
Customizing SQL for the Ingest system's Extract, Transform, and Load (ETL)
You can use the Java ETL when integrating and extending NiFi and Elasticsearch. ETL processes take place in the side flow of data input. In the side flow, extraction is managed by SQL queries, which you can customize.
The ETL extracts data from HCL Commerce sources, transforms it as required, and then loads it into an Elasticsearch index. This is done using a Java processor, which you can customize as described in Customizing default ETL logic.
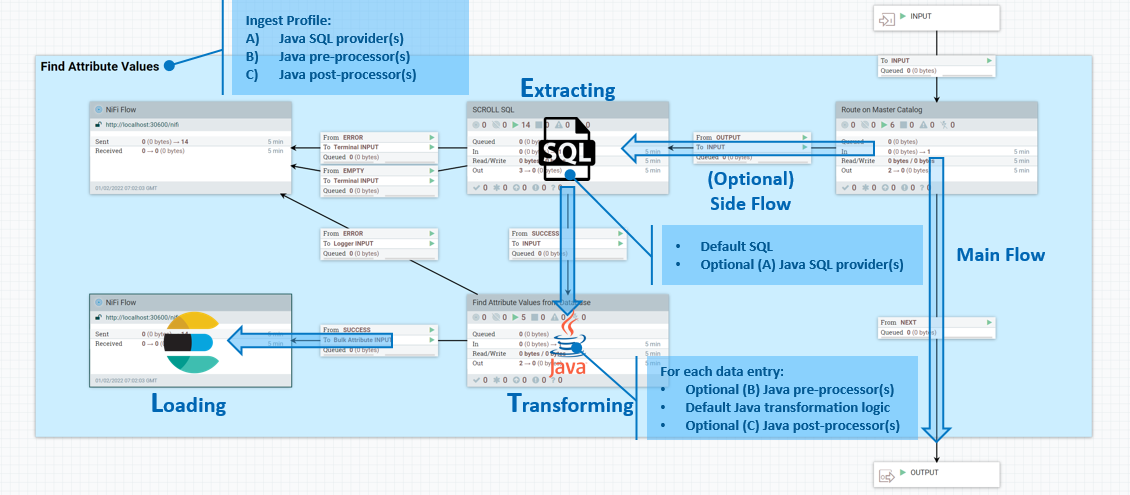
The Java ETL process group includes components such as an SQL process group for data extraction, a custom connector pipe for data transformation, a NiFi flow remote group for routing documents, and a Mster Catalog process group for data flow management. This configuration is particularly useful for tasks such as full re-indexing, near real-time updates, and data loading. Data is extracted using SQL queries in the following sequence:
- ETL begins by extracting data from the HCL Commerce database. SQL queries are used to select and retrieve the required data.
- Within the NiFi dataflow, there's an "Execute SQL" process group dedicated to running these SQL queries. This group contains all the SQL commands necessary for data extraction.The Execute SQL process group interacts with the database, executes the SQL queries, and retrieves the results.
- The data fetched by these queries is then passed on to the next stages of the
ETL pipeline.
- In scenarios where large datasets are involved, a SCROLL SQL process group is used. This group is equipped to handle database paging, which is essential for efficiently processing large results sets without overwhelming system resources.Database paging involves retrieving data in manageable chunks (or "pages") rather than attempting to load the entire dataset at once. This approach is more scalable and is crucial for large-scale data operations.
- The extracted data, once retrieved via the SQL process groups, is then fed into the transformation stage of the ETL pipeline. In this stage, custom Java processors transform the data as required for the Elasticsearch index.
Customizing ETL SQL
Typically you use custom SQL with custom NiFi connectors. To learn how to create a new connector, see Creating a NiFi service connector. Once you have a new connector, you can extend its SQL by adding your custom code to the Define custom SQL and index name processor.
- Go to the new custom pipeline and double-click custom -_Template -DatabaseETL.
- Navigate to .
- Inside the Execute SQL process group, find the process Define custom SQL.
- Right-click on Define custom SQL and stop the processor.
- Double-click the processor to modify the settings.
- Update the property Custom SQL with your custom SQL.
- Change the value of the property Use Custom SQL from
NotoYes. - Click Apply.
- Start the processor by right-clicking it and selecting Start from the context menu.
Prior to HCL Commerce Search Version 9.1.15, the SQL was kept in the same template schema in the NiFi registry as other customization code. To make it easier for you to customize the SQL by itself, this SQL has been moved out to separate files in a src/main/resources/sql directory under the version-specific NAR and JAR. For example, you could find DatabaseProductStage.sql under commerce-search-processors-nar-9.1.15.0.nar/bundled-dependencies/commerce-search-processors-9.1.15.0.jar/src/main/resources/sql if commerce-search-processors-nar-9.1.15.0.nar was your current version-specific JAR.
In HCL Commerce Search 9.1.15 and subsequent versions, you can also override the SQL with a custom file instead of updating the NiFi Flow configuration directly. This can separate out your customization from the default configuration and therefore makes future upgrades easier.
The SQL in these SQL files can be checked by looking at the comment section of the GenerateSQL processor running that SQL.