crawler utility
You can use the crawler utility to crawl HTML and other site files from WebSphere Commerce starter stores to help populate the site content search index.
Since your store catalog is structured data, it can be indexed from your database. Your store
however can have site-wide pages that are not necessarily associated to your catalog. This utility
can produce two sets of artifacts:
- HTML pages that are compiled crawled pages.
- A manifest file that acts as a directory of the compiled pages.
The utility output is used by the indexer. For more information, see Indexing site content with WebSphere Commerce Search
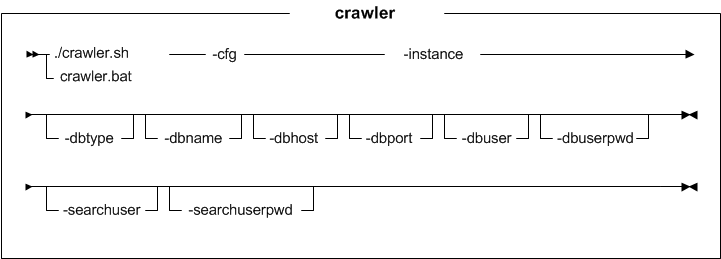
Parameter values
- cfg
- The location of the site content crawler configuration file. For example, solrhome/droidConfig.xml
- instance
- The name of the WebSphere Commerce instance with which you are working (for example, demo).
- dbtype
- Optional: The database type. For example, cloudscape, db2, or oracle.
- dbname
- Optional: The database name to be connected.
- dbhost
- Optional: The database host to be connected.
- dbport
- Optional: The database port to be connected.
- dbuser
-
 Optional: The name of the user that is connecting to the database.
Optional: The name of the user that is connecting to the database. Optional: The user ID that is connecting to the database.
Optional: The user ID that is connecting to the database. - dbuserpwd
- Optional: The password for the user that is connecting to the database.
- searchuser
- Optional: The user name for the search server.
- searchuserpwd
- Optional: The password for the search server user.
Example
From the following directory:

 WC_installdir/bin
WC_installdir/bin WCDE_installdir\bin
WCDE_installdir\bin

crawler.bat -cfg cfg -instance instance_name [-dbtype dbtype] [-dbname dbname] [-dbhost dbhost] [-dbport dbport] [-dbuser db_user] [-dbuserpwd db_password] [-searchuser searchuser] [-searchuserpwd searchuserpwd]crawler.sh -cfg cfg -instance instance_name [-dbtype dbtype] [-dbname dbname] [-dbhost dbhost] [-dbport dbport] [-dbuser db_user] [-dbuserpwd db_password] [-searchuser searchuser] [-searchuserpwd searchuserpwd]-
crawler.bat -cfg cfg -instance instance_name [-dbtype dbtype] [-dbname dbname] [-dbhost dbhost] [-dbport dbport] [-dbuser db_user] [-dbuserpwd db_password] [-searchuser searchuser] [-searchuserpwd searchuserpwd] 
crawler.bat -cfg cfg [-searchuser searchuser] [-searchuserpwd searchuserpwd]
Running the utility using a URL
You can run the utility by using a URL on the
WebSphere Commerce Search server.
http://solrHost:port/solr/crawler?action=actionValue&cfg=pathOfdroidConfig&
Where action is the action that the
crawler should perform. The possible values are:
- start
- Starts the crawler.
- status
- Shows the crawler status.
- stop
- Stops the crawler.
The utility generates a log file. You can use this log file to refine your search parameters or
diagnose failures. By default, the log file is named crawler.log and is written
into the logs directory.
Note: You can change the log file's name and location
by editing the crawler-logging.properties file, which by default is located in
the directory %WCTOOLKIT%\workspace\WC\xml\config\dataimport. The file path and
filename for the log file are defined in the
java.util.logging.filehandler.pattern
entry in this file.