Always On 可用性グループの管理
Windows 2008 R2 以降のクラスターを管理するためのコンテンツ (自動化計画、タスク、スクリプト) を使用して、モニターとプロセスの改善を強化することで、Always On 可用性グループ (AAG) を使用して Windows 2012 以降のクラスターを管理できます。適切なノードにパッチを適用してパフォーマンスを向上させるには、このセクションで定義されているモニター・タスクを自動化計画に含めます。
モニタリングとパッチ適用プロセス
コンソール・オペレーターは、Always On 可用性グループ (AAG) を使用した Windows 2012 以降のクラスターへのパッチ適用を 2 つのフェーズで計画できます。最初のフェーズでは、特定の メンテナンス期間の前に、環境内のノードをモニターし、2 次ノードに手動でパッチを適用できます。2 番目のフェーズでは、メンテナンス期間内に、1 次ノードとスタンドアロン・ノードをターゲットにすることができます。これにより、メンテナンス期間中にアクティブ・ノードのみにパッチが適用されるため、スケジュールされた制限時間内に適切にパッチ適用を完了できます。
Status Collector
Status Collector は、クラスター・ノードに関する重要な情報を収集する Windows のスケジュールされたタスクとして実装されるサービスです。このタスクは、ノードの状況をチェックして、フェイルオーバー・クラスターの正常性をモニターします。これにより、どれが 1 次ノードでどれが 2 次ノードかを識別します。
前提条件
Status Collector をインストールするための前提条件を以下に示します。
- オペレーティング・システム: クラスター・ノードには Windows® 2012 以降が必要であり、AAG を使用して構成されている必要があります。
- データベース: ノード上のデータベースは、MS SQL Enterprise Edition のみである必要があります。Always On 可用性グループの前提条件、制約事項、および推奨事項の詳細については、https://docs.microsoft.com/en-us/sql/database-engine/availability-groups/windows/prereqs-restrictions-recommendations-always-on-availability?view=sql-server-ver16 を参照してください。
Status Collector のタスク
Status Collector はクラスター・ノードで実行されます。スケジュールされたタスクは、PowerShell スクリプトを定期的に実行してノードを照会し、Analysis 176 - Status of the Always-On failover cluster を通じて必要な情報を報告します。Status Collector のインストール、編集、アンインストールに使用できるタスクを以下に示します。
- タスク 173 - Windows クラスターの Status Collector をデプロイする
- このタスクを実行して、Status Collector をインストールします。このタスクは、Windows タスク・スケジューラー・サービスが有効で、 「自動」に設定されているかどうかを確認します。有効な場合は、提供された PowerShell スクリプトを呼び出す新しいタスクが作成され、トリガーはコンソール・ユーザーが選択した頻度を反映したスケジュールになります。PowerShell スクリプトはノード状況を収集し、この情報を実行タイム・スタンプとともにファイルに書き込み、固定の場所に保存します (出力ファイルの場所は <BES クライアント・フォルダー>\Applications\StatusCollector フォルダーになります)。重要:Status Collector のインストール中に、以下の設定を構成できます。
- このタスクは、SQL Server サービスと Windows クラスター・サービスがインストールされているコンピューターにのみ適用されます。インストール・タスクの適用条件は、Windows タスク・スケジューラーで Status Collector が既にスケジュールされているかどうかをチェックします。
-
これは、AAG をサポートするための特定のスケジュールされたタスクです。このタスクが AAG 以外の別のタイプの Windows クラスターでデプロイされている場合、情報は報告されません。
- スケジュールされたタスクが構成されている限り、タスクの実行に使用されるユーザー・アカウントは、デフォルトで SYSTEM として設定されます。インストール後に別のユーザー・アカウントで実行する場合は、そのユーザー・アカウントに PowerShell スクリプトを実行するのに必要な権限があることを確認してください。ユーザー・アカウントを構成するには、Windows のスケジュールされたタスクを開き、 「一般」→「セキュリティー・オプション」で、必要な値に変更します。
- タスク 174 - Windows クラスターの Status Collector を編集する
- このタスクを使用すると、
Task 173 - Deploy status collectorで Status Collector のインストール中に構成した設定 (スクリプト実行のポーリング時間、DB インスタンス名、ログ・フォルダーのしきい値) を変更できます。このタスクは、Status Collector をアンインストールまたは再デプロイすることなく、すぐに再構成します。
- タスク 175 - Windows クラスターの Status Collector を削除する
- このタスクは、以前にインストールされた Status Collector をアンインストールします。アンインストールすると、Status Collector を使用してモニターできなくなります。
状況をモニターするための分析
Analysis 176 - Status of the Always-On failover clusterを使用してクラスター内のノードの状況をモニターできます。この分析により、ユーザーは 1 次ノード、2 次ノード、スタンドアロン・ノードなどのノードの役割をモニターおよび構成できます。アクティブ・ノードから最後に報告されたタイム・スタンプが報告されます。これに基づいて、コンソール・オペレーターは、メンテナンス期間中および期間外にパッチを適用するノードを決定し、高可用性を確保できます。この分析では、以下の情報が表示されます。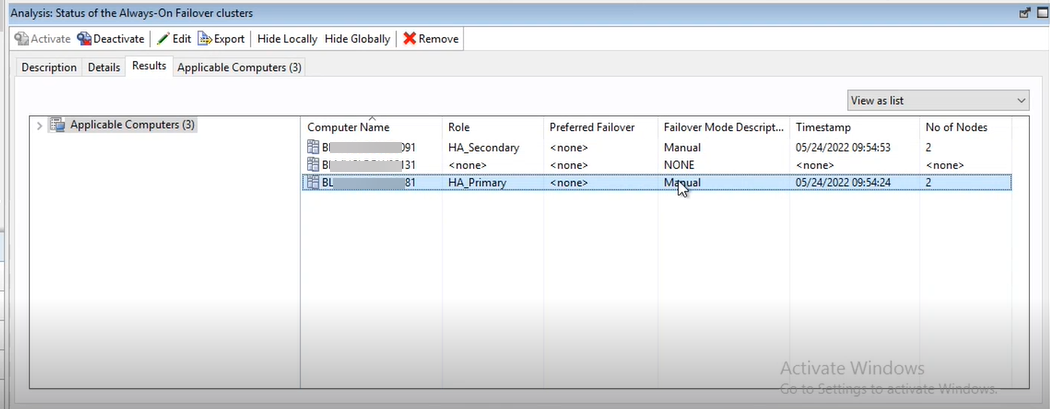
- コンピューター名
- クラスター内のノードのコンピューター名。
- 役割:
- ユーザーが構成するノードの役割 (HA_Primary、HA_Secondary、Standalone など)。
- フェイルオーバー・モードの説明
-
- 手動 - HA_Primary ノードがダウンしても、2 次ノードに自動的に切り替わりません。ユーザーは、別のノードを HA_Primary として手動で選択する必要があります。
- 自動 - HA_Primary ノードがダウンすると、「優先フェイルオーバー」 列で設定された 2 次ノードに自動的に切り替わります。
- なし - ノードが AAG クラスターで構成されていない場合は、<None> と表示されます。
- 優先フェイルオーバー
-
自動フェイルオーバー・モードを選択した場合、HA_Primary ノードがダウンすると、 「優先フェイルオーバー」に記載されているサーバー名が HA_Primary ノードになります。重要: 1 次ノードに障害が発生した場合にすぐに対応できるように、優先フェイルオーバーに記載されているサーバーに、メンテナンス期間外に適切にパッチが適用されていることを確認してください。
- Timestamp (タイム・スタンプ)
-
タイム・スタンプには、分析で表示するためにノードからデータを収集した日時が表示されます。これは、サーバーが最後に照会に応答した時刻を示します。このタイム・スタンプに基づいて、コンソール・オペレーターは、サーバー状況が変化したかどうかを判断できます。これにより、メンテナンス期間中または期間外にパッチを適用するサーバーを決定するのに役立ちます。
- クラスター内のノード数
-
ノードが属するクラスターで構成されているノードの数が表示されます。
タスク 344 - 安全性チェックを行ってクラスター内のリソースの実行可能な所有者としてノードを使用不可にする
このタスクは、fixlet responsible for marking Cluster nodes unavailableの更新バージョン (現在使用可能なバージョンを除く) です。
このタスクは、3 つ以上のノードを持つクラスターでのみ使用できます。クラスターのフェイルオーバーに使用できないノードをマークする前に、追加の安全性チェックを実行します。安全性チェックに失敗した場合は、さらに 2 回再試行します (合計 3 回)。
このタスクは、任意の時点で、要求に応答できるノードの数が半分を超えることを保証します。実際のパッチ適用は、使用可能なノードの数がクラスター内のノード数の半分を超える場合にのみ続行できます。これにより、フェイルオーバー・プロセスが可能になり、データ損失を防ぎます。例えば、クラスター内に 3 つのノードがある場合、パッチ適用を除外できるノードの最大数は 1 です。使用可能なノードの数は 2 (3/2=1.5) です。これにより、データ損失を防ぎます。
3 ノード・クラスターでは、スタンドアロンはアクティブ・クラスターのレプリカです。1 次とスタンドアロンはアクティブであると見なされ、両方ともメンテナンス期間中にパッチが適用されます。前述のアルゴリズムは 2 ノード・クラスターには適用されないため (フェイルオーバーに使用できるノードが半分を超えることはないため)、fixlet responsible for marking Cluster nodes unavailableを使用する必要があります。
ログとトラブルシューティング
- Status Collector に関するエラーおよびデバッグ情報は、 BES CLient/Applications/StatusCollector/Logs フォルダーで使用可能になります。
- 1 つ以上のログ・ファイルがStatusCollector.<date>.log という名前形式で保存されます。各ログ・ファイル名には、対応する日付が含まれています。
- ログ・ファイルには、クラスター・ノードへの照会に関連するすべてのメッセージが含まれます。
- インストールまたは編集タスクによってログを累積するように構成されたディスク・スペースに応じて、最新のログが保持され、最も古いログが自動的に削除されます。
- Status Collector をトラブルシューティングする場合、特定のノードに対して構成された更新期間を過ぎても更新されない分析のタイム・スタンプを開始点にします。これは、タスク・スケジューラー・サービスが正しく実行されていない (この場合、「Fixlet の編集」を使用して自動的に開始するように再構成できます) か、その他の理由が原因で発生する可能性があります。「Fixlet の編集」で問題が解決しない場合は、更新されていないノードの Status Collector ログ・ファイルを手動でチェックして、問題をトラブルシューティングする必要があります。