HCL Commerce Search performance tuning
Consider these search performance tuning hints and tips when you administer HCL Commerce Search.
When to perform full search index builds
The HCL Commerce Search index is automatically built when certain business tasks are performed, as outlined in Common business tasks and their impact to the HCL Commerce Search index. In several cases, common business tasks result in delta index builds that do not pose a significant risk to production system performance. However, doing several delta index builds without occasional full index builds might result in the search index gradually degrading over time due to fragmentation. To avoid this issue, doing full search index builds when possible ensures that the search index performs well over time.
When Lucene receives a delete request, it does not delete entries from the index, but instead marks them for deletion and adds updated records to the end of the index. This marking results in the catalog unevenly spreading out across different segment data files in the search index, and might result in increased search response times. If you have a dedicated indexing server, consider scheduling a periodic full search index build. Make this build a background task that runs once per month, so that the deleted entries are flushed out, and to optimize the data.
Indexing server
Consider the following factors when you tune the indexing server:
 Index build preprocessor is now using Varchar as field type rather than Clob
Index build preprocessor is now using Varchar as field type rather than Clob- The data type of several columns of the TI_ATTR table were changed from CLOB. The six columns
are now defined as
varchar(32672)in Db2, andvarchar2(32767)for Oracle in the wc-dataimport-preprocess-attribute.xml configuration file. The same change was made in the ATTRIBUTES column of TI_ADATTR. This change reduces the preprocessing time of these two tables. - This change requires that Oracle users enable the "Extended Data Types" feature described in
https://oracle-base.com/articles/12c/extended-data-types-12cR1. If you are migrating from a previous version, ensure that you drop all temporary
tables before proceeding.Note: You must also execute the instruction in bold in this sample, or the Oracle database will not come back online after a restart. You need only execute this instruction once.
CONN / AS SYSDBA SHUTDOWN IMMEDIATE; STARTUP UPGRADE; ALTER SYSTEM SET max_string_size=extended; @?/rdbms/admin/utl32k.sql SHUTDOWN IMMEDIATE; STARTUP;  An x-data-config.xml configuration file is available
that consolidates the parameters that activate CLOB preprocessing. To use CLOB in preprocessing,
uncomment the relevant sections.
An x-data-config.xml configuration file is available
that consolidates the parameters that activate CLOB preprocessing. To use CLOB in preprocessing,
uncomment the relevant sections. 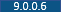 The CopyColumnsDataPreProcessor preprocessor can reduce temporary table
processing time by 50%
The CopyColumnsDataPreProcessor preprocessor can reduce temporary table
processing time by 50%- The preprocessor uses SQL syntax to eliminate unnecessary round-trip communication between Java
and the database. This syntax can take the format:
INSERT INTO <one table> SELECT FROM <another table>.To enable the preprocessor, copy and use the XML files that are provided.- To enable the preprocessor for your CI/CD pipeline, begin by copying the XML files within your
development (toolkit) environment samples folder. Copy the XML files from the
samples/dataimport/copy_columns_data_preprocessor directory within your
development environment to the \WC\xml\search\dataImport directory for your
CI/CD pipeline.Note: In 9.0.1.1, the
samples/dataimport/copy_columns_data_preprocessor folder is deprecated. All
corresponding XML files have a copy in
\WC\xml\search\dataImport\v3\database\CatalogEntry folder
(where database is either
db2| oracle). The fileshave a .copycolumns extension in the toolkit. They are also available in /profile/installedApps/localhost/ts.ear/xml/search/dataImport/v3/database/CatalogEntry in the runtime of the Transaction and Utility server Docker containers. - If you want a quick trial of the preprocessor, copy the XML files from your Utility Docker container to the /profile/installedApps/localhost/ts.ear/xml/search/dataImport directory of your Transaction server Docker Container. You can complete this procedure to test the preprocessor results within your CI/CD pipeline or within a development environment.
The following table lists the XML files that use the CopyColumnsDataPreProcessor preprocessor and the temporary table or tables that each file can optimize.XML file Temporary table wc-dataimport-preprocess-attribute.xml - TI_CATENTREL_#INDEX_SCOPE_TAG#
- TI_ADATTR_#INDEX_SCOPE_TAG#
wc-dataimport-preprocess-catalog.xml - TI_CATALOG_#INDEX_SCOPE_TAG#
- TI_CATALOGI_#INDEX_SCOPE_TAG#
wc-dataimport-preprocess-common.xml - TI_SEOURL_#INDEX_SCOPE_TAG#_#lang_tag#
wc-dataimport-preprocess-direct-parent-catentry.xml - TI_CATGPENREL_#INDEX_SCOPE_TAG#
- TI_DPCATENTRY_#INDEX_SCOPE_TAG#
- TI_GROUPING_#INDEX_SCOPE_TAG#
wc-dataimport-preprocess-direct-parent-catgroup.xml - TI_DPGROUPI_#INDEX_SCOPE_TAG#
- TI_DPGRPNAME_#INDEX_SCOPE_TAG#_#lang_tag#
wc-dataimport-preprocess-fullbuild.xml - TI_CATENTRY_#INDEX_SCOPE_TAG#
wc-dataimport-preprocess-fullbuild-workspace.xml - TI_D_CATENTRY_#INDEX_SCOPE_TAG#
- TI_CATENTRY_#INDEX_SCOPE_TAG#
wc-dataimport-preprocess-offerprice.xml - TI_OFFER_#INDEX_SCOPE_TAG#
wc-dataimport-preprocess-parent-catgroup.xml - TI_APGROUPI_#INDEX_SCOPE_TAG#
wc-dataimport-preprocess-productset.xmlTI_PRODUCTSET_#INDEX_SCOPE_TAG# Important: Before you build an index, ensure that you delete all temporary tables with the exception of the following delta indexing tables:Ensure that you have Tracing enabled. Run the index as usual, and use Trace to determine what performance improvements occurred.
The CopyColumnsDataPreProcessor can rely heavily on database computation. When the preprocessing occurs, you might encounter issues with the processing and see the error "SQLCODE=-964,". This error can occur when you have insufficient log space for the preprocessor. You can run SQL statements against your database to increase the log space.
 The transaction log size in the Db2 database is controlled by LOGFILSIZ and
LOGPRIMARY+LOGSECOND. The following SQL statements provide an example of how to increase the log
space to 4 KB*40000*(20+160)=28.8 GB:
The transaction log size in the Db2 database is controlled by LOGFILSIZ and
LOGPRIMARY+LOGSECOND. The following SQL statements provide an example of how to increase the log
space to 4 KB*40000*(20+160)=28.8 GB:
db2 update db cfg for <dbname> using LOGFILSIZ 40000 db2 update db cfg for <dbname> using LOGPRIMARY 20 db2 update db cfg for <dbname> using LOGSECOND 160 In HCL Commerce version 9.0.1.3,
CopyColumnsDataPreProcessor is used by default for applicable tables in
xml/search/dataImport/v3/db2/CatalogEntry. Note: Tables in old directories (Db2 and Oracle) still use StaticAttributeDataPreProcessor.The transaction log is disabled by default for CopyColumnsDataPreProcessor. The following example XML snippet defines how to disable the transaction log for Db2:
In HCL Commerce version 9.0.1.3,
CopyColumnsDataPreProcessor is used by default for applicable tables in
xml/search/dataImport/v3/db2/CatalogEntry. Note: Tables in old directories (Db2 and Oracle) still use StaticAttributeDataPreProcessor.The transaction log is disabled by default for CopyColumnsDataPreProcessor. The following example XML snippet defines how to disable the transaction log for Db2:
To enable the transaction log for specific CopyColumnsDataPreProcessor, just remove the no_logging_sql property from the configuration. In this example, the no_logging_sql property was removed:<_config:data-processing-config processor="com.ibm.commerce.foundation.dataimport.preprocess.CopyColumnsDataPreProcessor"> <_config:table definition="..." name="..."/> <_config:query sql="..."/> <_config:property name="no_logging_sql" value="alter table #TABLE_NAME# activate not logged initially" /> </_config:data-processing-config><_config:data-processing-config processor="com.ibm.commerce.foundation.dataimport.preprocess.CopyColumnsDataPreProcessor"> <_config:table definition="..." name="..."/> <_config:query sql="..."/> </_config:data-processing-config> - To enable the preprocessor for your CI/CD pipeline, begin by copying the XML files within your
development (toolkit) environment samples folder. Copy the XML files from the
samples/dataimport/copy_columns_data_preprocessor directory within your
development environment to the \WC\xml\search\dataImport directory for your
CI/CD pipeline.
- The CatalogHierarchyDataPreProcessor can improve processing speed when the
fetchSize parameter is specified.
-
In HCL Commerce Version 9.0.0.6, CatalogHierarchyDataPreProcessor is updated to improve performance. This preprocessor, which is enabled by default, is used to inject processed data into the TI_APGROUP temporary table. TI_APGROUP becomes inefficient at large sales catalog numbers because it iterates an internal data structure and issues a query on each iteration. By specifying the fetchsize parameter, you can improve the processing speed of the preprocessor by up to 50%. The fetchsize option is a batch select process that uses
WHERE catentry_idin any(?.?…?)clause.The default fetchSize and batchSize of the preprocessor are each 500. The fetchSize cannot be larger than 32767 for Db2, or 1000 for Oracle.
For example:<_config:data-processing-config processor="com.ibm.commerce.foundation.dataimport.preprocess.CatalogHierarchyDataPreProcessor" masterCatalogId="10101" batchSize="500" fetchSize="1000"> ... </_config:data-processing-config> - The query for the TI_ADATTR temporary table is changed in Version 9.0.0.6+
- During index building, nearly all
rtrim()andcast()calls were removed from the query for the TI_ADATTR temporary table. These calls were redundant for ordinary index builds. The removal of these calls improves the response time of this query against Db2 databases and improves scaling for large numbers of catalog entries. The change for this query is enabled by default when you update to Version 9.0.0.6+. - Search caching for the indexing server
- Typically disable all Solr caches on the indexing server.
- Tuning index buffer size and commit actions during data import (buildindex)
- You can tune your solrconfig.xml file to allocate sufficient memory for
index buffering and prevent commit actions when you are building your index. When the RAM buffer for
index updates is full, Solr performs commit actions that persist data onto disks. When these commit
actions occur, Solr has a global exclusive lock on your entire JVM. This lock prevents other threads
from doing update operations, even when the thread is working on different records or files. This
locking can increase the amount of time that is required to build your index. By increasing your RAM
buffer size, and disabling the commit trigger, you can reduce the chances of this locking. You can
tune your Solr parameters for commit timing and buffer size in the
solrconfig.xml file:
- Allocate more memory for index buffering by changing the value for the
ramBufferSizeMB parameter. 2048 MB is the maximum memory that you can
allocate:
<ramBufferSizeMB>2048</ramBufferSizeMB> - Disable the server-side automatic commit trigger to also reduce occurrence of commit actions by
commenting out the autoCommit
trigger:
<!-- <autoCommit> <maxDocs>10000</maxDocs> <maxTime>1000</maxTime> </autoCommit> -->
- Allocate more memory for index buffering by changing the value for the
ramBufferSizeMB parameter. 2048 MB is the maximum memory that you can
allocate:
- Paging and database heap size configuration
- Ensure that your memory and paging size is configured according to the size of your catalog data
or if your environment contains multiple indexes for different languages. For example, if you are
having issues with accessing or building large amounts of index data:
- Increase the default paging size for your operating system. For example,
3 GB. In cases where the operating system requires a higher paging size, adding more memory to the system also helps to resolve issues. - Increase the default database heap size to a larger value. For example, increase the Db2 heap
size to
8192. - Increase the file descriptor limit to a higher value. For example: ulimit -n 8192.
- Increase the default paging size for your operating system. For example,
- Heap size configuration
-
Ensure that your HCL Commerce Search heap size is configured according to the size of your catalog data or if your environment contains multiple indexes for different languages. For example, if you are having issues with accessing large amounts of index data, increase the default heap size to a larger value such as
1280. For more information, see Configuring JVM heap size in WebSphere Liberty .  Shared pool size configuration
Shared pool size configuration- Ensure that the SHARED_POOL_SIZE is configured according to your
environment. Increasing the shared pool size might improve the performance of the index build
process.For example:
ALTER SYSTEM SET SHARED_POOL_SIZE='668M' SCOPE=BOTH - Multithreaded running of SQL query expressions
- Consider enabling multithreading in Db2 to allow for increased performance when you preprocess
the search index.
To do so, set INTRA_PARALLEL=YES in the Db2 DBM configuration. On the DB client side, update the data source property of currentDegree to ANY. The Setting Parallel Processing utility is in di-parallel-process.properties. A sample configuration statement is Database.jdbcURL=jdbc:db2://db:50000/mall:currentDegree=ANY. For more information, see Common IBM Data Server Driver for JDBC and SQLJ properties for Db2 servers.
Search runtime server
Consider the following factors when you tune the search runtime server:
- Caching
-
- Search caching for the runtime production subordinate servers
- The starter configuration that is included in the CatalogEntry
solrconfig.xml file is only designed for a small scale development environment,
such as HCL Commerce Developer.When you redeploy this index configuration to a larger scale system, such as a staging or production system, customize at least the following cache parameters:
- queryResultWindowSize
- queryResultMaxDocsCached
- queryResultCache
- filterCache (Required on the product index when an extension index such as Inventory exists)
- documentCache (Required on the product index when an extension index such as Inventory exists)
The following example demonstrates how to define cache sizes for the Catalog Entry index and its corresponding memory heap space that is required in the JVM:
Sample catalog size:- Catalog size
- 1.8 million entries.
- Total attributes
- 2000
- Total categories
- 10000
- Each product contains
- Twenty attributes.
- Average size of each Catalog Entry
- 10 KB.
Sample calculation:- queryResultWindowSize
- The size of each search result page in the storefront, such as 12 items per page. This result includes two prefetch pages.
- queryResultMaxDocsCached
- For optimal performance, set this value to be the same value as queryResultWindowSize.
- queryResultCache
- The size of each queryResultCache is 4 bytes per docId (int) reference x queryResultWindowSize, for a value of 144 bytes.
- filterCache
- Assume an average search result size to be 5% of the entire catalog size of 1.8 M, or 90,000.
- documentCache
- Assume an average size of each Catalog Entry document to be 10 KB.
As a result, the estimated JVM heap size that is required for each Catalog Entry core is 4.3 GB (1.44 GB + 1.8 GB + 1.0 GB).
- Managing cache sizes to conform to JVM memory
- Ensure that you configure the fieldValueCache of the catalog entry index
core in the solrconfig.xml file. This configuration can prevent out-of-memory
issues by limiting its size to conform to JVM memory.
The cache set size depends on the facets field quantity and catalog size. The cache entry size can roughly be computed by the quantity of catalog entries in the index core, which is then multiplied by 4 bytes. That is, the potential quantity of cache entries equals the quantity of potential facets.
For example, in the solrconfig.xml file:<fieldValueCache class="solr.FastLRUCache" size="300" autowarmCount="128" showItems="32" />Note: The recommendedsolr.FastLRUCachecaching implementation does not have a hard limit to its size. It is useful for caches that have high hit ratios, but might significantly exceed the size value that you set. If you are usingsolr.FastLRUCache, monitor your heap usage during peak periods. If the cache is significantly exceeding its limit, consider changing the fieldValueCache class tosolr.LRUCacheto avoid performance issues or an out-of-memory condition.For more information, see https://https://lucene.apache.org/solr/guide/7_3/query-settings-in-solrconfig.html/solr/guide/6_6/query-settings-in-solrconfig.html.
- Tuning the search relevancy data cache
- Ensure that you tune the search relevancy data cache for your catalog size.Relevance data is stored in the following cache instance:
- services/cache/SearchNavigationDistributedMapCache
Each entry ranges 8 - 10 KB, containing 10 - 20 relevancy fields. The cache instance also contains other types of cache entries. The database is used for every page hit when the cache instance is full, reducing performance.
- Tuning the search data cache for faceted navigation
- The HCL Commerce Search server code uses the WebSphere Dynamic Cache facility to perform caching of database query results. Similar to the data cache used by the main HCL Commerce server, this caching code is referred to as the HCL Commerce Search server data cache.
Adjusting heap space when search product display is enabled
- Allocate approximately 5 MB/category with product sequencing file for product sequencing:
- For Image Facet Override: ~10MB per category with image override file.
- For Sequencing and Image Override: Assuming a baseline of 100,000 products in the category, allocate ~15MB per category with sequencing and image override file. If you are using manual sequencing with many categories, add 1.5 MB per category that is sequenced for each additional 100,000 products.
For example, according to the 15 MB per category estimate, manual sequencing of 200 categories with a catalog size of 100k can use 3 GB of memory. Manual sequencing of the same 200 categories can use 6 GB when the catalog size is 1.1 million. Therefore, the heap space that is allocated per category must be adjusted according to the catalog size.
Facet performance
- Tune the size of the services/cache/SearchNavigationDistributedMapCache cache instance according to the number of categories.
- Tune the size of the services/cache/SearchAttributeDistributedMapCache cache instance according to the number of attribute dictionary facetable attributes.
- Avoid enabling many attribute dictionary faceted navigation attributes in the storefront (Show facets in search results). Avoiding many of these attributes can help avoid Solr out-of-memory issues.
Extension index
- The filterCache and documentCache are required on the product index when an extension index such as Inventory exists in HCL Commerce Search so that the query component functions correctly.
- You can typically disable all other internal Solr caches for the extension index in the search run time.
Configuration options
- Search configuration
- Ensure that you are familiar with the various Solr configuration parameters, Solr Wiki: solrconfig.xml. The documentation contains information for typical
configuration customizations that can potentially increase your search server performance. For
example, if your store contains a high number of categories or contracts, or if your search server
is receiving
Too many boolean clauseserrors, increase the default value for maxBooleanClauses.
Indexing changes and other considerations
- Garbage collection
- The default garbage collector policy for the HCL Commerce JVM is the Generational
Concurrent Garbage Collector. Typically, you do not need to change this garbage
collector policy.You can activate the Generational Concurrent Garbage Collector for the HCL Commerce Search JVM by using the -Xgcpolicy:gencon command line option.Note: Using a garbage collection policy other than the Generational Concurrent Garbage Collector might result in situations with increased request processing times and high CPU utilization.
For more information, see Garbage collection policies.
- Spell checking
- You can experience a performance impact when you enable spell checking for HCL Commerce Search terms.
You might see performance gains in transaction throughput if either spell checking is skipped where necessary, or when users search for products with catalog overrides.
For example, a search term that is submitted in a different language than the storefront requires resources for spell checking. However, product names with catalog overrides are already known and do not require any resources for spell checking.
The spell checker component,
DirectSolrSpellChecker, uses data directly from the CatalogEntry index, instead of relying on a separate stand-alone index. - Improving Store Preview performance for search changes
- To improve performance when you preview search changes, you can skip indexing unstructured
content when business users start Store Preview:
In the wc-component.xml file, set the
IndexUnstructuredproperty tofalse.For more information, see Changing properties in the HCL Commerce configuration file (wc-component.xml).
Performance monitoring
- Lucene Index toolbox (Luke)
- Luke is a development and diagnostic tool for search indexes. It displays and modifies search index content. For more information, see Luke - Lucene Index Toolbox.
- WebSphere Application Server JMX clients
- JMX clients can read runtime statistics from Solr.