Optimizing index build and overall flow
Optmizations are provided full index builds and for tuning parameters. Potential improvements that can be implimented for Near Real Time (NRT) index updates are not described.
The index building process
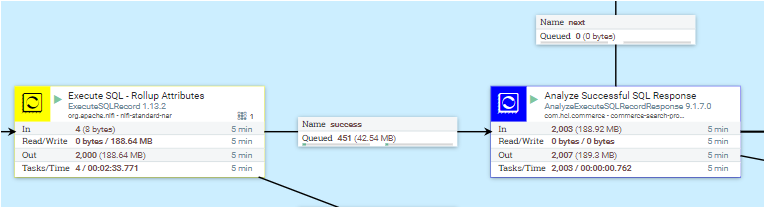
A full index build consists of three major steps: retrieving data, processing data, and uploading data. There are several predefined connectors, which consist of several process groups for different purposes. Usually, each process group will contain process subgroups to handle the data retrieval, processing, and uploading stages that are associated with the build process.
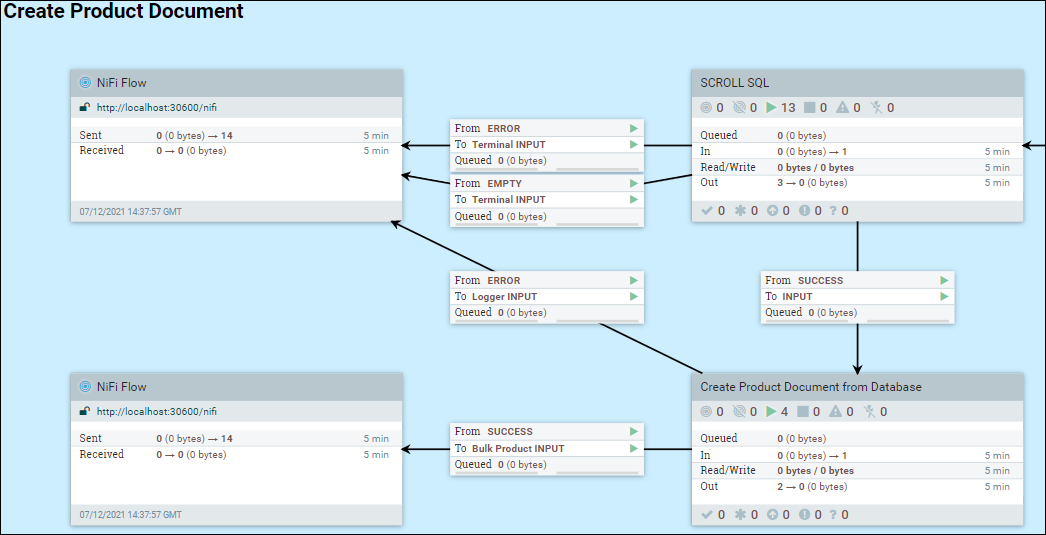
- Retrieving data group: Fetch data from database or Elasticsearch.
- Processing data group: Based on the fetched data, build, update, and/or copy the index documents.
- Uploading data group: Upload the index document to Elasticsearch. From the HCL Commerce 9.1.3.0 release, each index has one associated group.
Tuning
Generally, default settings will work for this process, but it may take a long time to finish the indexing process for a large data set. Depending on the data set size and hardware configuration (memory, CPU, disk, and network), improvements to the subgroups and process groups can be made so process flows are faster and more efficient within subgroups, and between connected subgroups.
Retrieving data group
In this group, there are three different sources that the data can be retrieved from.
- Fetched from a database with SQL scroll;
- Fetched from a database with SQL without scroll;
- Fetched from Elasticsearch with scroll
- Fetch data from a database with SQL scroll
-
 Enter the SCROLL SQL group, then right click on the base canvas and select variables.
Enter the SCROLL SQL group, then right click on the base canvas and select variables.- The scroll.page.size is the number of rows fetched from database by the SQL.
- The scroll.bucket.size is the number of rows from the fetched data in each bucket for processing. The bucket.size will determine the size of the flow files (and the number of documents contained within each file).
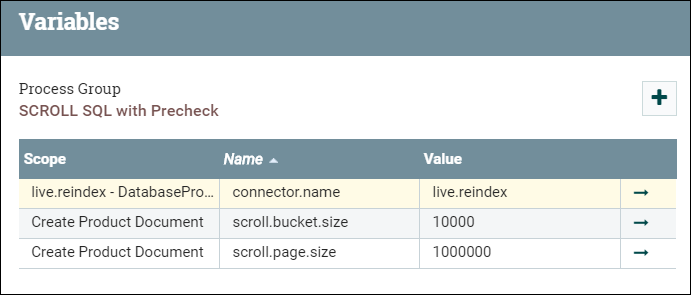
Change the values of scroll.bucket.size and scroll.page.size based on the following considerations:
- • Depending on the catalog size, the SQL can take a long time to get response data back to the NiFi. The purpose of the scroll SQL is to limit the data size that can be processed in NiFi at once, to avoid memory errors on large catalogs.
- • The scroll settings are optimal when the time that it takes to process the data is evenly matched with the amount of time that the next SQL scroll takes to receive its data. With this optimization, unnecessary processing or I/O delay is minimized.
- • The output from one subgroup is handed in turn to the next connected process subgroup. This process must be audited, to ensure that there are no bottlenecks which can impact the efficiency of the overall process.
- Fetch data from database with SQL without scroll
-
In the process group, the data set is fetched from the database by using a single SQL stream. For example, the Find Associations at DatabaseProductStage1b.
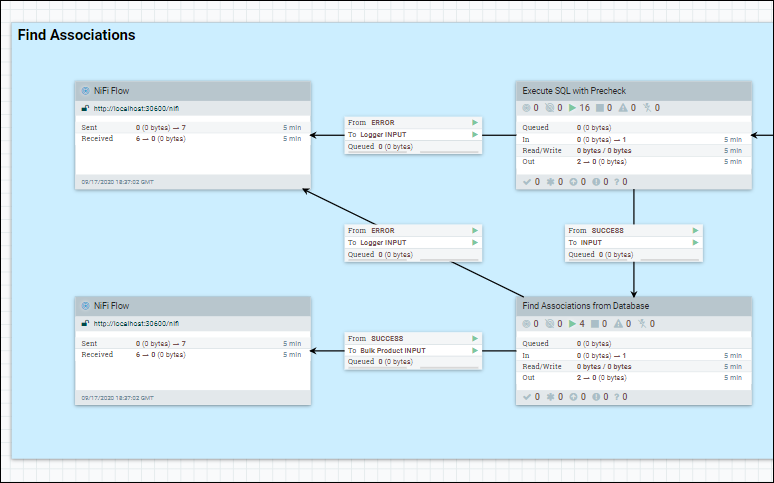
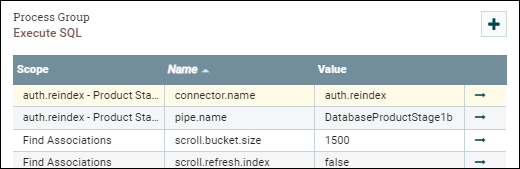
Enter the Processor group that we are optimizing, right click on the base canvas, and select variables.
Set the scroll.bucket.size parameter to the number that you want.
The scroll.bucket.size is the number of rows from the fetched data that is placed in each bucket for processing. The bucket.size will determine the size of the flow files (and the number of documents contained within each file).
- Fetch data from Elasticsearch
-
Since the index build is a staged process, some information may be added to existed index documents. In the case, NiFi needs to fetch data from Elasticsearch. Let us use the URL Stage 2 as the example.
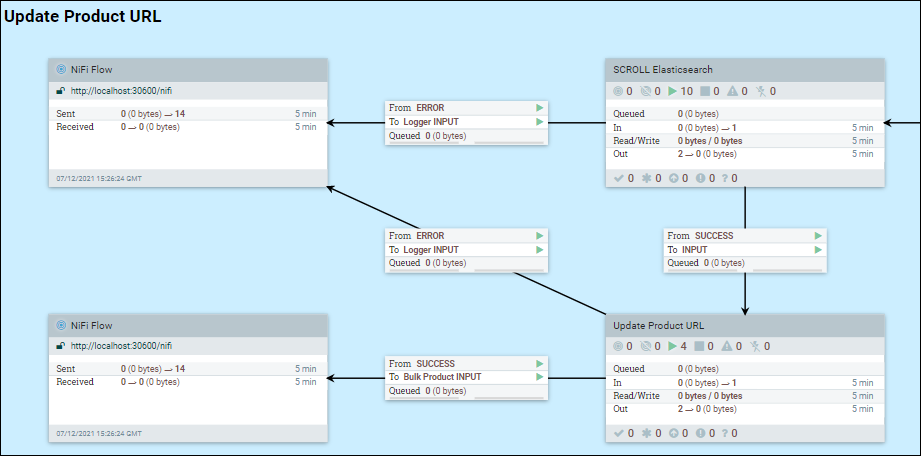
Enter the SCROLL Elasticsearch group, right click on the base canvas, and select variables.
Change scroll.bucket.size and scroll.page.size to values that you want, based on the following considerations:
The scroll.page.size is the number of documents that are fetched from Elasticsearch. If the number is too small, NiFi must make more connections to Elasticsearch.
The scroll.bucket.size is the number of documents from the fetched data in each bucket for processing. The bucket.size will determine the size of the flow files (and the number of documents contained within each file).
Another parameter that is useful for tuning is scroll.duration. This value defines the amount of time that Elasticsearch will store the query result set in memory. This parameter is useful when dealing with many stores and languages running in parallel, where a running out of scroll error can be encountered. This error indicates that you are running out of scroll space, and reducing the scroll duration will force Elasticsearch to free older or obsolete buffers faster. Inversely, increasing the scroll duration in Elasticsearch for that index will provide extra time to complete processing operations.
- Processing data group
-
In the following example, the process group DatabaseProductStage 1a is used.
Enter the Create Product Document from Database, right click Create Product Document from Database and select configure. Under the SCHEDULING tab, update the Concurrent Tasks value to set the number of threads that will be used for the process group. When increasing the number of concurrent tasks, the memory usage for the process group is also increased accordingly. Therefore, setting this value to a number that is greater than the number of CPUs that are allocated to the pod, or beyond the amount of memory that is allocated to the pod may not make sense, and can have a negative impact on performance.
- Uploading documents group
-
Enter the Bulk Elasticsearch group. There are are several processes displayed. Right click on each process, and select configure. Under the SCHEDULING tab, update the Concurrent Tasks values to one that makes sense for your environment.
The Post Bulk Elasticsearch processor sends the created index documents to Elasticsearch. By default, Elasticsearch will use the same number of CPUs as the number of the connections. Considering the possible delay or pools, the number that is set for the Post Bulk Elasticsearch processor may be larger than number of CPUs that are allocated to the Elasticesearch pod.
It is a good rule of thumb to consider all processes in a group together. In general, it is best to try and make later processes complete faster than earlier ones. Otherwise, queued objects will consume extra memory and slow down overall processing efficiency.
Overall considerations for tuning
- Concurrent tasks/threads
- Increasing the number of threads that are processed can help to improve a processing group throughput, however this needs to be assessed carefully.
- Bucket size/Flow file size
- Increasing the bucket size increases the flow file size, i.e., the
number of documents that are processed as a group in NiFi. The bigger
the flow file, the better the efficiency. However, limited operating
system resources will limit the maximum size of the flow file.
- Flow file size tuning is very visible and impactful on the system.
- Large flow files have several negative side effects:
- They demand a large memory heap for NiFi.
- They require a matched funnel on Elasticsearch, to accept the data as it comes over.
- NiFi GC overhead may become prohibitively high, or NiFi can run
out of heap space with an
Out of Memoryerror.
- Back pressure in links between processes, process groups, and process subgroups
- In the pipeline, there are many links between steps. Each link has its own queue for the resulting objects (queued items) for processing in the next step.
-
-