
Variables réglables clés
Les variables réglables clés suivantes peuvent être ajustées pour améliorer le temps de traitement global :
Nombre d'unités d'exécution du processeur (tâches simultanées)
Le processeur par défaut s'exécute sur une seule unité d'exécution, en ne traitant qu'un seul fichier de flux à la fois. Si le traitement simultané est souhaité, le nombre de tâches simultanées qu'il peut effectuer peut être ajusté. Définissez le nombre d'unités d'exécution pour le groupe de processus en modifiant la valeur Tâches simultanées du processeur (sous l'onglet Configuration du processeur ou Planification).
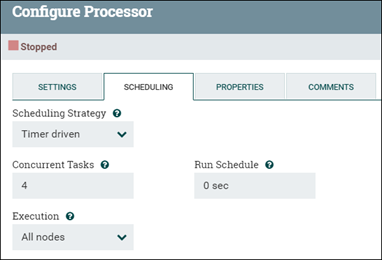
Si une UC peut effectuer plusieurs tâches, l'augmentation des unités d'exécution disponibles pour le processeur augmente le débit du processeur. Le processeur de transformation (comme dans NLP) et le processeur de mise à jour en masse sont deux exemples de ce type. Cette mise à jour n'est pas utile pour tous les processeurs. La plupart des processeurs sont fournis avec une configuration par défaut qui prend en compte cette variable et n'a pas besoin d'être modifiée. Lorsque les tests de performances révèlent un goulot d'étranglement devant les processeurs, la configuration par défaut peut bénéficier d'un réglage supplémentaire.
Lorsque le processeur peut traiter les fichiers de flux à la même vitesse qu'ils ne le sont, la valeur Tâches simultanées est idéale, ce qui empêche les empilages importants de fichiers de flux dans la file d'attente du processeur. Etant donné qu'un tel équilibre peut ne pas toujours être atteint, la meilleure configuration se concentrerait sur la réduction de l'empilage des fichiers de flux dans la file d'attente.
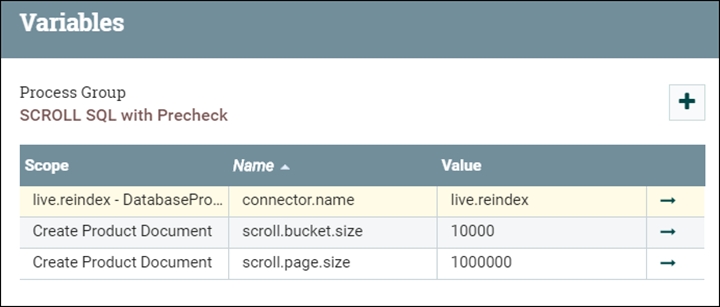
Taille du compartiment (scroll.bucket.size)
- scroll.bucket.size
- scroll.bucket.size est le nombre de lignes des données extraites dans chaque compartiment pour traitement.
- bucket.size
- bucket.size détermine la taille des fichiers de flux (et le nombre de documents qui sont contenus dans chaque fichier).
La taille du compartiment est optimale lorsque vous constatez que le fichier de flux est facilement traité via le système (y compris le chargement Elasticsearch). L'augmentation de la taille (nombre de documents dans le fichier de flux) augmente le débit. Toutefois, lorsqu'il est augmenté jusqu'à atteindre une taille très élevée, le débit se réduit et diminue graduellement. En même temps, les ressources du système (NiFi et Elasticsearch) vont être sous pression, ce qui réduit le débit.
Taille de la page de défilement (scroll.page.size)
- scroll.page.size
- Le paramètre scroll.page.size contient le nombre de lignes extraites de la base de données par le SQL. Le SQL s'exécute plusieurs fois (une fois avec chaque page tournée) si le nombre de lignes extraites est inférieur au nombre total de lignes dans le tableau.
Les paramètres de défilement sont optimaux lorsque le temps qu'il faut pour traiter les données est égal au temps que le défilement suivant du SQL prend pour recevoir ses données. Cette amélioration élimine les temps de traitement et d'E/S inutiles. Parmi les autres facteurs à prendre en compte figurent l'espace mémoire disponible dans NiFi pour contenir l'ensemble de résultats lors de l'analyse syntaxique et du fractionnement en fichiers de flux, ainsi que le nombre total de fichiers de flux qui seraient créés simultanément dans NiFi. Si la taille de la page de défilement est plus grande, vous devez vous attendre à un impact sur les opérations NiFi. Lorsque vous atteignez cette limite, vous pouvez augmenter les ressources NiFi ou réduire la taille de la page de défilement à un degré tolérable.
- scroll.page.size est le nombre de documents extraits d'Elasticsearch. Si ce nombre est trop petit, NiFi doit établir davantage de connexions à Elasticsearch.
- Le paramètre scroll.bucket.size est le nombre de documents inclus dans les données extraites traitées dans chaque compartiment. bucket.size détermine la taille des fichiers de flux (et le nombre de documents qui sont contenus dans chaque fichier).