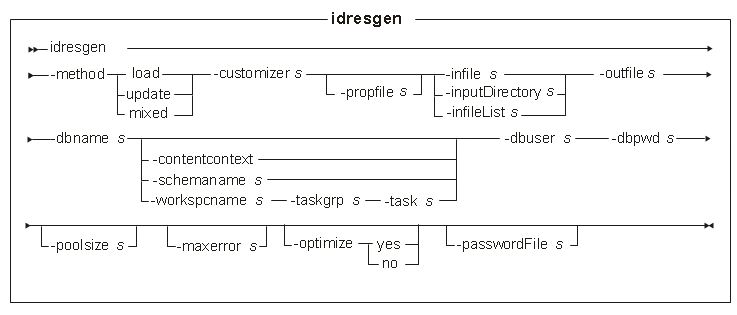
Utility command
The idresgen utility has the following file name:
-
idresgen.sh
-
idresgen.cmd
Parameter values
- -method
- Required: Method to be used in processing the input file. The default method is
load.
The following methods are supported:
- load
- The input file contains only records that do not exist in the database. The idresgen utility generates new identifiers for the records in the input files.
- update
- The input file contains only records that exist in the database. The idresgen utility locates the identifiers in the database. If a record does not exist in the database, the idresgen utility is not able to resolve the identifier for this record and it indicates that an error occurred.
- mixed
- The input file contains both records that exist in the database and records that do not exist in the database. The idresgen utility creates new identifiers for records only if the records do not exist in the database. Otherwise, the existing identifier is obtained from the database.
- -customizer
- Name of the customizer property file to be used for your WebSphere Commerce database. When
you specify the customizer property file with this parameter, omit the ".properties" file extension.
Specify one of the following customizer values:
- (Not required) Do not specify this parameter if you are using DB2
Universal Database.
- Required: Specify one of the following values:
- ISeries_RESWCSID_Customizer
- Specify this customizer value if you are using the native JDBC driver.
When you specify this value, the idresgen utility uses the values that are specified in the following file:
WC_installdir/properties/ISeries_RESWCSID_Customizer.properties
- Toolbox_RESWCSID_Customizer
- Specify this customizer value if you are using the IBM Toolbox for Java JDBC driver.
When you specify this value, the dtdgen utility uses the values that are specified in the following file:
WC_installdir/properties/Toolbox_RESWCSID_Customizer.properties
If you specify this customizer value, you must specify the hostname as the -dbname parameter. The following command is an example of invoking the idresgen utility:
./idresgen.sh -method mixed -customizer Toolbox_RESWCSID_Customizer -infile ./myinfile.xml -outfile ./myoutfile.xml -dbname MY.HOSTNAME.COM -dbuser instance -dbpwd mypass
Note: Toolbox_RESWCSID_Customizer must be specified
when you use a remote iSeries database. If this parameter is not specified, an error is thrown when
you run acpload. - Required: OracleConnectionCustomizer
When you specify this value, the idresgen utility uses the values that are specified in the following file:
WC_installdir/properties/OracleConnectionCustomizer.properties.
- -propfile
- Optional: The full path to a text file that contains Java properties in the form of name-value
pairs. The file is used to define the look-aside column names for foreign key identifier lookup and
the select predicate for main table (such as CATEGORY and PRODUCT) queries. You can omit entries in
this file for tables that have a unique index defined that does not include the identifier.
If you do not specify this parameter, the default file is used. The default file is WC_installdir/properties/IdResolveKeys.properties.
Note: The parameter value can be the path to a file for specifying unique-index data that might not necessarily be retrievable from the database. For example, if you are loading access control data, you can set the parameter value to be the path to the ACIdKeys.properties file:WC_eardir/properties/ACIdKeys.properties
This file is used to resolve the ID values for access control data. If you need to update this file, the file requires 2 mandatory key and value pairsNAMEDELIMITER- This key and value pair specifies the character that is used as a delimiter for column-names in
the user-specified unique-index. For example,
NAMEDELIMITER=@ SELECTDELIMTER- This key and value pair specifies the character that is used a delimiter for physical columns in
the database that would comprise that unique-index. For example,
SELECTDELIMITER=:
ATTRIBUTE=@LANGUAGE_ID@NAME@CATENTRY_ID: LANGUAGE_ID NAME CATENTRY_ID, whereATTRIBUTEis the table for which the user-defined unique index is specified.@LANGUAGE_ID@NAME@CATENTRY_IDare the column names (language_id, name, catentry_id), or aliases that idresgen utility assumes for the column names, within the user-defined unique-indexLANGUAGE_ID NAME CATENTRY_IDare the actual names of the database columns for the user-defined unique index. The column names must be separated by spaces within the file
- -infile
- Name of the input XML document that contains table records. The wcs.dtd
file must be in the same directory as the XML file.Note: The table names and column names in the wcs.dtd are case-sensitive, so the table name and column names that are provided in the input XML file should have the same case as what is provided in the wcs.dtd.
- -inputDirectory
- Full path of the directory that contains only XML files that contain table records. The wcs.dtd file must also be in this directory. If the directory contains any files other than wcs.dtd file and files that contain table records, the idresgen utility command fails.
- -infileList
- The full path to a text file that contains a comma-separated list of XML files that contain table records.
- -outfile
- Required: Name of the output XML file to be produced. This file can be used as input to the massload utility.
- -dbname
-
- Name of the target database.
- The Oracle TNS name for the database.
- Depending on the JDBC driver you use to connect to the database, specify one of
the following drivers:
- Native JDBC driver
- The database name as displayed in the relational database directory (WRKRDBDIRE).
- IBM Toolbox for Java JDBC driver
- The fully qualified host name of the database system. If you are using the IBM Toolkit for Java JDBC driver, you must specify the -schemaname parameter.
Note: If your database is on a remote IASP and the database name is different from the hostname, the value of dbname that is passed to a utility:
For example,-dbname "hostname/schemaName;database name=db_Name;cursor hold=false"-dbname "TORASCAT.yourcompany.com/demo;database name=CATDB;cursor hold=false"
 Note: For DB2 UDB databases, the DB2 Type 4 JDBC driver is
used, where the Type 4 database name is prefixed with the database server and port. For example,
db_server:db_port/db_name.
Note: For DB2 UDB databases, the DB2 Type 4 JDBC driver is
used, where the Type 4 database name is prefixed with the database server and port. For example,
db_server:db_port/db_name. - -contentcontext
- Optional: Tells the utility to use the base schema (production-ready data). This parameter cannot be specified with the -schemaname or the -workspcname parameters.
- -schemaname
- Optional: Name of the target database schema.
If this parameter is not specified when you run the utility, the utility looks for a name-value pair in the customizer property file that specifies the value of SchemaName. If this pair is present in the property file, the utility uses the value that is specified.
If there is more than one schema in the database, you must provide -schemaname parameter to ensure that the name of the correct schema is passed to IDResolver. If there is more than one schema and you do not supply the -schemaname parameter, you receive an SQL error.
If the -schemaname parameter does not include a
command-line or property-file specification, the utility defaults to the value of the
-dbuser parameter. - -workspcname
-
This parameter can be used only when you are loading data into a workspace on an authoring server. This parameter cannot be used when loading data on a staging server or a production server.
Optional: The workgroup code that is the system generated identifier for the workspace, not the name that is assigned to the workspace by the Workspace Manager. Specify this parameter if you want the idresgen utility to resolve identifiers for a workspace.If you specify the workspace parameter, you must specify the following optional parameters:
- -taskgrp
-
This parameter can be used only when you are loading data into a workspace on an authoring server. This parameter cannot be used when loading data on a staging server or a production server.
The task group code that is the system generated identifier for the task groups, not the name that is assigned to the task group by the Workspace Manager. - -task
-
This parameter can be used only when you are loading data into a workspace on an authoring server. This parameter cannot be used when loading data on a staging server or a production server.
The task code that the system generated identifier for the task, not the name that is assigned to the task by the Workspace Manager.
- -dbuser
-
- Required: Name of the user that is connecting to the database.
- Required: The ID of the instance user.
- Oracle user ID connecting to the database.
- -dbpwd
-
- Required: Password for the user that is connecting to the database.
- Required: Password for the user that is connecting to the database.
- -poolsize
- Optional: Number of identifiers to be reserved. If you do not specify this parameter, the idresgen utility reserves 50 identifiers.
- -maxerror
- Optional: Number of errors after which the idresgen utility terminates. If you do not specify this parameter, the idresgen utility terminates after one error.
- -optimize
- Optional: Specifies whether the idresgen utility checks for duplicate records before the utility
writes resolved records to the output file. If you do not specify this parameter, the idresgen
utility checks for duplicate records.
- yes
- Check for duplicate records.
- no
- Do not check for duplicate records. Specify this value if you are using the XML file to delete records from the database.
Eliminating duplicate XML elements improves the performance of the massload utility when you are loading the XML file that is produced by the idresgen utility.
When you use the update or mixed method with the idresgen utility, the idresgen utility automatically recognizes XML elements that are being resolved that are duplicates of records that exist in the database. The duplicates are not written to the output file that is specified by the -outfile option, the idresgen utility logs them to trace.txt file. The duplicate entries in the trace.txt file are made without counting the duplicates as actual errors.
Each element is checked for duplication by comparing that element attributes to the corresponding database table columns. An element must always contain all of the attributes that are required by the DTD. However, elements might also contain optional attributes. When the utility checks for duplicates, the idresgen utility uses all of the attributes that are contained by each element. If any element is different, the element is not considered to be a duplicate.
When you use the mixed method with the idresgen utility, only elements that are already determined to be non-candidates for insertion are further processed to check for duplicates. This increases the efficiency of the process.
Duplicate-record checking is not performed by the idresgen utility when you use the load method. When you use this method, the loadable elements are not supposed to exist in the database when you use this method.
If you are deleting data from the database loading the loading utilities, you should set -optimize to no.
Note: Relationship elements (such as cattogrp and catgrprel) might not be reported as duplicates. - passwordFile
- Optional: The full path to the password.properties file that contains the
encrypted password for the user who is connecting to the database. For instance,
C:\password.properties. By default, the idresgen utility requires the user
password to be included in plain-text directly as a command-line parameter when you run the utility.
When you include the password as a command-line parameter it can be possible for other users to view
the password. Instead, you can use the passwordFile parameter to identify the
password file that includes the encypted user password. The password.properties file contains the following content:
Where encrypted_pwd is the password that is encrypted with the wcs_encrypt utility.dbUserPassword=encrypted_pwd