Configuring the Data Extract utility business object configuration file
Create a business object configuration file for the Data Extract utility to use to identify business object data to extract. In this file, you must specify the implementation classes for your data reader, business object builder, and business object mediator components.
The business object configuration file defines how to extract data from the database. When you are configuring the components in this file, indicate how the utility is to handle any data that must be converted. For example, configure how the utility is to convert unique ID values to external identifier values. If you load extracted data that includes unique ID values into another instance, the load operation fails if the ID values exist for a different object.
Procedure
-
Go to the following directory, which contains the sample configuration files for extracting
data:

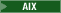 WC_installdir/samples/DataExtract
WC_installdir/samples/DataExtract WC_installdir\samples\DataExtract
WC_installdir\samples\DataExtract WCDE_installdir\samples\DataExtract
WCDE_installdir\samples\DataExtract
- Create a backup of the wc-dataextract-business-object.xml configuration files in the directory and subdirectories for the object that you want to extract, where business-object is the name of the type of object.
-
Open the business object configuration file
(wc-extract-business-object.xml) for the object that you
want to extract.
You must update this file to add or change any of the configuration settings for extracting data.For example, to configure the utility to use the SQL-based data extract process, you must configure how the utility is to retrieve, transform, and output data.
-
Configure the data reader class to be the
com.ibm.commerce.foundation.dataload.datareader.UniqueIdReader class. If you do
not specify this data reader class, you must include a
ColumnMappingorValueHandlerconfiguration within the business object mediator configuration for the utility to use to retrieve data.This data reader class adds support for the utility to use SQL statements to retrieve only the unique ID values for a business object. The
UniqueIdReaderclass returns one ID value for an object at a time to the business object builder. These ID values are then passed as a map object to the business object mediator. The mediator then retrieves the remaining data for the object. The key for the map is the column name that is included in the select SQL statement and the value is the value that is retrieved from the database for the column. The UniqueIdReader data reader can send multiple map objects to the business object builder.If you need to extract custom data or data that is not supported for the utility by default, you can include a query element to indicate how the utility is to retrieve the data. If you include a query element in your data reader configuration, your SQL statement should return a list of ID values. An ID value can include multiple columns, but the value cannot be null. Although you can configure multiple queries in your XSD schema definition, the utility uses the first query only. If you do not configure any queries in your XSD schema definition, the utility does not extract any data
Note: The UniqueIdReader does not use anyColumnMappingorValueHandlerconfiguration.The following code is a sample data reader configuration. This configuration sets the data reader to be theUniqueIdReaderclass and includes a query element.
The query element<_config:DataReader className="com.ibm.commerce.foundation.dataload.datareader.UniqueIdReader" > <_config:Query> <_config:SQL> <![CDATA[ SELECT CATGROUP.CATGROUP_ID FROM CATGROUP JOIN STORECGRP ON (CATGROUP.CATGROUP_ID = STORECGRP.CATGROUP_ID AND STORECGRP.STOREENT_ID = ?) LEFT OUTER JOIN CATGRPDESC ON (CATGRPDESC.CATGROUP_ID = CATGROUP.CATGROUP_ID AND CATGRPDESC.LANGUAGE_ID = ?) WHERE CATGRPDESC.PUBLISHED = 1 AND CATGROUP.MARKFORDELETE = 0 ORDER BY CATGROUP.CATGROUP_ID ]]> </_config:SQL> <_config:Param name="storeId" valueFrom="BusinessContext" /> <_config:Param name="langId" valueFrom="BusinessContext" /> </_config:Query> </_config:DataReader><_config:Query>includes an SQL statement and configurable parameters. If you include any configurable parameters, the number of parameters must match the number of question mark variables within your SQL statement. If the numbers do not match, an exception is thrown. -
Configure the business object mediator class.
- If you are extracting promotions data, set the class to be the com.ibm.commerce.promotion.dataload.mediator.PromotionToDomTransformMediator class. The utility uses the PromotionToDomTransformMediator mediator to retrieve promotion data from the database and build a DOM object for the promotions. The DOM object is then passed to the data writer, which generates the output XML file that includes the extracted data. To build the DOM object, the mediator can replace some primary key values (for example, for categories, catalog entries, customer segments) with the corresponding unique identifier value. The utility outputs the identifier value instead of the unique ID, since the unique ID can be different between environments. When you load the XML into a store with the Data Load utility, the utility resolves the unique ID for the promotions from the identifier value.
- If you are extracting marketing or Commerce Composer data, set the class to be the com.ibm.commerce.foundation.dataload.businessobjectmediator.AssociatedObjectMediator class. The AssociatedObjectMediator business object mediator adds support for the utility to use SQL statements to retrieve the detailed business object information for a map object. The mediator can then send an updated map object that contains the detailed business object information to the configured data writer class. The key for this map object is the configured column name mappings. The value is the value that is retrieved for the corresponding database column.
To retrieve the detailed business object information for an object, the AssociatedObjectMediator mediator uses one or more query elements. Each query element includes an SQL statement to retrieve data. These statements use the ID values from the map object that the business object builder passed to the mediator. The ID values are used as the parameter values in the SQL statement to retrieve the detailed information for a map object. If you include any configurable parameters in your SQL statement, the number of parameters must match the number of question mark variables within your SQL statement. If the numbers do not match, an exception is thrown. When the mediator uses the query, the mediator returns only the first record that is found with the configured SQL statements. This record is then included in the map object that is sent to the data writer class.Note: If your SQL is returning multiple records, you might need to refine your SQL to ensure that the mediator is retrieving the correct record.When you are configuring the AssociatedObjectMediator mediator, you can also include a column mapping for each column in the SQL statement. You can use the mapping to convert the database column name to a more readable name that matches the column or element name in the output file. If you do not include a column mapping, the database column name is used in the key of the map object that is sent to the data writer. The database column name is always in uppercase characters.
Note: If you are selecting data from multiple tables, some columns can have the same database column name. You must use SQL to rename the duplicate column names for the extraction process. For example,SELECT IDENTIFIER AS PARENT_IDENTIFIER. Then, you can define the column mapping for thePARENT_IDENTIFIERcolumn.If you defined multiple query elements, the mediator creates a map object for each query and then merges the map objects. If the mediator encounters duplicate column names across the queries, the column value from the latest query added to the map object overwrites the value of the column from the query previous added to the map object.
For example, the following code is a sample business object mediator configuration that includes column mappings and an SQL statement with replacement parameters.<_config:Query> <_config:SQL> <![CDATA[ SELECT IDENTIFIER,NAME,SHORTDESCRIPTION,LONGDESCRIPTION,THUMBNAIL,FULLIMAGE,KEYWORD FROM CATGROUP LEFT OUTER JOIN CATGRPDESC ON (CATGROUP.CATGROUP_ID = CATGRPDESC.CATGROUP_ID AND LANGUAGE_ID = ?) WHERE CATGROUP.CATGROUP_ID in (?) ]]> </_config:SQL> <_config:Param name="langId" valueFrom="BusinessContext" /> <_config:Param name="CATGROUP_ID" /> <_config:ColumnMapping name="IDENTIFIER" value="GroupIdentifier" /> <_config:ColumnMapping name="NAME" value="Name" /> <_config:ColumnMapping name="SHORTDESCRIPTION" value="ShortDescription" /> <_config:ColumnMapping name="LONGDESCRIPTION" value="LongDescription" /> <_config:ColumnMapping name="THUMBNAIL" value="Thumbnail" /> <_config:ColumnMapping name="FULLIMAGE" value="FullImage" /> <_config:ColumnMapping name="KEYWORD" value="Keyword" /> </_config:Query> -
Configure the data writer for the utility to specify whether the utility is to output data in a
CSV or XML formatted file.
Set the data writer class to be one of the following classes:
- com.ibm.commerce.foundation.dataload.datawriter.CSVWriter
-
When you configure the Data Extract utility to use the CSVWriter data writer, the utility outputs extracted data into CSV formatted output files. This data writer causes the utility to take a map object from the business object mediator and write the object within a single row in the generated output file. You can configure the utility to use this data writer, by editing the
<_config:DataWriter>configurable property within the business object configuration file. For example, the following code is a sample configuration that configures the utility to use the CSVWriter data writer:
When you configure the utility to use this data writer, the utility includes the names for each<_config:DataWriter className="com.ibm.commerce.foundation.dataload.datawriter.CSVWriter"> <_config:Data> <_config:column number="1" name="GroupIdentifier" /> <_config:column number="2" name="TopGroup" /> <_config:column number="3" name="ParentGroupIdentifier" /> <_config:column number="4" name="Sequence" /> <_config:column number="5" name="Name" /> <_config:column number="6" name="ShortDescription" /> <_config:column number="7" name="LongDescription" /> <_config:column number="8" name="Thumbnail" /> <_config:column number="9" name="FullImage" /> <_config:column number="10" name="Keyword" /> </_config:Data> </_config:DataWriter><_config:column>configurable property as the column headings in the CSV output file. For each<_config:column>configurable property, you can include the following configurable optional attributes to preconfigure a column value for each map object that is written to the output file.value- Sets a specific column value for each map object that is written to the output file.
valueFrom- Indicates where the utility is to retrieve the value for the column. You can set the value for
the attribute to one of the following values:
Fixed- The value that is specified for the
valueattribute is used as the column value for each map object that is written to the output file. CurrentTimestamp- The column value is current timestamp, which is written in a
java.sql.Timestampstring format.
valueandvalueFromattributes are not included, the utility outputs the value for a column from the map object that is passed to data writer from the business object mediator.When the utility generates a CSV output file, the file includes the following properties:- The file encoding is
UTF-8. - The line terminator is UNIX style line terminator
'\n'. - The token separator is the comma
','character. - The token value delimiter is the double
"quote character. Use this delimiter when the token includes some special characters, such as a comma character, a new line character, or a double quotation mark character.
When you configure the utility to use the CSVWriter data writer you can configure one or more of the following optional properties for the data writer, in addition to the column-value specific configurable attributes:firstTwoLinesAreHeader- Configures the generated CSV output files to include two lines of header information. The first
line includes the keyword for the type of business object that is included in the file. The second
line includes the column headings. You can include the following values for this property:
true- The CSV files include two lines of header information.
false- The CSV files do not include two lines of header information. This value is the default value.
firstLineIsHeader- Configures the generated CSV output files to include the column heading as a line of header
information. You can include the following values for this property:
true- The CSV files include the column headings as a header line.
false- The CSV files do not include a line of header information. This value is the default value.
false, the generated CSV output file does not include any header information. The files include only the data records. If you include both properties set totrue, the generated CSV output files include two lines of header information.trimColumns- Removes trailing whitespace for the values of the configured list of CSV column names. Separate the column names in the list by using a comma character. For each column in the list, the trailing white space for the column value is trimmed. Consider including this property for columns with a column type CHAR. When the column value for this type of column includes whitespace, the whitespace is included in the output file. The whitespace for any column that is not in this configured list is not affected.
replaceLineTerminator- Configures the utility to replace any line terminators, such as
"\n"or"\r\n"new line characters, with a space character. You can include the following values for this property:true- The utility replaces the line terminators. This value is the default value.
false- Line terminators are not replaced.
timestampPattern- Defines the timestamp format to use. If you use the
timestampColumnsconfigurable property, you might need to use this property. By default, the format"yyyy-mm-dd hh:mm:ss"is used. timestampColumns- Configures a list of columns that are to include a specific timestamp value. This value in the
format that is defined for the
timestampPatternproperty. Separate the column names in the list by using a comma character. If a column has the configurable attributevalueFrom="CurrentTimestamp", you do not need to include the column in this list. The mediator assumes that this column is a timestamp and always applies the configuredtimestampPattern.
- com.ibm.commerce.foundation.dataload.datawriter.XmlWriter
-
When you configure the Data Extract utility to use the XmlWriter data writer, the utility outputs extracted data into XML formatted output files. This data writer causes the utility to take a map object from the business object mediator and write the object within a single XML element in the generated output file. You can configure the utility to use this data writer, by editing the
<_config:DataWriter>configurable property within the business object configuration file. For example, the following code is a sample configuration that configures the utility to use the XmlWriter data writer:
When you configure the utility to use the XmlWriter data writer you can configure one or more of the following optional properties for the data writer:<_config:DataWriter className="com.ibm.commerce.foundation.dataload.datawriter.XmlWriter"> <_config:property name="rootElementName" value="CataloagGroups" /> <_config:property name="elementName" value="CataloagGroup" /> <_config:property name="indent" value="true" /> <_config:property name="indentAmount" value="2" /> </_config:DataWriter>rootElementName- The root XML element name in the output XML file. The default element name is
"
root". elementName- The element name for each business object that the utility extracts. The default name is
"
elementName". indent- Indicates whether the XML in the generated output file is to be formatted. You can set the
following values for this property:
true- The XML is formatted within the output file.
false- The XML is not formatted. This value is the default value.
indentAmount- Indicates the number of spaces that each element is indented from the parent element.
nvpToAttribute- Indicates whether each name-value pair in a map object is written to the output file as a
subelement or as an attribute for the object element. You can set the following values for this property:
true- Each name-value pair is included as an attribute of the element.
false- Each name-value pair is included as a subelement of the element within the output file. This value is the default value.
Note: To generate XML output files, you must also configure the extract order configuration file to specify an XML file name extension for each output file to be generated. - com.ibm.commerce.foundation.dataload.datawriter.DomXmlWriter
- Use this class when you are extracting promotions data. The utility uses this class to generate the promotion XML within an output file based on the DOM object that is passed from the business object mediator. The generated promotion XML format is different from the promotion runtime XML. The generated promotion XML format is similar to the promotion authoring XML. The generated output XML differs from the authoring XML in that during the extraction process, the Data Extract utility replaces some primary key values (for example, for categories, catalog entries, customer segments) with the corresponding unique identifier value. The utility outputs the identifier value instead of the unique ID, since the unique ID can be different between environments. When you load the XML into a store with the Data Load utility, the utility resolves the unique ID for the promotions from the identifier value.
-
Configure any value handler configurations for the database columns that you are extracting.
Set the class for the value handler configuration to be the
com.ibm.commerce.foundation.dataload.config.ResolveValueBasedOnSQLHandler
class.
This class provides a customization point that you can use when the utility cannot retrieve data directly from the database or when when you need to modify data before the data writer class writes the data into the output file.For example, if you plan to load the data into another WebSphere Commerce instance. When you extract data from these columns to load into another WebSphere Commerce instance, you need the identifier (external key) value, not the unique ID values. The value handler configuration indicates how the mediator can retrieve the identifier value to replace the unique ID values that were passed to the mediator in the map object from the business object builder.
Each column mapping that you include in the business object mediator configuration can include the
<_config:ValueHandlerconfigurable property. Include a value handler configuration when you need to modify the value that the mediator retrieves from the database. You can also include a value handler configurable property for a parameter element configuration in the SQL statement that is used by the business object mediator.To include a value handler configuration, you also need to identify where the value is retrieved from by included the following configurable attributes.value- Specifies the value to use for the column. This value can be a specific value or it can be the SQL for retrieving the column value.
valueFrom- Indicates where the utility is to retrieve the value for the column. You can set the value for
the attribute to one of the following values:
Fixed- The value that is specified for the
valueattribute is used as the column value. CurrentTimestamp- The column value is current timestamp, which is written in a
java.sql.Timestampstring format.
For example, the following code is a sample business object mediator configuration that includes a value handler configuration for the CONTENT column.<_config:ColumnMapping name="CONTENTTYPE" value="contentType" /> <_config:ColumnMapping name="CONTENT" value="content" > <_config:ValueHandler className="com.ibm.commerce.foundation.dataload.config.ResolveValueBasedOnSQLHandler" > <_config:Parameter name="sqlBasedOnKey" value="contentType" valueFrom="Fixed" /> <_config:Parameter name="CatalogEntry" value="SELECT PARTNUMBER FROM CATENTRY WHERE CATENTRY.CATENTRY_ID = ?" valueFrom="Fixed" /> <_config:Parameter name="CatalogGroup" value="SELECT IDENTIFIER FROM CATGROUP WHERE CATGROUP_ID = ?" valueFrom="Fixed" /> <_config:Parameter name="MarketingContent" value="SELECT NAME FROM COLLATERAL WHERE COLLATERAL_ID = ?" valueFrom="Fixed" /> </_config:ValueHandler> </_config:ColumnMapping>