Zones Solr personnalisées
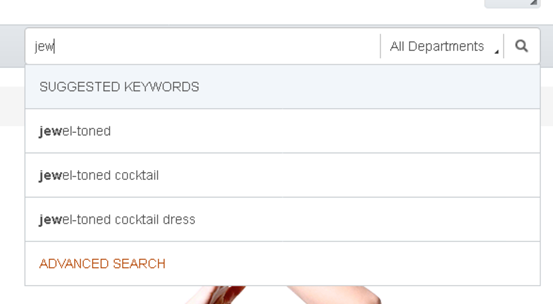
Dans cette leçon, vous ajoutez votre propre type de zone Solr au fichier de configuration x-schema-field-types.xml. La nouvelle zone supprimera les concaténations en pointillés des suggestions de recherche. Par exemple, au lieu de suggérer "jewel-toned" dans une recherche "jewel" il suggérera "jewel toned".
Si vous souhaitez ajouter des types de zones Solr personnalisés, vous pouvez les définir dans le fichier workspace_dir\search-config-ext\src\index\managed-solr\config\v3\common\ x-schema-field-types.xml.
Pour utiliser un type de zone personnalisé, modifiez le mappage de type de zone et de zone dans le fichier search-config-ext\src\index\managed-solr\config\v3\indextype\x-schema.xml, où indextype se trouve : CatalogEntry, CatalogGroup, Price ou Unstructured.
Après cette procédure, vous ajouterez un nouveau type de zone et utilisez ce type dans votre index catalogEntry. Vous ajouterez un filtre de délimiteur de mots dans ce nouveau type de zone.
Procédure
-
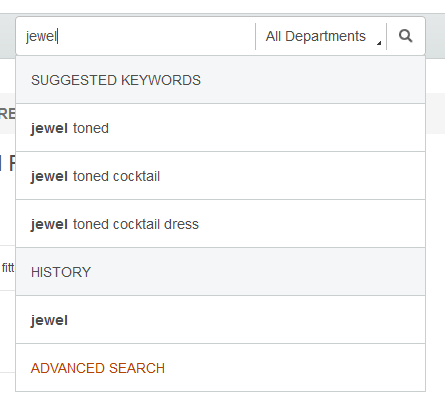
Recherchez la chaîne "jewel" dans la vitrine. Le moteur de recherche Solr proposera des noms de produits concaténés par des tirets, comme dans le résultat suivant :
- Copiez le fichier x-schema-field-types.txt de l'exemple solrconfiguration.zip dans workspace_dir\search-config-ext\src\index\managed-solr\config\v3\common\x-schema-field-type.xml.
-
Ajoutez le texte suivant au fichier x-schema-field-type.xml.
Les classes définies en gras suppriment le caractère tiret "-" des suggestions de recherche. Par exemple, au lieu de renvoyer "a-b", la sortie peut être "a b".<fieldType name="x_textSpell_en" class="solr.TextField" positionIncrementGap="100" omitNorms="true"> <analyzer type="index"> <tokenizer class="solr.WhitespaceTokenizerFactory"/> <filter class="solr.LowerCaseFilterFactory"/> <filter class="solr.StopFilterFactory" ignoreCase="true" words="${stopwords_en:../../../v3/common/stopwords.txt}"/> <filter class="solr.WordDelimiterFilterFactory" generateWordParts="1" generateNumberParts="1" catenateWords="0" catenateNumbers="0" catenateAll="0" splitOnCaseChange="1" splitOnNumerics="1" preserveOriginal="0"/> <filter class="solr.ShingleFilterFactory" outputUnigrams="true" minShingleSize="2" maxShingleSize="3" tokenSeparator=" " fillerToken="" /> <filter class="solr.PatternReplaceFilterFactory" pattern="\s{2,}" replacement=" " replace="all"/> <filter class="solr.TrimFilterFactory"/> <filter class="solr.RemoveDuplicatesTokenFilterFactory"/> </analyzer> <analyzer type="query"> <tokenizer class="solr.WhitespaceTokenizerFactory"/> <filter class="solr.LowerCaseFilterFactory"/> <filter class="solr.WordDelimiterFilterFactory" generateWordParts="1" generateNumberParts="1" catenateWords="0" catenateNumbers="0" catenateAll="0" splitOnCaseChange="1" splitOnNumerics="1" preserveOriginal="0"/> <filter class="solr.StopFilterFactory" ignoreCase="true" words="${stopwords_en:../../../v3/common/stopwords.txt}"/> </analyzer> </fieldType> -
Ouvrez le fichier workspace_dir\search-config-ext\src\index\managed-solr\config\v3\CatalogEntry\x-schema.xml. Ajoutez un attribut spellcheck à l'élément field comme suit.
Localisez l'élément field.
Modifiez-le pour lire :<field name="spellCheck" type="wc_textSpell_${lang:en}" indexed="true" stored="false" multiValued="true" />
Localisez l'élément dynamicField :<field name="spellCheck" type="x_textSpell_en" indexed="true" stored="false" multiValued="true" />
Modifiez-le pour lire :<dynamicField name="spellCheck*" type="wc_textSpell_${lang:en}" indexed="true" stored="false" multiValued="true" /><dynamicField name="spellCheck*" type="x_textSpell_en" indexed="true" stored="false" multiValued="true" /> - Redémarrez le serveur HCL Commerce Search.
-
Régénérez l'index de recherche de .
La méthode est POST, et vous devez inclure l'autorisation de base dans l'en-tête, c'est-à-dire un ID spiuser et un mot de passe correspondant. Pour plus d'informations, voir Génération de l'index HCL Commerce Search.https://transaction_server_hostname:transaction_server_https_port/wcs/resources/admin/index/dataImport/build
Résultats