Tuning Index Load
You can tune Index Load for optimal performance by configuring the tunable values and evaluating the results.
About this task
Index Load starts with a single input source, uses multithreaded processing, and ends with a single batch service writing to a single index.
The following diagram shows the
available tunable areas of Index Load:
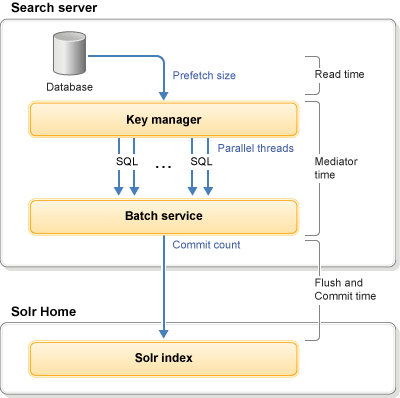
Where the following main tunable areas exist:
- Parallel threads
- The number of threads to be used for parallel indexing.
- Prefetch size
- The number of rows to return for each database (SQL) call.
- Commit count (hard commit)
- The number of index documents to keep in memory before writing to the Solr index.
- Batch count (soft commit)
- The number of index documents to keep in the Index Load runtime buffer before pushing them into
the Solr memory stack.
The higher the batch count value, the higher the indexing throughput but with more garbage generated.
The following gauges of measurement exist to determine performance, can be viewed from
the Index Load status page:
- Rate
- The average number of documents indexed per second to the Solr stack.
- Read time
- The average amount of time spent running SQL calls.
- Flush time
- The average amount of time spent on Solr soft commits.
- Commit time
- The average amount of time spent on Solr hard commits.
- Indexing time
- The overall end-to-end time spent on indexing.
You can use these statistics to tune the main tunable areas of Index Load.
The
following diagram shows how Index Load works with chunks of data, and how you can tune the prefetch,
threads, and batch count for performance:
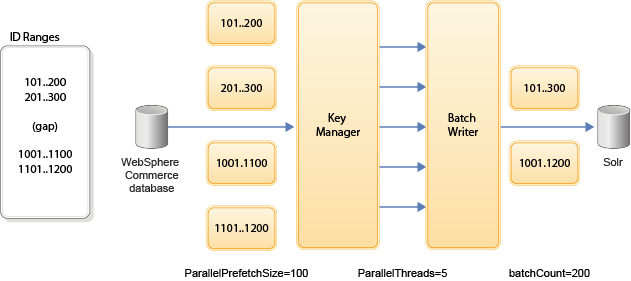
Where:
Where:
- The Key Manager uses Prefetch to get small chunks of data from the database and evenly distributes it across all worker threads. This technique avoids overloading the database when processing a very large of result set size. Very large result set sizes might not even fit into the database transaction log. By using smaller chunks of data, the query time is improved, and the Index Load thread workload is more evenly distributed.
- The prefetch size (ParallelPrefetchSize) defines the lookahead block size, whereas the next range SQL (ParallelNextRangeSQL) is used to address large empty ID range gaps. The next range SQL is only used when the lookahead contains no data. That is, when a gap is detected. This SQL is used to return the next available ID, and therefore avoids unnecessary crawling.
- The prefetch size, thread count, ranges, and batch count are all factors to consider when tuning Index Load.
Procedure
-
Use the following overall tuning technique to achieve optimal performance of Index Load:
- Start with a fixed time window or small data set to tune before scaling up. This helps calibrate the tasks with your hardware.
- Determine the optimal prefetch size, when the read time is slightly higher than 0, and ideally when the total elapsed read time is less than 1 minute. The prefetch size is used to control read time.
- Reach the best throughput, when flush and commit times are close to 0. That is, when the overall Solr index overhead is 0. The batch count is used to control the flush time (soft commit). The commit count is used to control the commit time.
- When the optimal settings are found, reduce the number of threads until throughput rate drops. This technique helps find the maximum power to set to each pipeline.
-
Use the following general settings to help maximize the indexing rate:
- Use a 64 bit JVM and assign as much heap to it as possible to reduce overall garbage collection.
- Use a hardcoded key range, so that Index Load does not waste time scanning empty ranges.
- Use a ThreadLaunchTimeDelay to avoid processing all indexing threads in parallel at startup and overloading database resources.
-
Tune the following values to determine how Index Load works with chunks of data:
- Tune the prefetch size to control how many rows are read from the data source at a time. This must be tuned to balance database load against data availability for worker threads.
- Tune the thread count to control how many parallel threads are processing these rows. This must be tuned to balance overall CPU load with ability to process data in parallel.
- Tune the ParallelNextRangeSQL to avoid gaps in input ID ranges. Each range is fetched and distributed across the worker threads.
- Tune the batch count to control the sizes of the batches that are sent to Solr.
-
Tune the configurable performance attributes in the
wc-indexload-profileName.xml and
wc-indexload-businessobject.xml Index Load configuration
files.
For more information, see Index Load configuration files for indexing from database.
-
Select one of the following tuning methods that affect the overall indexing rate, and adjust
the tuning parameters accordingly.
Note: Combining multiple tuning methods might result in unpredictable results and negatively impact the overall indexing rate.
Option Description Recommended: Memory allocation-based configuration Set the following values in the solrconfig.xml file: Lucene ramBufferSizeMBbatchSizedisable commitCount
Document count-based Index Load configuration Set the following values when configuring Index Load: batchSizecommitCount
Document count-based Solr configuration Set the following values in the solrconfig.xml file: maxDocs of Solr autoCommitbatchSize- disable
commitCount
Document count-based Lucene configuration Set the following values in the solrconfig.xml file: Lucene maxBufferedDocsbatchSize- disable
commitCount
Where:- Lucene ramBufferSizeMB
- Defines the amount of memory space, in MB, to be used for buffering indexed documents. Once the accumulated document updates exceed the allocated memory space, a disk flush occurs, which can also create new segments, or trigger an index segment merge.
- Lucene maxBufferedDocs
- Defines the number of document updates to buffer in memory before they are flushed as a new segment. Once the accumulated document updates exceed this value, a disk flush occurs, which can also create new segments or trigger an index segment merge.
- maxDocs of Solr autoCommit
- A Solr-level parameter that defines the maximum number of indexed documents to be buffered in memory before a disk flush occurs. Compared to the Lucene level maxBufferedDocs, this setting does not guarantee a low-level disk flush. When the Lucene maxBufferedDocs value is greater than this autoCommit size, this setting is irrelevant.
- Index Load commitCount
- Defines the maximum number of uncommitted documents to be buffered in memory before a disk flush occurs. This is an application-level control and flushes to physical storage using the Solr hard commit API. Set the value to 0 to disable it.
- Index Load batchSize
- Defines the number of documents to be kept in memory before soft committing to Solr. This action does not guarantee a disk flush, as the final decision also depends on the values of maxDocs, and the Lucene ramBufferSizeMB and maxBufferedDocs values, if any of them are configured. Set the value to 0 to disable it.
Note: The commit count value supersedes the batch size value when the batch size is larger than the commit count. -
Monitor Index Load and use the metrics while indexing to help refine tuning parameters and
improve performance throughput.
For more information, see Monitoring Index Load.