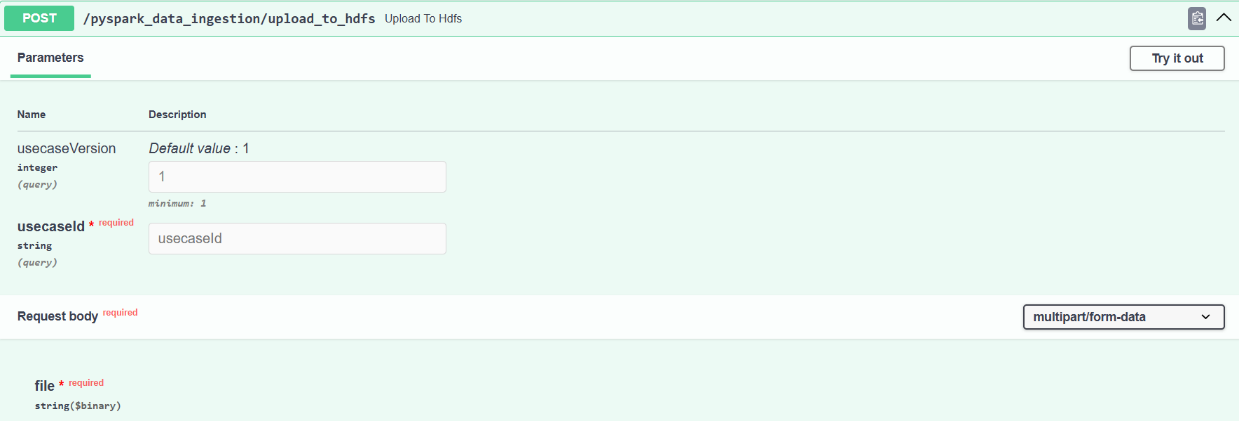
Post: Upload To Hdfs
Endpoint: /pyspark_data_ingestion/upload_to_hdfs
Uploads data files directly to HDFS for use case-specific training or processing.
Input Parameters:
- usecaseId (string, required): Unique identifier for the dataset/use case
- usecaseVersion (integer, optional): Version of the use case (default: 1)
- file (binary, required): File to be uploaded to HDFS
Output:
Returns a confirmation of successful file upload or an error message in JSON format.