Introduction to HA and DR
The objective of this section is to provide the basic concepts needed to structure the top level of your BigFix environment in a way that can help you achieve "business continuity".
We will use those concepts to lay the foundations of a design that can enable your BigFix environment to remain operational in the event of a simple failure and to make it possible to recover its operational capabilities after a disaster.
Objectives and assumptions
A business continuity plan regarding a software infrastructure, like the one formed by the BigFix Platform components, usually involves making the core system capable of "high availability" (HA) and making it possible to perform an effective "disaster recovery" (DR) for it.
Both concerns involve hardware arrangement decisions and software configuration choices and both require a certain degree of infrastructural redundancy. However, each concern aims to solve a slightly different set of issues and has different constraints.
- HA, to maximize uptime by being resilient to the more common issues
- DR, to be able to recover from a catastrophic event, which can cause service interruptions
- both HA and DR
Conceptually, having HA is like being able to replace part of a system without turning it off, while DR is like having a backup in a safe location.
- HA works with low latency and is intended to have no data loss
- DR works with high latency and can admit a degree of data loss
This diagram represents a simplified HA or DR configuration for a BigFix environment.
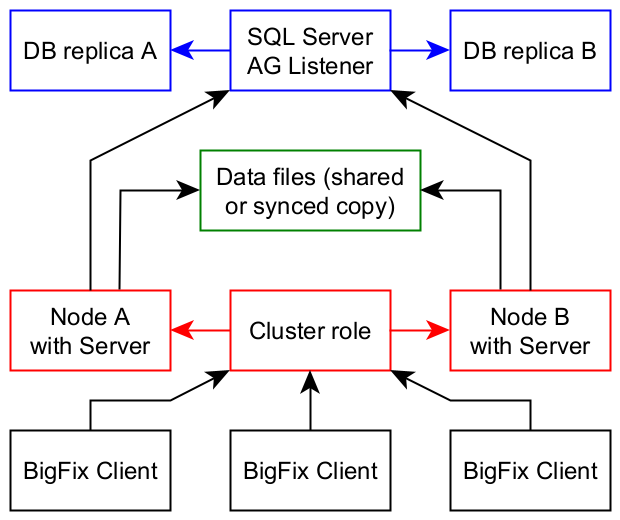
- blue boxes implement database redundancy
- green boxes implement file storage redundancy (optional)
- red boxes implement computer redundancy
An HA environment can be configured to have just database redundancy and computer redundancy, if the data files are shared on a common storage.
A DR environment always needs all three types of redundancy.
Database redundancy
For database redundancy, SQL Server Enterprise edition provides a feature called "Always On availability groups" (AG).
This feature lets you set up an "availability group", which provides redundancy by coordinating two or more "availability replicas". Each availability replica requires its own SQL Server instance and can contain one or more databases.
At any time, one replica acts as the "primary" of the group and the others act as "secondary". To operate on a database, rather than connecting directly to a specific replica, you connect to the availability group, via an "availability listener". An "availability listener" provides its own hostname and a virtual IP to contact the availability group it is associated with. This arrangement makes it possible to work on a database without needing to know what replica is the current primary.
It is possible to configure an availability replica for HA and a different replica for DR.
- "synchronous commit" for HA
- "asynchronous commit" for DR
A database availability replica configured for HA can also be a "readable secondary", to increase performance for read-heavy database operations.
Computer redundancy
For computer redundancy, Windows Server provides a feature called "Windows Server Failover Cluster" (WSFC).
This feature lets you set up a "failover cluster", which provides redundancy by coordinating two or more "cluster nodes". Each cluster node is a Windows Server computer that was added to the same failover cluster. All computers that are part of the same failover cluster must be part of the same Active Directory domain.
In a failover cluster, cluster nodes take turns in providing a specific service, or running a certain operation. At any time, a single cluster node will be the "owner node" of a specific "cluster role". In the context of a WSFC, a "cluster role" is a set of resources needed by a computer to provide a specific service. A different cluster node can become the new owner of a cluster role if that role is "moved" to it, or if a "failover" happens. Usually, a role is manually moved off its owner node to perform maintenance on that computer, while a failover is performed automatically when a potential problem is detected.
A cluster role can be assigned its own hostname and virtual IP. Other resources can be applications installed on the cluster nodes. For example, a cluster role can consist of a Windows service running a program that acts as an HTTPS server, a new own hostname and a virtual IP. This arrangement makes it possible to connect to the HTTPS server via the cluster role hostname or IP, without needing to know on what node it is currently running on.
File storage redundancy
When discussing file storage redundancy, it is useful to distinguish between "program files" and "data files". By "program files" we mean the executable and other files created by a fresh installation. By "data files" we mean the files that the program creates or operates on.
A simple solution to achieve redundancy of the program files could be installing the same version of that program on several computers. To keep consistency, this solution would require upgrading all installations together or in rapid succession.
For data files, depending on your needs, full redundancy might not be necessary. You can configure an environment that achieves HA without having to duplicate your data files by placing them on a "shared storage" where your program can find always them, independently of the computer it is running on. In order to be able to perform DR, you can keep an additional copy of your data files on a separate storage at a different location.
Shared file storage
In a failover cluster, you can wrap your program in a cluster role. Only one cluster node can own that role at a time and run it. The other failover cluster nodes can only take over that role when a failover happens and a different computer is chosen as the owner node. If you place your data files on a shared storage, computers that are part of the same failover cluster will only access them one at a time. This arrangement avoids common concurrency issues like deadlocks and race conditions.
For shared file storage, Windows Server provides a feature called "Cluster Shared Volume". This feature enables multiple nodes in a Windows Server failover cluster to simultaneously have read-write access to the same storage volume. This volume can be a reserved space on a disk mounted on a separate computer, which does not have to be a cluster node. If your data files are on a Cluster Shared Volume, a program configured as a cluster role can fail over to a different cluster node and have access to the same data straight away. For more information, see Use Cluster Shared Volumes in a failover cluster.
Synchronized file copy
Having an additional copy of your data files is an important part of being ready to perform DR. It is also a possible way of achieving HA in your environment. Depending on your needs, such a copy can be made by a scheduled backup, or maintained by a continuous process.
You can store additional copies of your data files at different locations and use a synchronization mechanism to update them. For HA, this is optional, but if you choose to implement it this way, your copies must be fully consistent with the original, so you need a fully synchronous file update mechanism. For DR, you do need to have at least an additional copy of your data files, but it can be updated with a slight delay and so the file update mechanism can be asynchronous.
For actual file storage redundancy, Windows Server provides a feature called "Storage Replica". This feature supports several configurations, named "server-to-server", "cluster-to-cluster" and "Stretch Cluster". Each Storage Replica configuration can be set up to act either synchronously or asynchronously. In any case, Storage Replica only support one-to-one replication of a specific volume pair. Storage Replica only supports automatic failover when deployed in a Stretch Cluster configuration. For more information, see Storage Replica overview.
Achieving both HA and DR
You can achieve both HA and DR in several ways. The following is an example.
For HA, you can set up two computers at the same location and make them part of the same failover cluster. Install your program on both of them. Make them use the same database and place your data files on a shared storage within close distance. Create a cluster role and use it to wrap your program. If you program is a server, you can use the role to provide the network resources to contact it independently of the computer it is running on. Use a second SQL Server instance at the same location to implement an availability group for the program database, ensuring both instances act as synchronous replicas. Configure your two computers to access your program database via an availability group listener.
For DR, you can set up a third computer at a different location. Provide it with its own storage and set up a mechanism to asynchronously replicate your data files from the other location to this one. At this different location, use a third SQL Server instance to add an asynchronous replica to the availability group you created for your program database.