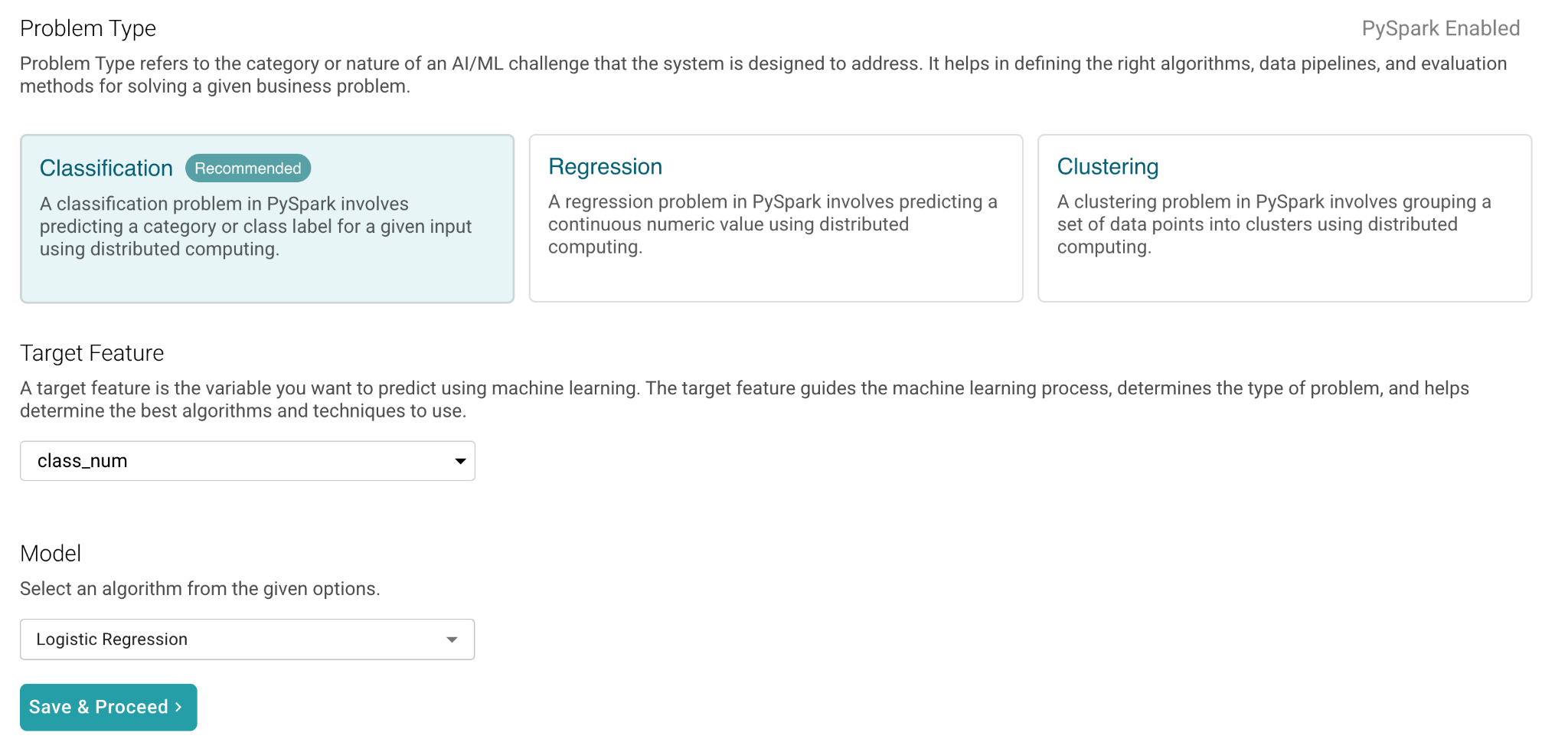
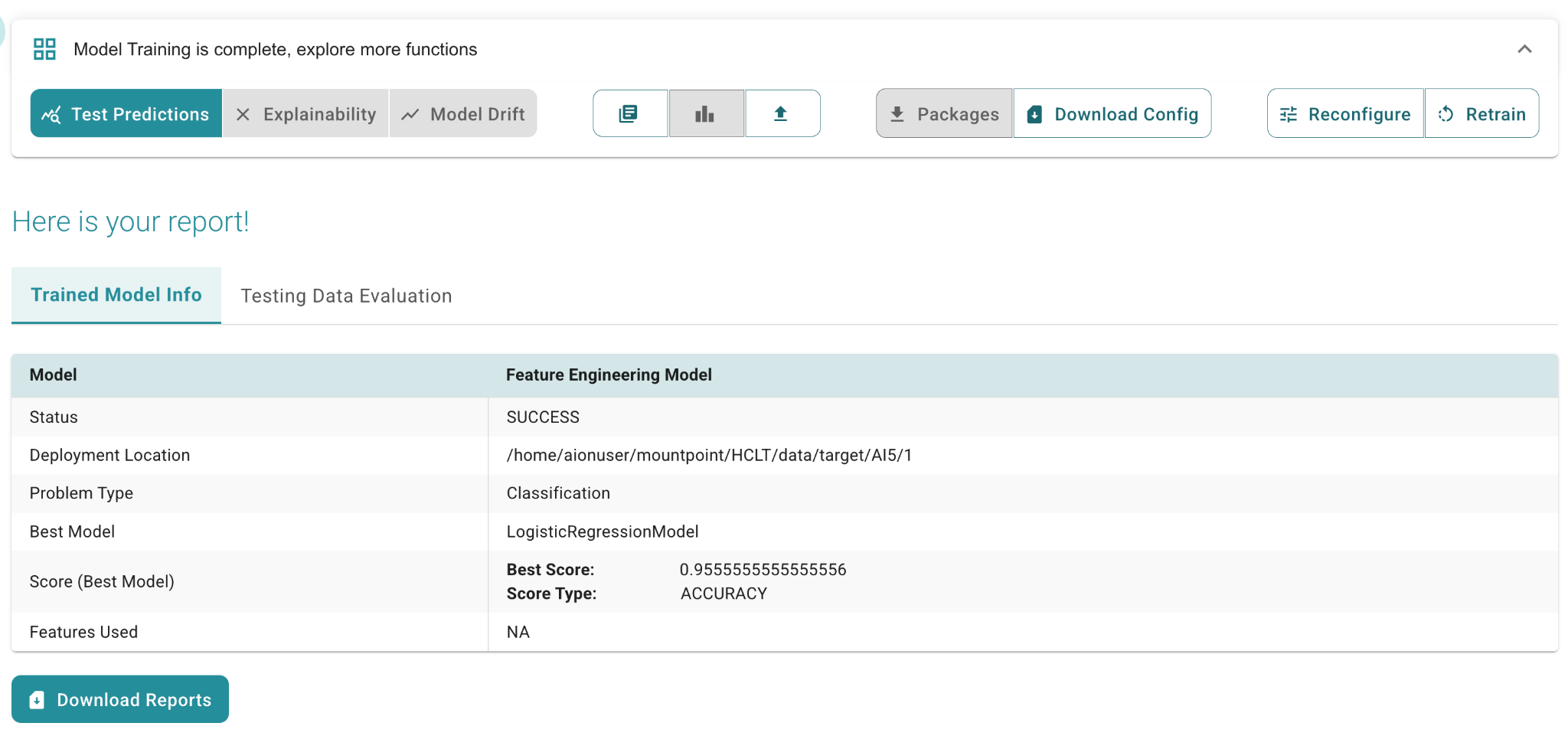
Scalable AI (PySpark)
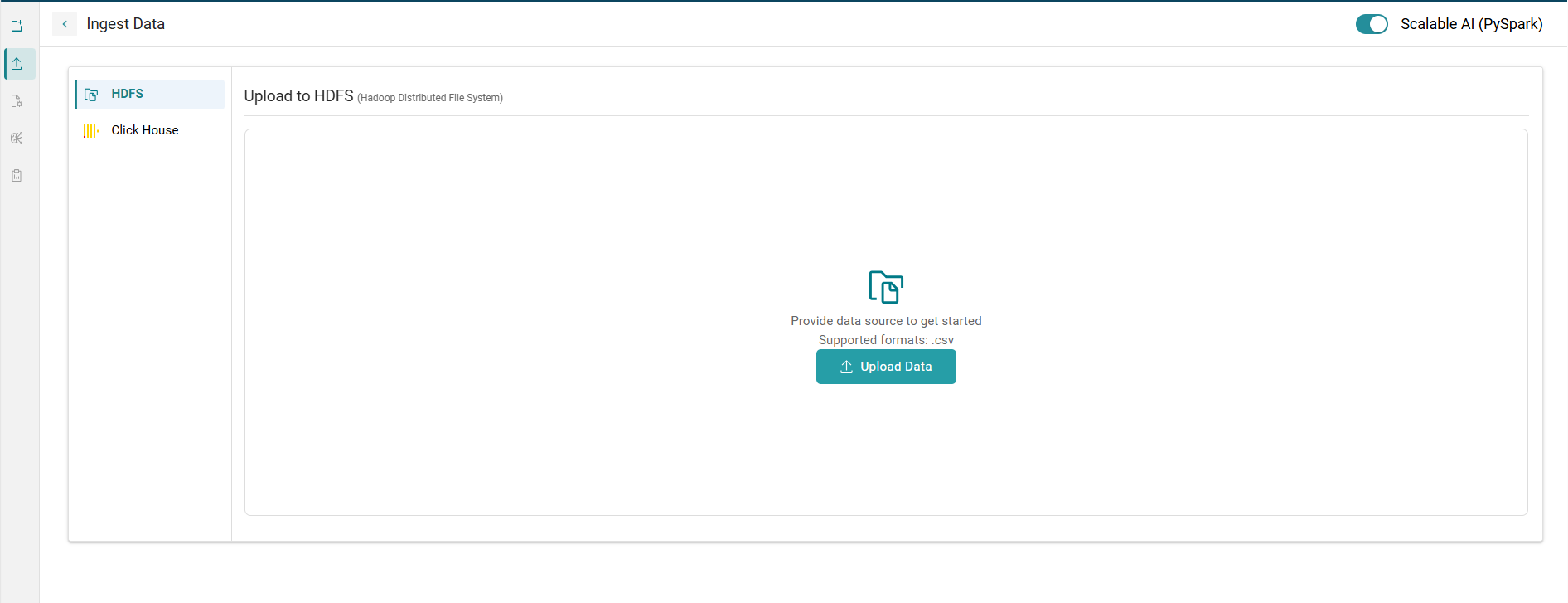
PySpark integration in AION brings the power of Apache Spark’s distributed computing to AI workflows, enabling seamless handling of large datasets (up to 1.5–2 GB). By distributing tasks across multiple compute nodes, it significantly accelerates data processing, making AION ideal for big data use cases. This mode supports problem types such as Classification, Regression, and Clustering, and works seamlessly with data sources like HDFS and ClickHouse.

Distributed PySpark training leverages Spark-Hadoop clusters to parallelize model learning across large datasets. This enables scalable machine learning workflows optimized for big data environments. PySpark prediction runs ML inference in parallel across Spark workers, scaling predictions over massive datasets. It supports low-latency, distributed prediction pipelines integrated with Hadoop.