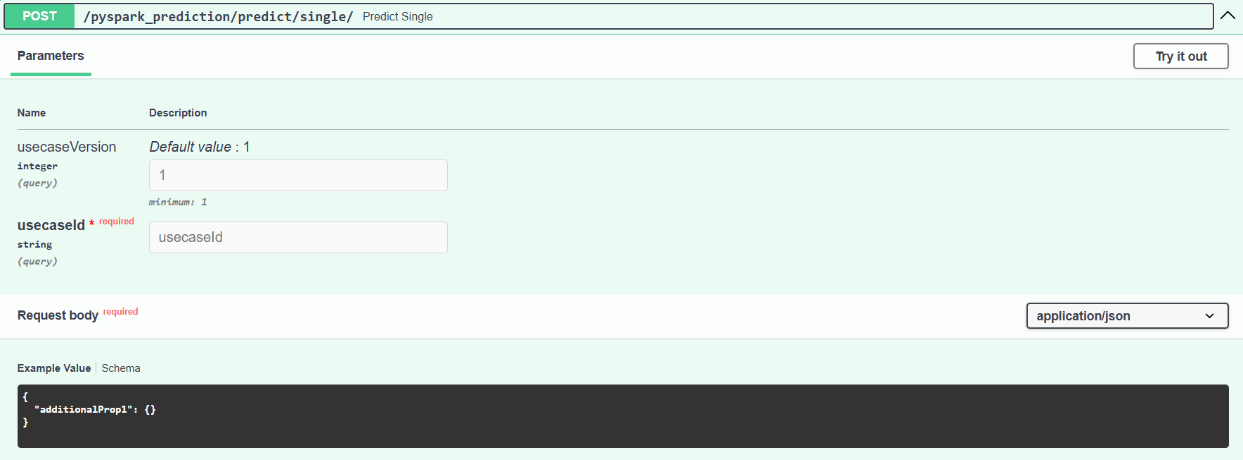
Post: Predict Single
Endpoint: /pyspark_prediction/predict/single/
Executes a single-record prediction using distributed PySpark inference. Suitable for real-time, low-latency use cases.
Input Parameters:
- usecaseId (string, required): Unique identifier for the trained use case/model.
- usecaseVersion (integer, optional): Version of the use case (default:1).
-
Request Body (application/json): JSON object representing the input feature values for a single prediction.
Output:
Returns a JSON object containing the prediction result(s) for the provided input.