Dans cette leçon, vous configurez le connecteur que vous avez créé à l'étape précédente à l'aide de NiFi.
About this task
Utilisez le lien suivant pour NiFi : http://hostname/IP:30600/nifi/
Note:
- Cette leçon utilise le nom du connecteur "custom". Veillez à remplacer "custom" par le nom du connecteur que vous avez créé à l'étape précédente.
- Si vous êtes sur la page d'accueil de NiFi où vous pouvez afficher tous les processeurs, vous devrez peut-être faire défiler l'écran vers la droite du pipeline et effectuer un zoom avant pour trouver les processeurs requis.
Procedure
Pour configurer le connecteur dans NiFi, procédez comme suit.
-
Mettez à jour les propriétés du processeur custom-_Template-Schema.
-
Allez au nouveau pipeline "custom" et cliquez deux fois sur custom-_Template-Schema.
-
Cliquez deux fois sur le groupe de processus Mise à jour du schéma.
-
Recherchez le groupe de processus Configurer le schéma d'index Elasticsearch.
-
Recherchez et cliquez avec le bouton droit de la souris sur Spécifier le schéma à mettre à jour et arrêtez le processeur.
-
Cliquez deux fois sur le processeur pour modifier les paramètres.
-
Allez dans l'onglet Propriétés et mettez à jour la propriété param.schema avec la valeur product.
-
Cliquez sur Appliquer.
-
Démarrez le processeur en cliquant avec le bouton droit de la souris et en sélectionnant Démarrer.
-
Mettez à jour le processeur Renseigner le schéma d'index.
-
Arrêtez le processeur.
-
Cliquez deux fois sur le processeur pour modifier les paramètres.
-
Mettez à jour la propriété Valeur de remplacement avec la valeur suivante :
{ "properties":{ "custom":{ "properties":{ "x_profitMargin":{ "type":"float", "coerce":"true", "doc_values":"true", "ignore_malformed":"false", "index":"true", "store":"true" } } } } }
-
Démarrez le processeur.
-
Mettez à jour le processeur Définir le SQL personnalisé et le nom d'index.
Note: Assurez-vous que les données de prix de revient sont disponibles dans votre base de données. Ce connecteur ne vérifie pas si le SQL renvoie des résultats. Si les données de prix de revient ne sont pas disponibles dans la base de données, les données renvoyées pour le SQL sont vides et entraînent des erreurs. Pour vérifier que les données de prix de revient sont présentes dans la base de données, vérifiez le connecteur d'indexation via auth.reindex > DatabasePriceStage1 > Rechercher des prix > Exécuter SQL avec vérification préalable.
-
Accédez au nouveau pipeline custom et double-cliquez sur custom -_Template -DatabaseETL.
-
Allez dans Canal du connecteur personnalisé > Exécuter SQL.
-
Dans le groupe
Exécuter un processus SQL, recherchez le processus Définir un SQL personnalisé.
-
Faites un clic droit sur Définir un SQL personnalisé et arrêtez le processeur.
-
Cliquez deux fois sur le processeur pour modifier les paramètres.
-
Mettez à jour la propriété ingest.database.sql avec la valeur suivante :
SELECT OP.CATENTRY_ID, CASE WHEN OP.PRICE <> 0 THEN (OP.PRICE - CP.PRICE) / OP.PRICE * 100 ELSE NULL END AS PROFIT_MARGIN FROM (SELECT O.CATENTRY_ID CATENTRY_ID, P.PRICE PRICE FROM OFFER O INNER JOIN OFFERPRICE P ON (O.OFFER_ID = P.OFFER_ID AND P.CURRENCY = 'USD') INNER JOIN TRADEPOSCN ON (O.TRADEPOSCN_ID = TRADEPOSCN.TRADEPOSCN_ID AND TRADEPOSCN.NAME = 'Extended Sites Catalog Asset Store') WHERE (O.STARTDATE IS NULL OR CURRENT_TIMESTAMP > O.STARTDATE) AND (O.ENDDATE IS NULL OR O.ENDDATE > CURRENT_TIMESTAMP) AND O.PUBLISHED = 1 ) OP LEFT OUTER JOIN (SELECT OFFER.CATENTRY_ID CATENTRY_ID, OFFERPRICE.PRICE PRICE FROM OFFER INNER JOIN OFFERPRICE ON (OFFER.OFFER_ID = OFFERPRICE.OFFER_ID AND OFFERPRICE.CURRENCY = 'USD') INNER JOIN TRADEPOSCN ON (OFFER.TRADEPOSCN_ID = TRADEPOSCN.TRADEPOSCN_ID AND TRADEPOSCN.NAME = 'My Company Cost Price List' )) CP ON (CP.CATENTRY_ID = CP.CATENTRY_ID) INNER JOIN CATENTRY C ON C.CATENTRY_ID = CP.CATENTRY_ID WHERE OP.CATENTRY_ID = CP.CATENTRY_ID ${extCatentryAndSQL}
-
Cliquez sur Appliquer.
-
Cliquez avec le bouton droit de la souris et sélectionnez Démarrer dans le menu contextuel pour démarrer le processeur.
-
Mettez à jour le processeur Transformer le document - Mapper les champs d'index à partir de la base de données.
-
Accédez à .
-
Faites un clic droit sur le processeur et arrêtez-le.
-
Double-cliquez sur le processeur pour modifier ses paramètres. La fenêtre Configurer les processeurs s'ouvre.
-
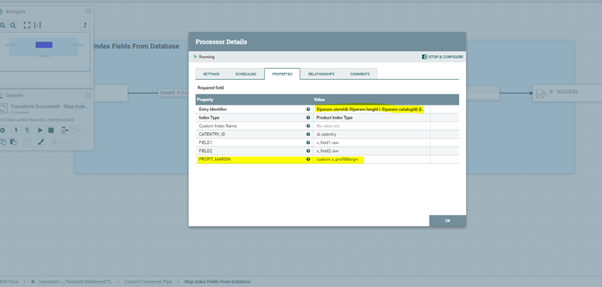
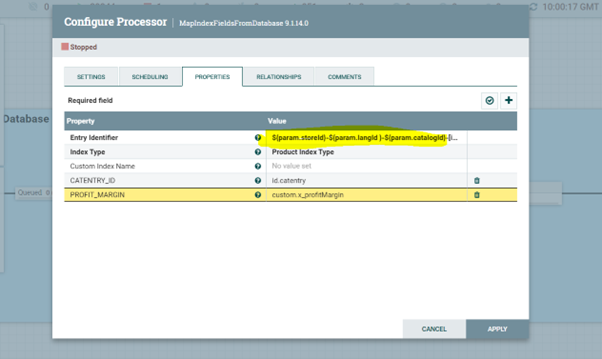
Sous l'onglet Propriétés de la fenêtre Configurer les processeurs, mettez à jour la propriété Identifiant d'entrée avec la valeur
${param.storeId}-${param.langId }-${param.catalogId}-[id.catentry].
-
Ajoutez une nouvelle propriété nommée PROFIT_MARGIN et attribuez-lui la valeur
custom.x_profitMargin.
Votre fenêtre
Configurer les processeurs ressemblera à ce qui suit :
-
Cliquez sur Appliquer.
-
Ouvrez la fenêtre Détails du processeur, supprimez les propriétés FIELD1 et FIELD2 de l'onglet Propriétés. Cliquez sur OK.
-
Créer une version pour custom-_Template-Schema.
-
Cliquez avec le bouton droit de la souris sur custom-_Template-Schema.
-
Cliquez sur .
-
Cliquez avec le bouton droit de la souris sur custom-_Template-Schema.
-
Cliquez sur .
-
Ajoutez le Flow Name requis et enregistrez.
Dans ce tutoriel, le Flow Name = ProfitMarginSchemaUpdateConnector.
-
Créez une nouvelle version pour le custom-_Template-DatabaseETL.
-
Cliquez avec le bouton droit de la souris sur le groupe de processus custom-_Template-DatabaseETL.
-
Cliquez sur .
-
Cliquez avec le bouton droit de la souris sur le groupe de processus custom-_Template-DatabaseETL.
-
Cliquez sur .
-
Ajoutez le Flow Name requis et enregistrez.
Dans ce tutoriel, le Flow Name = ProfitMarginDatabaseConnectorPipe.
-
Joignez le connecteur personnalisé à votre auth.postindex ou live.postindex en procédant comme suit :
-
A l'aide de l'interface utilisateur Swagger, accédez à .
-
Cliquez sur Essayez-le.
-
Saisissez comme id la valeur auth.postindex.
-
Pour le corps de l'API, utilisez le code suivant.
{ "Licensed Materials": "Property of HCL Technologies Limited. (c) Copyright HCL Technologies Limited 1996, 2023.", "_name": "Post re-indexing connector descriptor for HCL Commerce Ingest service to be used with the Authoring environment", "_usage": { "// This is the connector descriptor of a post reindexing connector to be used with HCL Commerce Ingest service.": "", "// It is designed for performing a list of post indexing operations after the main part of a full re-indexing is completed.": "" }, "name": "auth.postindex", "environment": [ "auth", "data", "toolkit", "live" ], "description": "This is the connector for customization to perform a post re-indexing operation.", "pipes": [ { "// ": "------------- Preparation Stage -------------", "// Preparing database specific settings for this indexing pipeline": "", "name": "ReindexLink", "label": "ReindexLink" }, { "name": "ProfitMarginSchemaUpdateConnector", "label": "ReindexLink-ProfitMarginSchemaUpdateConnector" }, { "name": "ProfitMarginDatabaseConnectorPipe", "label": "ReindexLink-ProfitMarginDatabaseConnectorPipe" }, { "// ": "------------- End of dataflow -------------", "// The connector dataflow terminates here by generating a log summary through the Logging Service": "", "name": "Terminal", "label": "Terminal" } ] }
-
Cliquez sur Exécuter.
-
Extraye le connecteur par version.
-
Exécutez les commandes suivantes :
Note: Le nom du conteneur Docker utilisé dans cet exemple est commerce_registry_1. Remplacez-le par le nom réel du conteneur Docker.
-
docker exec -it commerce_registry_1 bash
-
/opt/nifi-registry/scripts/export_flow.sh ProfitMarginSchemaUpdateConnector>/opt/nifi-registry/flows/ProfitMarginSchemaUpdateConnector.json
-
/opt/nifi-registry/scripts/export_flow.sh ProfitMarginDatabaseConnectorPipe>/opt/nifi-registry/flows/ProfitMarginDatabaseConnectorPipe.json
-
exit
-
docker cp commerce_registry_1:/opt/nifi-registry/flows/ProfitMarginDatabaseConnectorPipe.json ./ProfitMarginDatabaseConnectorPipe.json
-
docker cp commerce_registry_1:/opt/nifi-registry/flows/ProfitMarginSchemaUpdateConnector.json ./ProfitMarginSchemaUpdateConnector.json
Vous pouvez également extraire le canal du connecteur via l'interface NiFi Registry.
- Lancez l'interface NiFi Registry et localisez le nom de flux que vous souhaitez exporter, par exemple ProfitMarginSchemaUpdateConnector ou ProfitMarginDatabaseConnectorPipe.
- Cliquez sur le bouton Action et sélectionnez Exporter la version.
- Sélectionnez la version la plus récente et cliquez sur Exporter.
-
Copiez ProfitMarginSchemaUpdateConnector.json et ProfitMarginDatabaseConnectorPipe.json dans votre environnement d'exécution.