Adding a Domino IQ Configuration for Local mode
In Local mode, every Domino IQ server needs its own Configuration document that associates the Domino server name with an LLM (model) used by the AI inferencing engine running on the server. The Configuration document also specifies the port number and use of TLS (as localhost), along with several runtime and tuning parameters used for running the AI inferencing server.
Procedure
- Using the Domino Administrator client, open the Domino IQ database , dominoiq.nsf, on the Domino IQ Administration server.
- Select the Configurations view and click the Add Configuration button.
- On the Basics tab, complete the following steps:
- In the AI endpoint field, select Local.
- Select the name of a Domino IQ server from the list.
- Specify the name of the download model from the LLM Model document.
- Set the Status field to
Enabled, so that the Domino IQ task gets loaded
on the server.
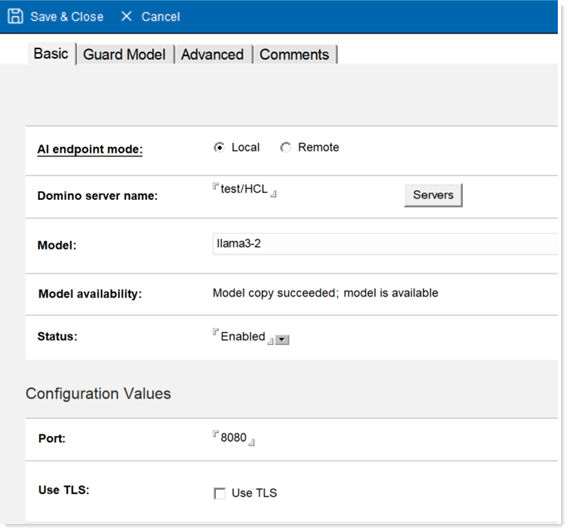
- Select the port number for the AI Inference server started as "localhost" to run on the Domino IQ server. The default port for non-TLS is 8080 and for TLS is 8443. TLS can be optionally enabled by checking the Use TLS option.
- Configure TLS Credentials using Certstore. Complete this step only if you use TLS for https communication between the Domino server process and the AI Inference server running as localhost.
- If you're using a guard model, complete the following steps to enable it. Otherwise,
skip to step 5.
- Click the Guard Model tab.
- Select the Guard Model document name from the list. (You need to have created at least one Guard Model document in Adding an LLM model document.)
- Set the Guard model Status field to
Enabled, so that the Domino IQ task gets loaded
on the server.
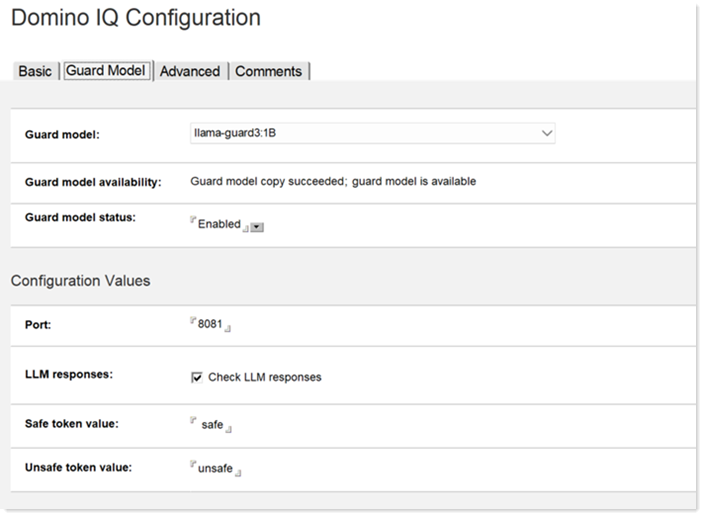
- Select the port number for the AI Inference server started as "localhost" to run on the Domino IQ server. The default port is 8444. Depending on whether you selected Use TLS on the Basic tab, you can choose the port. For example you can choose 8081 if not using TLS, and 8444 if using TLS.
- Select Check LLM responses if you want the Guard
Model to validate both the user content sent to the LLM and the response
content received from the LLM. If you only want to validate the user
content, leave this option unchecked.
- In the Safe token value field, enter the your guard model's predefined keyword for when the content passes safety check. As examples, with LLAMA Guard 3, "safe" indicates that the request content does not fall into any risk categories defined by the model. For ShieldGemma, "No" indicates that the requested content does not violate the policy that the model was trained to protect.
- In the Unsafe token value field, enter your guard model's keyword for when the content doesn't pass the safety check. With LLAMA Guard 3, you would enter "unsafe" or, for ShieldGemma, "Yes".
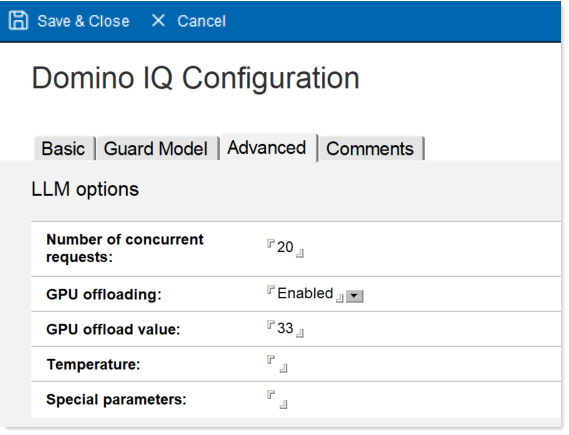
- On the Advanced tab, you can specify the following settings
to automatically build the Domino IQ server launch parameters:
- Set the number of concurrent CPUs
- Enable GPU offloading and the number of layers to offload to GPU.
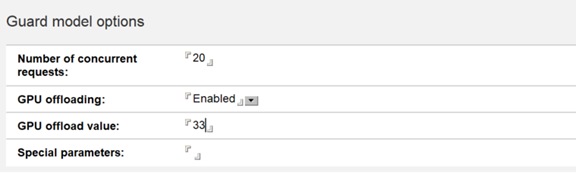
- If you're using a guard model, complete the same fields on the
Guard Model tab.
- Save the document.
What to do next: