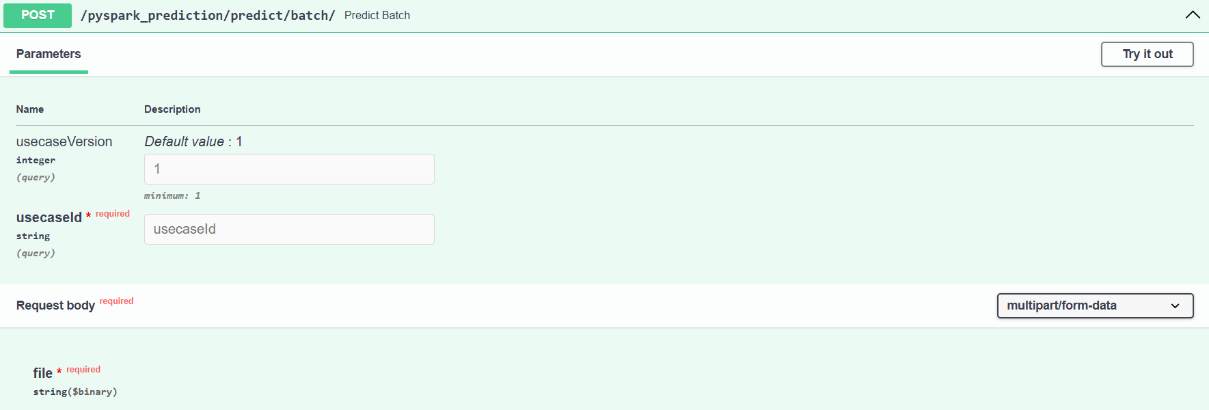
Post: Predict Batch
Endpoint: /pyspark_prediction/predict/batch/
Executes batch prediction in parallel using PySpark for large input datasets. This enables fast inference at scale by distributing processing across Spark workers.
Input Parameters:
- usecaseId (string, required): Unique identifier for the trained use case/model.
- usecaseVersion (integer, optional): Version of the use case (default: 1).
- Request Body (multipart/form-data):
-
file (binary, required): Input CSV or structured file containing feature records for batch prediction.
Output:
Returns a JSON response with a reference to the prediction output file or the results, depending on configuration.
-