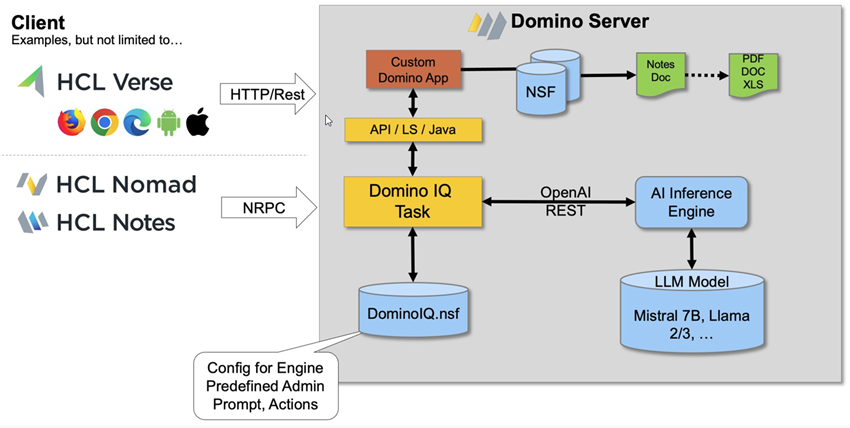
Domino IQ
Domino 14.5 adds support for running an AI inference engine in the Domino backend.
The Domino server, when configured for Domino IQ, starts an inference engine from the Dbserver process. The AI engine runs locally, listening on the configured port alongside core Domino server processes - and handles AI queries locally within the Domino server.
With this feature, two new LotusScript classes, NotesLLMRequest and NotesLLMResponse, are available to send generative AI queries to a Domino server and retrieve responses back from the server.
Requirements
The Domino IQ server needs a pre-trained data model known as a large language model (LLM) to be hosted on the Domino server's data directory. Currently the only way that each Domino IQ server can run the AI inference server is with a single LLM (model). These pre-trained data models must be in GGUF binary format, as described in this GGUF specification.
Domino IQ server can use NVIDIA CUDA-built AI inferencing server components that work only with Windows or Linux servers running with NVIDIA GPU hardware. Domino IQ server components are CUDA-enabled and built with the NVIDIA 12.x Toolkit, which specifies the compatible NVIDIA GPU drivers for Windows and Linux Domino servers.
The NVIDIA CUDA Toolkit Release Notes on the CUDA website details the minimum required OS NVIDIA driver versions needed to run Domino IQ server. See the table "CUDA Toolkit and Minimum Required Driver Version for CUDA Minor Version Compatibility" in the "CUDA Driver" section of that document.
The server requires a minimum of 4 CPUs and 8 GB RAM. We recommend NVIDIA GPU with a minimum of 8 GB memory and compute capability of 5.2 or higher (8.0 or higher for production loads). On Windows servers, Domino IQ server is able to use both GPU memory and half of system RAM, which is treated as Shared RAM . Based on the size/number of parameters in the LLM model being used, the memory required for loading the model varies.