抽出、変換、ロード (ETL)
ETL (Extract (抽出)、Transform (変換)、Load (ロード)) とは、あるデータベースから別のデータベースにデータを転送する 3 つのデータベース機能を結合したデータベース使用のプロセスです。最初の段階の「抽出」では、さまざまなソース・システムからデータを読み取って抽出します。第 2 段階の「変換」では、データを元の形式から、ターゲット・データベースの要件を満たす形式に変換します。最後の段階の「ロード」では、新しいデータがターゲット・データベースに保存され、これでデータの転送処理が完了します。
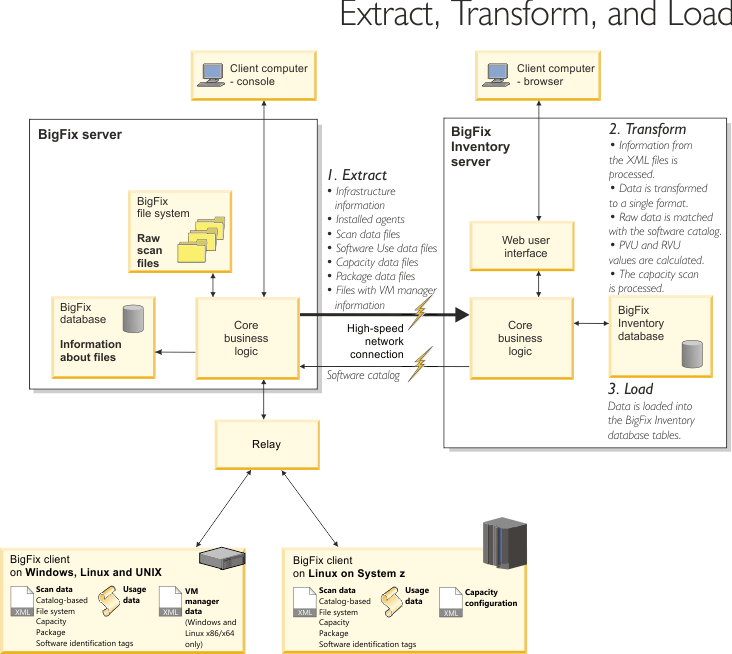
BigFix Inventory の「抽出」段階では、BigFix サーバーからデータを抽出します。このデータには、インフラストラクチャー、インストールされたエージェント、および検出されたソフトウェアに関する情報が含まれます。また ETL は、新しいソフトウェア・カタログが使用可能かどうかを検査したり、エンドポイントに存在するソフトウェア・スキャンおよびファイルに関する情報を収集したり、VM マネージャーからデータを収集したりします。
- 多数の小さなファイルが BigFix サーバーから取得されます (抽出)。
- インストールされたソフトウェア・パッケージおよびプロセス使用状況データに関する情報が含まれている中小規模の多くのファイルが解析されます (変換)。
- 解析されたデータがデータベースに取り込まれます (ロード)。
ETL のプロセスのパフォーマンスは、1 回のインポート中に処理するスキャン・ファイルの数、使用状況の分析、およびパッケージ分析によって異なります。主要なボトルネックは、ストレージ・パフォーマンスです。短時間で多くの小さなファイルを読み取り、処理してから BigFix Inventory データベースに書き込む必要があるためです。適切にスキャンをスケジュールしてインフラストラクチャー内のコンピューターに分散することで、ETL プロセスの所要時間を短縮し、そのパフォーマンスを高めることができます。
ETL プロセスの所要時間に影響する重要な要因として、前回のスキャン以降にファイル・システムで実施された更新の量があります。セキュリティー更新や重大なシステム・アップグレードなどの操作を行うと、変更対象のすべてのファイルに関する情報を処理する必要があるため、ETL の実行時間が長くなる場合があります。例えば、火曜日に Microsoft が定期更新をリリースするため、Windows プラットフォームが数多くある環境では水曜日のインポートに時間がかかることになります。