
Interprétation des modèles et optimisation de la solution de recherche
Vous disposez de plusieurs options pour améliorer les performances globales. Le réglage de l'ingestion inclut également l'apprentissage des effets secondaires possibles et des résultats négatifs.
Un cas de transfert de données lent – traitement multitâche
L'opération de transfert de NiFi vers Elasticsearch est un exemple de segment sous-optimal que vous pouvez détecter facilement. Cette opération est généralement gérée par le processeur de mise à jour en masse, qui apparaît dans Grafana comme une croissance rapide du nombre de documents entrants, qui atteint alors un pic, suivi d'un ralentissement et d'une faible baisse du nombre de documents en raison de la vitesse de transfert. Comme vous pouvez le voir, elle se présente comme suit :
En raison du ralentissement de la vitesse de transfert vers Elasticsearch, vous pouvez voir une faible diminution des documents dans la file d'attente. Vous pouvez augmenter cette vitesse en ouvrant davantage de connexions vers Elasticsearch et en configurant davantage d'unités d'exécution pour le processeur de mise à jour en masse afin d'augmenter le débit.
Lorsque le nombre total d'unités d'exécution est élevé, le graphique suivant représente ce qui se passe sur le système : ![]()
Lorsque le processeur de mise à jour en masse est configuré avec seulement trois unités d'exécution, la configuration initiale montre un faible épuisement des documents. Lorsqu'il est configuré avec des unités d'exécution 16, l'angle de décélération augmente considérablement et, lorsqu'il est configuré avec des unités d'exécution 64, il s'améliore encore plus. La distinction importante est que l'augmentation du nombre d'unités d'exécution dans ce processeur augmente le nombre de connexions HTTP ouvertes de NiFi à Elasticsearch, tandis que l'utilisation de l'UC résultante reste presque inchangée.
D'autres processeurs, tels que le groupe de processus NLP, pourraient bénéficier d'une observation et d'une amélioration similaires. La concurrence maximale possible dans le système est limitée par le nombre de cœurs d'UC physiques disponibles pour le pod NiFi lors de l'utilisation de processeurs liés au pod comme NLP.
Effets secondaires de l'augmentation de l'unité d'exécution
L'augmentation du nombre d'unités d'exécution de processeur est une modification risquée qui doit être effectuée par petits incréments plutôt que par de grands incréments. Il n'est pas recommandé de passer de 3 à 64 unités d'exécution, par exemple. Effectuez des modifications incrémentielles plus petites de 16, 32, et éventuellement de 64 unités d'exécution, en testant chaque incrément et en observant les résultats. On observe qu'après 32 unités d'exécution par UC, les avantages sont négligeables dans la plupart des cas.
En outre, les ressources de système d'exploitation disponibles pour le pod/la JVM où NiFi s'exécute doivent être particulièrement prises en compte. Un processeur lié à l'UC, par exemple, ne bénéficie de la concurrence que s'il existe des cœurs disponibles sur l'UC. D'autre part, l'augmentation de la concurrence entre les processeurs augmente la taille du segment de mémoire de la JVM et la mémoire native requise. Pour détecter et corriger de telles situations, il est essentiel de surveiller les valeurs de segment de mémoire et la mémoire globale.
Effets secondaires de l'augmentation de la taille du compartiment
L'augmentation de la taille du compartiment affecte considérablement les ressources du système NiFi, telles que le segment de mémoire et, plus important encore, la mémoire native. Etant donné que la mémoire native est utilisée comme zone de mise en mémoire tampon lors de l'envoi des données vers Elasticsearch, cette augmentation agrandit l'encombrement de mémoire total du pod.
La détection et la capture d'un tel échec est une occurrence rare qui est souvent négligée. L'un de ces événements est partagé ici, avec le point vers les valeurs des métriques :
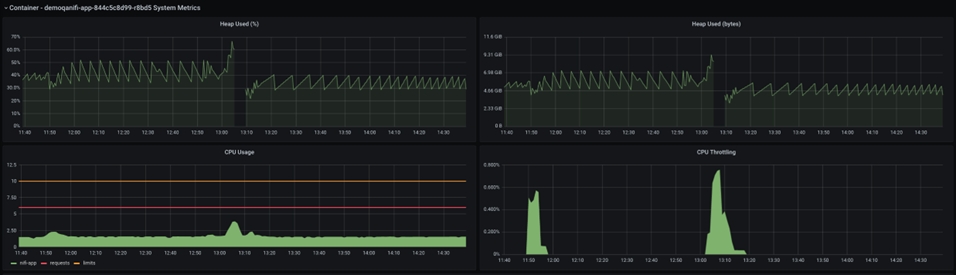
La taille du segment de mémoire Java est affichée dans le graphique ci-dessus. La brève pause au milieu du graphique reflète la panne et le redémarrage du pod NiFi. Si vous observez l'UC avant la panne, vous pouvez voir que les hausses d'utilisation de l'UC, mais la taille du segment de mémoire n'atteint jamais 100 %, au lieu de rester autour de 70 %, qui est une taille de segment de mémoire raisonnable.
Toutefois, le graphique ci-dessous montre une image totalement différente :
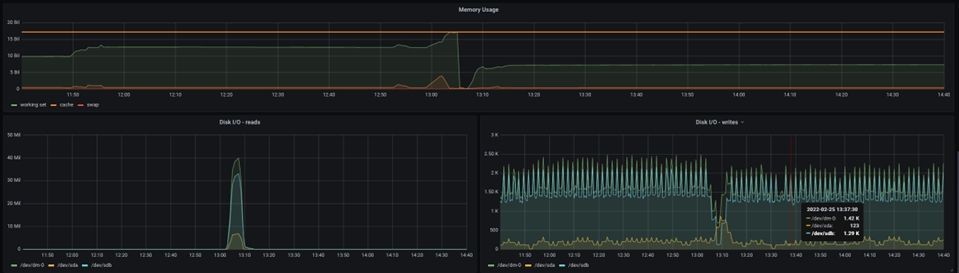
La mémoire totale affectée au pod est visible ici et vous pouvez voir que la mémoire demandée atteint la mémoire maximale allouée au moment de la panne de la machine virtuelle Java NiFi. Par conséquent, plus de mémoire doit être allouée pour prendre en charge une taille de compartiment plus grande.
Avec une grande taille de compartiment, un problème différent peut survenir : Elasticsearch peut ralentir considérablement l'importation de données à mesure que la taille du fichier de flux augmente, au point que les avantages dans NiFi sont complètement annulés et que le traitement se dégrade en raison de l'importation de données Elasticsearch. Organisez et suivez votre test Ingest pour différentes valeurs de taille de compartiment afin d'éviter de telles situations et des résultats déroutants.
Un cas de traitement lent - réglage de la taille de défilement
Le ralentissement de la distribution des données à NiFi est la troisième raison la plus courante du retard de traitement des données. Cela peut être dû au manque de puissance de traitement de la base de données, à un réglage incorrect ou à une personnalisation inefficace. Bien que ce problème soit mieux traité du côté de la base de données, il est parfois beaucoup plus efficace d'optimiser l'accès aux données NiFi afin de minimiser l'impact de la surcharge de la base de données sur l'exécution d'Ingest.
Dans ce cas particulier, le ralentissement sera visible dans les graphiques Grafana comme un temps d'inactivité entre les pics de l'élément mis en file d'attente. Cela se produit lorsque le paramètre scroll.size est configuré pour être relativement faible par rapport à la taille totale du tableau de la base de données à laquelle on accède. Scroll.size doit idéalement correspondre au temps de traitement, où le temps de requête de la base de données doit être égal au temps de traitement NiFi des données extraites. Toutefois, dans des cas particuliers où le SQL s'exécute plus longtemps que le traitement NiFi, vous pouvez observer cela comme des pics courts dans le graphique des éléments interrogés, espacés par une ligne à plat/inactive.
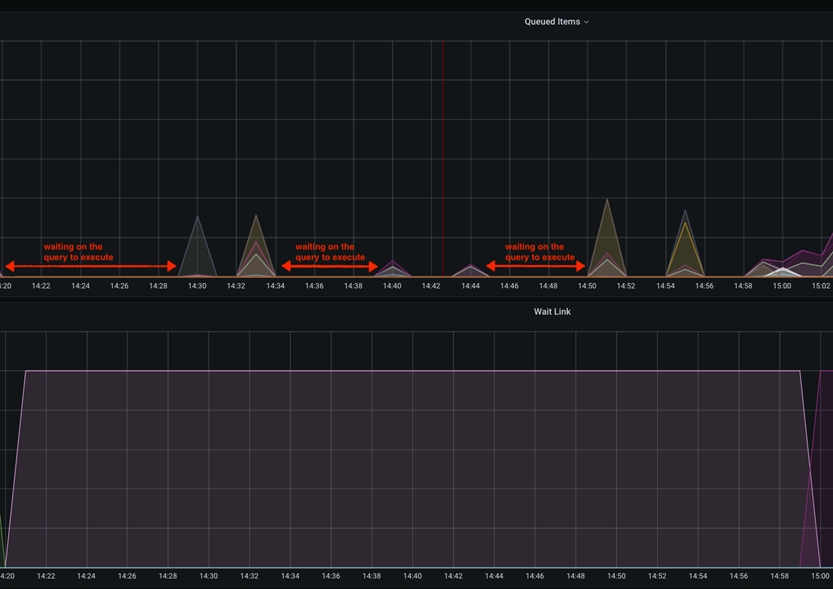
Ce temps d'inactivité entre les extractions des données de base de données peut être atténué en augmentant la valeur scroll.page.size pour atteindre un nombre plus élevé. Par exemple, si la base de données comporte un total de 1 M articles catalogue et que scroll.page.size est défini sur 100000 éléments, l'ensemble du processus implique 10 itérations. Cela indique que les éléments dans la file d'attente ont 10 pics, avec des intervalles de temps d'inactivité. Vous pouvez réduire le temps d'attente de 50 % en augmentant scroll.page.size jusqu'à 200000, en réduisant ainsi les cycles à 5 cycles. Vous devez définir scroll.page.size sur 1M de sorte que l'ensemble des données puisse être extrait dans un cycle et qu'une seule période d'inactivité pour la phase de traitement soit observée. Le graphique suivant présente l'un de ces cas :
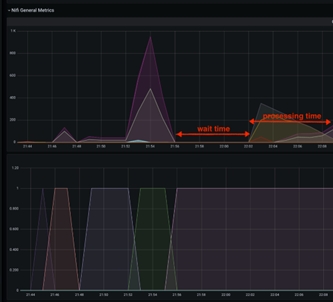
Effet secondaire à partir de très grandes tailles de défilement
Etant donné que l'effet de la modification du pod NiFi peut être considérable, cet ajustement mineur doit être soigneusement examiné. Etant donné que toutes les données sont envoyées à NiFi en même temps, vous aurez besoin de suffisamment de stockage et de RAM pour que le pod fonctionne correctement. Si NiFi est à court de segments de mémoire, de mémoire native ou d'espace de stockage, une surveillance et une modification minutieuses sont nécessaires pour maintenir des performances optimales.
Trouver le juste équilibre
Dans l'ensemble, la stratégie décrite doit fournir un test de performances surveillé et mesuré et le réglage des opérations NiFi/Elasticsearch. Bien que certaines variables d'optimisation aient plus d'impact sur le système, vous devez prendre en compte les trois pour obtenir un débit optimal du système.
En raison des effets secondaires, de très grandes modifications de variable d'optimisation peuvent avoir un impact négatif sur le temps de traitement total. Il convient de noter à nouveau que la modification minutieuse des valeurs doit être surveillée et mesurée, en s'assurant que chaque changement individuel produit un changement positif (améliore) pour le temps de traitement global.
Autres points à prendre en compte
- Taille de la mémoire cache
"[${TENANT:-}${ENVIRONMENT:-}live]:services/cache/nifi/Price": localCache: maxSize: -1 maxSizeInHeapPercent: 8 (default 2) remoteCache: enabled: false remoteInvalidations: publish: false subscribe: false "[${TENANT:-}${ENVIRONMENT:-}auth]:services/cache/nifi/Inventory": localCache: maxSize: -1 maxSizeInHeapPercent: 8 (default 2) remoteCache: enabled: false remoteInvalidations: publish: false subscribe: false "[${TENANT:-}${ENVIRONMENT:-}auth]:services/cache/nifi/Bulk": localCache: maxSize: -1 maxSizeInHeapPercent: 4 (default 1) remoteCache: enabled: false remoteInvalidations: publish: false subscribe: false "[${TENANT:-}${ENVIRONMENT:-}auth]:services/cache/nifi/Wait": localCache: maxSize: -1 maxSizeInHeapPercent: 4 (default 1) remoteCache: enabled: false