Creating a NiFi service connector
Connectors are sets of data pipes with built-in processing, which together form a pipeline. To create a new connector, define a descriptor to describe the schema, the pipeline the connector will use, and the schedule (interval, recurrence) that it follows.
Before you begin
 Important: When the Ingest service starts it attempts to
verify the required connector settings in both Zookeeper and NiFi. If no prior
connector configuration is detected, the Ingest service will create all the
mandatory HCL Commerce Search connectors automatically. This one-time procedure may
take up to 20 minutes to complete depending on the computing power of your system.
Important: When the Ingest service starts it attempts to
verify the required connector settings in both Zookeeper and NiFi. If no prior
connector configuration is detected, the Ingest service will create all the
mandatory HCL Commerce Search connectors automatically. This one-time procedure may
take up to 20 minutes to complete depending on the computing power of your system.
Note that external mounts with standalone docker contains, or persistent volumes in Kubernetes, are highly recommended for this process. You can refer to the sample docker-compose or helm charts for details.
The reason for this verification check is that data inside the application containers could be lost once the container is deleted. The advantage is that having the application configuration and internal metadata stored in an external storage allows the application to resume immedately to the most recent state and can continue to functional even after the container has been redeployed.
About this task
In this topic you will learn how to build a NiFi connector for use with the Ingest
service. You create the connector by defining a descriptor and making a request to
the Ingest service at POST: /connectors.
Procedure
-
Build your NiFi pipes. Each pipe is a NiFi process group. You can extend the
existing default pipes by creating new connectors and storing your pipes in the
NiFi registry. By using the registry, you can take advantage of its ability to
service pipes separately and at different version numbers.
The pre-built pipelines provided in Version 9.1 are Store, Catalog, Attribute, Category, Product, SEO, Price, Inventory, Entitlement, and Merchandising.
- Store
- Name, description, store level defaults, supported languages and currencies
- Catalog
- Name, description, catalog filters
- Attribute
- Name, description, attribute values, and facet properties
- Category
- Name, short description, sales catalog hierarchy and navigation properties, facets, seo url
- Product
- Name, short description, brand, price lists, inventory counts, natural language, sales catalog hierarchy and navigation properties, seo url, spell correction, suggestion, entitlement, merchandising associations, attachments
- URL
- Search engine optimization properties and URL resolution for products and categories
- Description
- Long description for product and category.
-
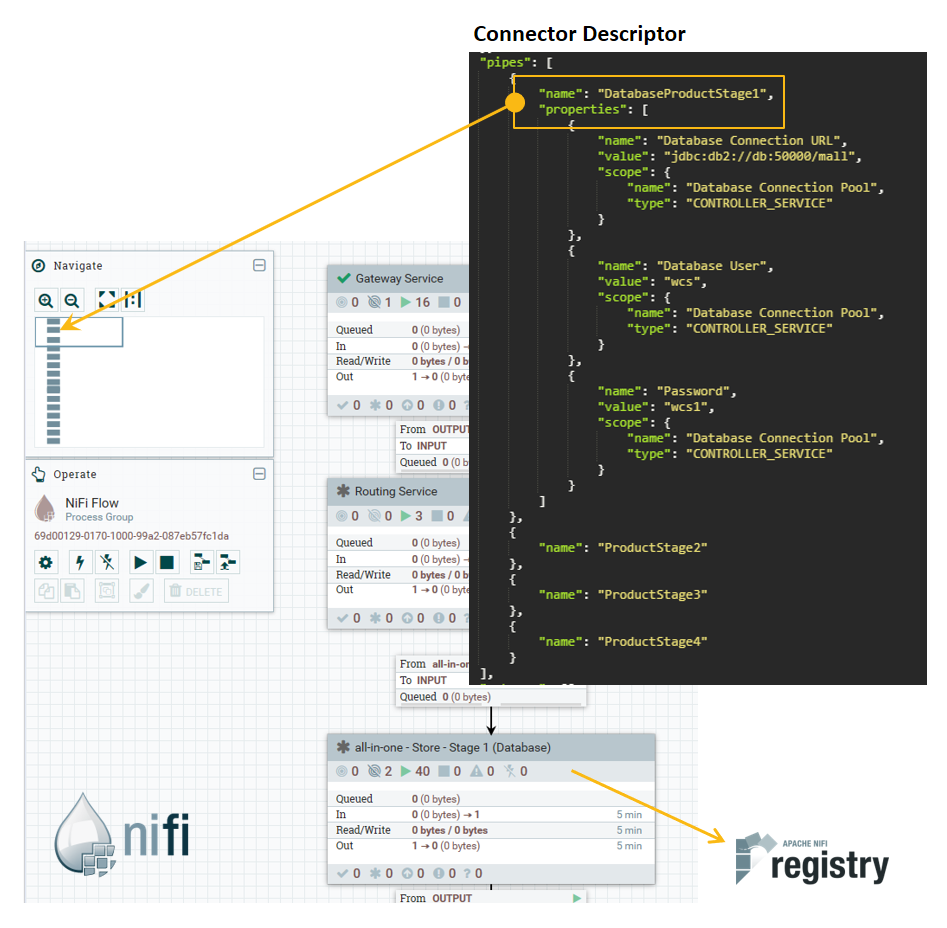
Define your connector. A connector is a set of pipes or pipelines, bundled as a
single processing unit. The standard tool for constructing connectors is the
Apache NiFi interface. You can use the
NiFi console to describe the relationships between pipelines that process
incoming data. Multiple processing pipelines can be linked to one another to
form a pipeline series inside of a connector, including a custom pipeline
created by customers. The output is a Connector Descriptor, which you store in
ZooKeeper. The console is located at
http://nifi_hostname:30600/nifi.
You can set connectors to run once, or on a recurring schedule.
-
Design your connector by defining the needed attributes in a descriptor. The
descriptor serves as a blueprint for a connector and has the following required
attributes:
- Name
- Each descriptor (and by extension a connector) must have a unique name. If a connector with the given name already exists, a new connector will not be created and a 400: Bad Request will be returned.
- Description
- A description of what this connector does. It is recommended to give a connector a description so that it is easy to recall the purpose of a connector.
- Pipes
- The list of pipes that make up a connector. Each pipe in a connector is responsible for doing some sort of ETL operation(s). Each pipe must have a name, which corresponds to a pipe that exists in the NiFi Registry. For more information, see the Apache NiFi Registry documentation.
-
Create connectors in the Ingest service.
Note: If you encounter a "No processor defined" error after you have created the connectors, restart them. In the NiFi Operate panel, click on Stop button, then the Start button, to restart all connectors.The NiFi interface is at the following address:
http://nifi_hostname:30600/nifi/A set of built-in connectors is provided for you to use. Prior to Version 9.1.12, one version of these connectors is available. From 9.1.12 on, there are two versions of each, one for use with the eSite indexing model, and the other with the Catalog Asset Store (CAS) indexing model. For more information about the differences between these two indexing approaches, see Choosing your index model.auth.validate(eSite) orauth.validate.cas(CAS model)- This pipeline is used to check the health of the index by comparing and counting elasticsearch documents against the database. Currently it checks the integrity of store, category, product, attribute and URL index.
auth.content/ live.content(eSite) orauth.content.cas/ live.content.cas(CAS model)-
Creates static pages inside the URL index. Each page layout is constructed using the selection of widgets from the Commerce Composer widget library.
auth.delete/ live.delete(eSite) orauth.delete.cas/ live.delete.cas(CAS model)- When a delete event for a category, product, or attribute occurs, this pipe is called. This pipe deletes products or category and sends an update event to the parent or child of those products or categories.
push-to-live(eSite) orpush-to-live.cas(CAS model)- This pipeline is called when the user is all set to send all index data to the live environment. It is used a locking mechanism to write data into the live environment. When write access is granted in a live environment, authentication is disabled.
Results
You now have a data definition, a pipe or set of pipes, and their relationship as described in a data descriptor. You are ready to use the connector with the Ingest service.