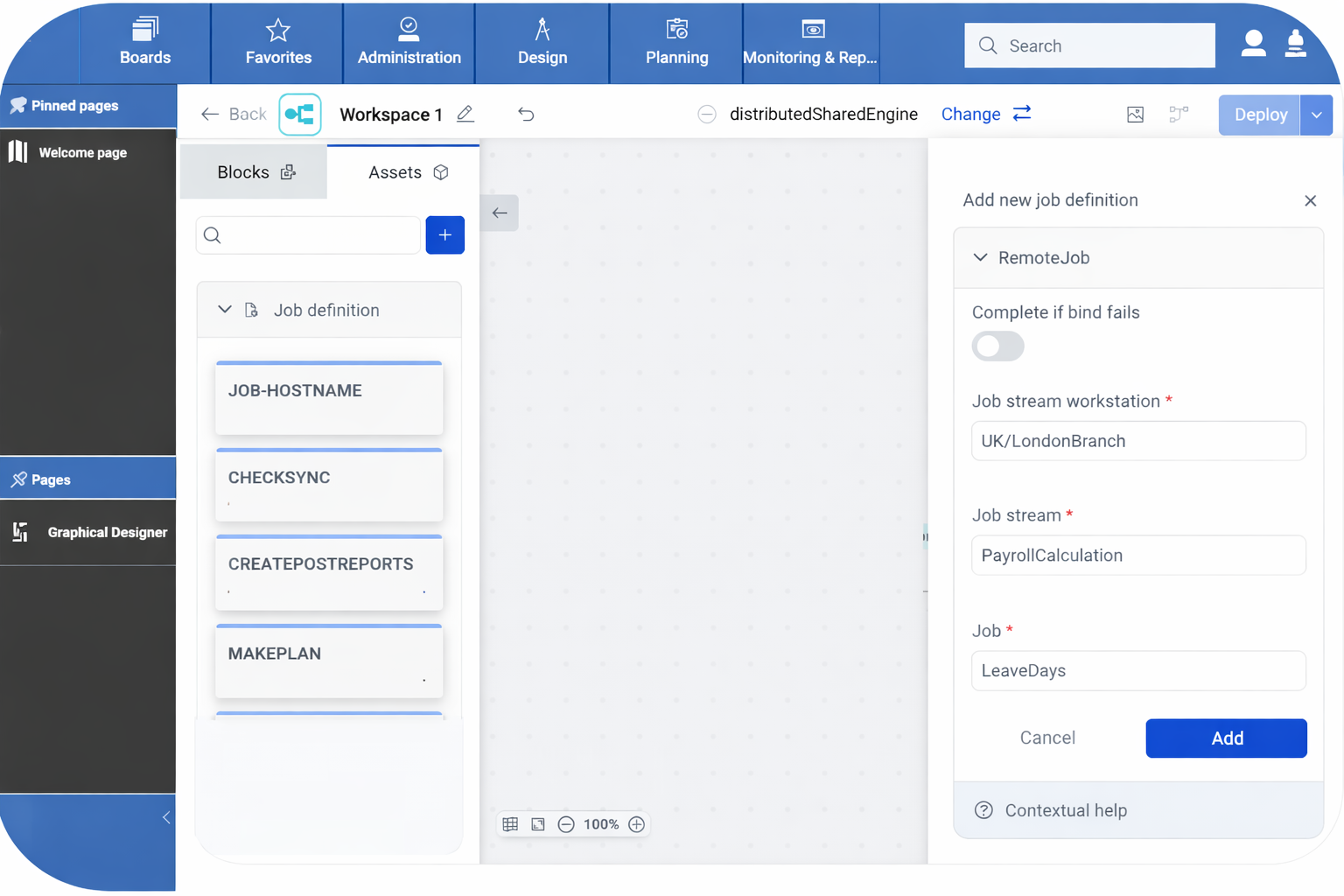
Enhanced shadow job integration
Shadow jobs facilitate the integration and synchronization of workloads across different engines.
A shadow job is defined on a local workstation to map a job running on different engines which can be distributed or z/OS engines. This mapping provides several benefits for managing hybrid workload automation environments:
- Workload integration
- Connects distributed and z/OS engines, ensuring they function as a single, coordinated system.
- Automated dependency management
- Ensures local jobs do not start until the corresponding remote job completes successfully, reducing the risk of data inconsistency.
- Enhanced monitoring
- Provides real-time status updates of remote jobs within the local plan, eliminating the need to switch between different console connections.
- Customizable matching
- Enables the selection of specific remote job instances based on scheduling dates or time intervals, ensuring precise dependency tracking.
In addition to these advantages, folder support is now available. You can use folders to
organize objects by department, line of business, or environment (for example,
/PROD/Finance/Payroll). Shadow jobs now support mapping to remote
jobs stored within these folder structures. Folder management ensures a number of
advantages:
 |
|
|
 |
 |
|
For a full description of the key features and major use cases, see Shadow jobs.