Après avoir créé votre connecteur personnalisé dans le service Ingest, vous le configurez pour qu'il se connecte au serveur de base de données.
Procedure
-
Mettez à jour le SQL Ingest dans le groupe de processus
auth.xfields-_Template-DatabasePagingETL.
-
Utilisez le lien suivant pour accéder à l'interface utilisateur de NiFi :
http://hostname/IP:30600/nifi/
-
Localisez et cliquez deux fois sur le groupe de processus
auth.xfields-_Template-DatabasePagingETL.
-
Cliquez deux fois sur le groupe de processus
Custom Connector Pipe. Une fois qu'il s'ouvre, localisez et cliquez deux fois sur le groupe de processus SCROLL SQL. Localisez et cliquez avec le bouton droit de la souris sur le processeur Define Custom SQL et arrêtez-le.
-
Cliquez deux fois sur le processeur
Define Custom SQL pour modifier ses paramètres.
-
Sélectionnez l'onglet Propriétés et mettez à jour la propriété ingest.database.sql avec le code SQL personnalisé, en fonction des zones personnalisées que vous souhaitez inclure à partir d'une table de catalogue (par exemple CATGROUP.FIELD1).
Par exemple,
SELECT field1, field2,catentry_id FROM catentry ${paging.prefix} ${param.offset} ${paging.link} ${param.pageSize} ${paging.suffix}
-
Une fois la zone SQL mise à jour, cliquez sur Appliquer.
-
Cliquez avec le bouton droit de la souris et cliquez sur Démarrer.
-
Mettez à jour les propriétés du processeur
Custom Connector Pipe pour le groupe de processus Java.
-
Dans le groupe de processus
Custom Connector Pipe, cliquez deux fois sur le groupe de processus Mapper les zones d'index à partir de la base de données.
-
Localisez le groupe de processus
Transform Document - Map Index Fields From Database et arrêtez le processeur.
-
Notez les propriétés obligatoires suivantes.
- Sélectionner un identificateur
- Clé
_id utilisée pour le document de sortie qui sera envoyé ultérieurement à Elasticsearch. Cet identificateur peut être exprimé à l'aide de variables de fichier de flux et de registre, ainsi qu'à l'aide du nom de zone d'index dans la réponse de recherche entre crochets.
- Par défaut, la valeur de l'identifiant d'entrée est définie sur
[id.catentry]-[id.langue]. Remplacez cette valeur par ${param.storeId}-${param.langId}-${param.catalogId}-[id.catentry]. . Afin de traiter cet identifiant, localisez le processeur et ajoutez-y la propriété supplémentaire CATENTRY_ID = id.catentry.
- Type d'index
- Type d'index de recherche dans Elasticsearch, par exemple
Product ou Category. Cette valeur ne doit pas être modifiée pour ce tutoriel.
-
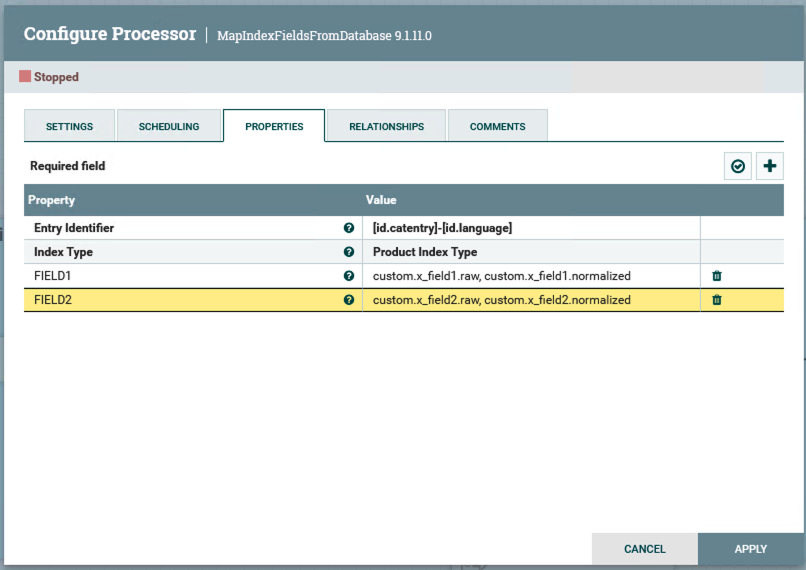
Définissez le mappage des zones de table de base de données personnalisées aux zones d'index correspondantes. Définissez le nom de la propriété sur le nom de la zone de la table de base de données et définissez la valeur de propriété sur le chemin de zone d'index de recherche correspondant. La valeur de propriété peut être une liste séparée par des virgules à valeurs multiples pour permettre le mappage de la même zone de table de base de données à plusieurs noms de zone d'index de recherche. Par exemple :
Name: FIELD1 Value: custom.x_field1.raw, custom.x_field1.normalized
Note: Réutilisez le mappage de schéma d'index existant dans la mesure du possible, pour simplifier la logique de personnalisation.
-
Cliquez sur Appliquer.
-
Démarrez le processeur en cliquant dessus avec le bouton droit de la souris et en sélectionnant Démarrer.
Results
Le nouveau connecteur est maintenant correctement configuré. Dans la leçon suivante, vous l'intégrez à un pipeline NiFi existant.